Tag Archives: Big Data
Join Rittman Mead at the 2017 BIWA Summit!

We invite you to come join us at the annual 2017 BIWA Summit.

This year we are proud to announce that Robin Moffatt, Head of Research and Development, will be presenting on:
Analysing the Panama Papers with Oracle Big Data Spatial and Graph
January 31, 2017 | 3:45 pm – 4:15 pm | Room 103
Oracle Big Data Spatial and Graph enables the analysis of datasets beyond that of standard relational analytics commonly used. Through Graph technology relationships can be identified that may not otherwise have been. This has practical uses including in product recommendations, social network analysis, and fraud detection. In this presentation we will see a practical demonstration of Oracle Big Data Spatial and Graph to load and analyse the “Panama Papers” dataset. Graph algorithms will be utilised to identify key actors and organisations within the data, and patterns of relationships shown. This practical example of using the tool will give attendees a clear idea of the functionality of the tool and how it could be used within their own organisation. If Oracle Database 12cR2 on-premise is available by the time of this presentation, then its new property graph capabilities will also be covered here. The presentation will be based on a paper published on OTN: https://community.oracle.com/docs/DOC-1006400
Kafka’s Role in Implementing Oracle’s Big Data Reference Architecture on the Big Data Appliance
February 1, 2017 | 2:20 pm – 3:10 pm | Room 102
Big Data … Big Mess? Everyone wants Big Data, but without a good platform design up front there is the risk of a mess of point-to-point feeds. The solution to this is Apache Kafka, which enables stream or batch consumption of the data by multiple consumers. Implemented as part of Oracle’s Big Data Architecture on the Big Data Appliance, it acts as a data bus for the enterprise to both the data reservoir and discovery lab. This presentation will introduce the basics of Kafka, and explain how it fits within the Big Data Architecture. We’ll then see it used with Oracle GoldenGate to stream data into the data reservoir, as well as ad hoc population of discovery lab environments and microservices such as Flume, HBase, and Elasticsearch.
(Still) No Silver Bullets: OBIEE 12c Performance in the Real World
February 2, 2017 | 1:30 pm – 2:20 pm | Room 203
Are you involved in the design and development of OBIEE systems and want to know the best way to go about ensuring good performance? Maybe you’ve an existing OBIEE system with performance “challenges” that you need to diagnose? This presentation looks at the practical elements of diagnosing the causes of performance issues in OBIEE, and discusses good practices to observe when developing new systems. It includes discussion of OBIEE 12c and with additional emphasis on analysis of Usage Tracking data for the accurate profiling and diagnosis of issues. Why this would appeal to the audience: – Method-R time profiling technique applied to the OBIEE nqquery.log – Large number of the community use OBIEE, many will have their own performance horror stories; fewer will have done a deep dive into analysing the time profile of long-running requests – Performance “right practices” will help those less familiar with performant OBIEE designs, and may prompt debate from those more experienced. As presented previously at OOW, OUGF, UKOUG, OUG Scotland, and POUG. Newly updated for OBIEE 12c. * Video: http://ritt.md/silver-bullets-video* Slides: http://ritt.md/silver-bullets-slides
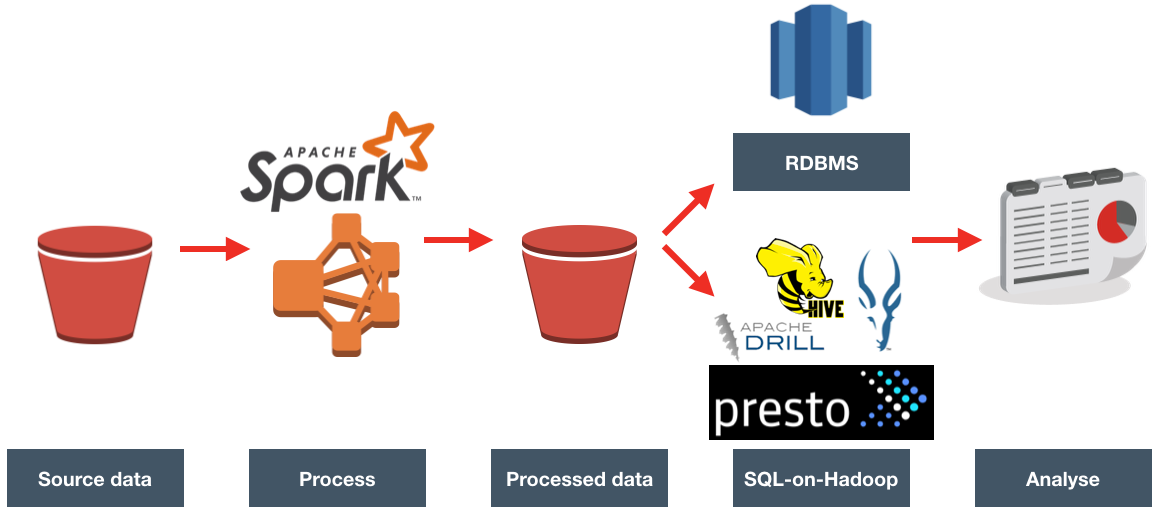
ETL Offload with Spark and Amazon EMR – Part 1
We recently undertook a two-week Proof of Concept exercise for a client, evaluating whether their existing ETL processing could be done faster and more cheaply using Spark. They were also interested in whether something like Redshift would provide a suitable data warehouse platform for them. In this series of blog articles I will look at how we did this, and what we found.
Background
The client has an existing analytics architecture based primarily around Oracle database, Oracle Data Integrator (ODI), Oracle GoldenGate, and Oracle Business Intelligence Enterprise Edition (OBIEE), all running on Amazon EC2. The larger architecture in the organisation is all AWS based too.
Existing ETL processing for the system in question is done using ODI, loading data daily into a partitioned Oracle table, with OBIEE providing the reporting interface.
There were two aspects to the investigation that we did:
Primarily, what would an alternative platform for the ETL look like? With lots of coverage recently of the concept of "ETL offloading" and "Apache-based ETL", the client was keen to understand how they might take advantage of this
Within this, key considerations were:
- Cost
- Scalability
- Maintenance
- Fit with existing and future architectures
The second aspect was to investigate whether the performance of the existing reporting could be improved. Despite having data for multiple years in Oracle, queries were too slow to provide information other than within a period of a few days.
Oracle licenses were a sensitive point for the client, who were keen to reduce - or at least, avoid increased - costs. ODI for Big Data requires additional licence, and so was not in scope for the initial investigation.
Data and Processing
The client uses their data to report on the level of requests for different products, including questions such as:
- How many requests were there per day?
- How many requests per product type in a given period?
- For a given product, how many requests were there, from which country?
Data volumes were approximately 50MB, arriving in batch files every hour. Reporting requirements were previous day and before only. Being able to see data intra-day would be a bonus but was not a requirement.
High Level Approach
Since the client already uses Amazon Web Services (AWS) for all its infrastructure, it made sense to remain in the AWS realm for the first round of investigation. We broke the overall requirement down into pieces, so as to understand (a) the most appropriate tool at each point and (b) the toolset with best overall fit. A very useful reference for an Amazon-based big data design is the presentation Big Data Architectural Patterns and Best Practices on AWS. Even if you're not running on AWS, the presentation has some useful pointers for things like where to be storing your data based on volumes, frequency of access, etc.
Data Ingest
The starting point for the data was Amazon's storage service - S3, in which the data files in CSV format are landed by an external process every hour.
Processing (Compute)
Currently the processing is done by loading the external data into a partitioned Oracle table, and resolving dimension joins and de-duplication at query time.
Taking away any assumptions, other than a focus on 'new' technologies (and a bias towards AWS where appropriate), we considered:
- Switch out Oracle for Redshift, and resolve the joins and de-duplication there
- Loading the data to Redshift would be easy, but would be switching one RDBMS-based solution for another. Part of the aim of the exercise was to review a broader solution landscape than this.
Use Hadoop-based processing, running on Elastic Map Reduce (EMR):
- Hive QL to process the data on S3 (or HDFS on EMR)
- Not investigated, because provides none of the error handling etc that Spark would, and Spark has SparkSQL for any work that needs doing in SQL.
- Pig
- Still used, but 'old' technology, somewhat esoteric language, and superseded by Spark
- Spark
- Support for several languages including commonly-used ones such as Python
- Gaining increasing levels of adoption in the industry
- Opens up rich eco-system of processing possibilities with related projects such as Machine Learning, and Graph.
- Hive QL to process the data on S3 (or HDFS on EMR)
We opted to use Spark to process the files, joining them to the reference data, and carrying out de-duplication. For a great background and discussion on Spark and its current place in data architectures, have a listen to this podcast.
Storage
The output from Spark was written back to S3.
Analytics
With the processed data in S3, we evaluated two options here:
- Load it to Redshift for query
- Query in-place with a SQL-on-Hadoop engine such as Presto or Impala
- With the data at rest on S3, Amazon's Athena is also of interest here, but was released after we carried out this particular investigation.
The presumption was that OBIEE would continue to provide the front-end to the analytics. Oracle's Data Visualization Desktop tool was also of interest.
In the next post we'll see the development environment that we used for prototyping. Stay tuned!
Using logdump to Troubleshoot the Oracle GoldenGate for Big Data Kafka handler
Oracle GoldenGate for Big Data (OGG BD) supports sending transactions as messages to Kafka topics, both through the native Oracle handler as well as a connector into Confluent's Kafka Connect. In some research that I was doing with it I found an interesting problem that I am going to demonstrate here and show the troubleshooting tools that may be useful to others encountering similar issues.
The source for the data is Swingbench running against Oracle 12c database (pluggable instance). OGG has been configured as follows:
Extract
EXTRACT EXT1 USERID SYSTEM, PASSWORD welcome1 EXTTRAIL ./dirdat/lt SOURCECATALOG ORCL TABLE SOE.*;Datapump (to local machine, an installation of OGG BD)
EXTRACT EXTDP1 RMTHOST LOCALHOST, MGRPORT 7810 RMTTRAIL ./dirdat/rt SOURCECATALOG ORCL TABLE SOE.*;Replicat
REPLICAT rkafka TARGETDB LIBFILE libggjava.so SET property=dirprm/kafka.props REPORTCOUNT EVERY 1 MINUTES, RATE GROUPTRANSOPS 10000 MAP *.*.*, TARGET *.*.*;
When I start the replicat, it abends almost straight away. In ggserr.log I see:
ERROR OGG-15051 Oracle GoldenGate Delivery, rkafka.prm: Java or JNI exception:
oracle.goldengate.util.GGException: Kafka Handler failed to format and process operation: table=[ORCL.SOE.CUSTOMERS], op pos=00000000000000006636, tx pos=00000000000000002437, op ts=2016-09-06 10:59:23.000589.
ERROR OGG-01668 Oracle GoldenGate Delivery, rkafka.prm: PROCESS ABENDING.
Within the properties file for the Kafka handler (dirprm/kafka.props) I increased the logging level
gg.log.level=DEBUG
and restart the replicat. Now we get a debug file written to dirrpt/RKAFKA_debug_log4j.log which includes successful work:
[...]
[main] DEBUG (UserExitDataSource.java:1190) - Received txInd is: WHOLE RBA is: 4939
[main] DEBUG (KafkaHandler.java:484) - Process operation: table=[ORCL.SOE.LOGON], op pos=00000000000000004939, tx pos=00000000000000002437, op ts=2016-09-06 10:59:23.000179
[main] DEBUG (KafkaHandler.java:529) - Creating the producer record and sending to Kafka Producer
[main] DEBUG (NonBlockingKafkaProducer.java:64) - Sending producer record to Non Blocking kafka producer
[main] DEBUG (NonBlockingKafkaProducer.java:76) - NBKP:send(): Returning status: OK
[main] DEBUG (PendingOpGroup.java:316) - now ready to checkpoint? false (was ready? false): {pendingOps=18, groupSize=0, timer=0:00:00.000 [total = 0 ms ]}
[main] DEBUG (UserExitDataSource.java:1401) - applyQueuedConfigurationChanges: on Operation? false
[main] DEBUG (UserExitDataSource.java:2342) - UpdateActivityTime call received
[...]
but then a failure, matching the more high-level message we got previously in ggserr.log:
DEBUG 2016-09-06 15:50:52,909 [main] DEBUG (KafkaHandler.java:484) - Process operation: table=[ORCL.SOE.CUSTOMERS], op pos=00000000000000006636, tx pos=00000000000000002437, op ts=2016-09-06 10:59:23.000589
INFO 2016-09-06 15:50:52,910 [main] INFO (AvroOperationSchemaGenerator.java:36) - Generating the Avro schema for the table [ORCL.SOE.CUSTOMERS].
ERROR 2016-09-06 15:50:52,914 [main] ERROR (AvroOperationFormatter.java:188) - The Avro Formatter formatOp operation failed.
org.apache.avro.SchemaParseException: Illegal character in: SYS_NC00017$
at org.apache.avro.Schema.validateName(Schema.java:1083)
at org.apache.avro.Schema.access$200(Schema.java:79)
at org.apache.avro.Schema$Field.<init>(Schema.java:372)
at org.apache.avro.SchemaBuilder$FieldBuilder.completeField(SchemaBuilder.java:2124)
at org.apache.avro.SchemaBuilder$FieldBuilder.completeField(SchemaBuilder.java:2116)
at org.apache.avro.SchemaBuilder$FieldBuilder.access$5300(SchemaBuilder.java:2034)
So from this we've got the table (ORCL.SOE.CUSTOMERS), log offset (6636), and from the stack trace even a hint at what the issue may be (something to do with the Schema, and a column called SYS_NC00017$).
Now let's see if we can find out more. A colleague of mine pointed me towards Logdump, which is well documented and also covered by Oracle's A-Team blog here.
Launch logdump from the OGG BD folder, ideally using rlwrap so that you can scroll and search through command history:
$ rlwrap ./logdump
Oracle GoldenGate Log File Dump Utility
Version 12.2.0.1.160419 OGGCORE_12.2.0.1.0OGGBP_PLATFORMS_160430.1401
Copyright (C) 1995, 2016, Oracle and/or its affiliates. All rights reserved.
Logdump 1 >
Then enter the following, which will determine what information is shown:
Show record headers
GHDR ONShow detailed column data, in both hex and ASCII
DETAIL ON DETAIL DATA
After that, specify the trail file to be examined:
OPEN /u01/ogg-bd/dirdat/rt000000000
You can enter next (or simply n) to view the records one at a time:
Logdump 6 >OPEN /u01/ogg-bd/dirdat/rt000000000
Current LogTrail is /u01/ogg-bd/dirdat/rt000000000
Logdump 7 >n
2016/09/02 15:54:48.329.147 FileHeader Len 1451 RBA 0
Name: *FileHeader*
3000 0338 3000 0008 4747 0d0a 544c 0a0d 3100 0002 | 0..80...GG..TL..1...
0005 3200 0004 2000 0000 3300 0008 02f2 61ba f7c1 | ..2... ...3.....a...
f3bb 3400 002d 002b 7572 693a 6269 6764 6174 616c | ..4..-.+uri:bigdatal
6974 653a 6c6f 6361 6c64 6f6d 6169 6e3a 3a75 3031 | ite:localdomain::u01
3a6f 6767 3a45 5854 4450 3135 0000 2f35 0000 2b00 | :ogg:EXTDP15../5..+.
2975 7269 3a62 6967 6461 7461 6c69 7465 3a6c 6f63 | )uri:bigdatalite:loc
616c 646f 6d61 696e 3a3a 7530 313a 6f67 673a 4558 | aldomain::u01:ogg:EX
Logdump 8 >n
-------------------------------------------------------------------
Hdr-Ind : E (x45) Partition : . (x00)
UndoFlag : . (x00) BeforeAfter: A (x41)
RecLength : 0 (x0000) IO Time : 2016/09/02 15:54:47.562.301
IOType : 151 (x97) OrigNode : 0 (x00)
TransInd : . (x03) FormatType : R (x52)
SyskeyLen : 0 (x00) Incomplete : . (x00)
AuditRBA : 0 AuditPos : 0
Continued : N (x00) RecCount : 0 (x00)
2016/09/02 15:54:47.562.301 RestartOK Len 0 RBA 1459
Name:
After Image: Partition 0 G s
GGS tokens:
4e00 0004 4558 5431 | N...EXT1
But ploughing through the file a transaction at a time is no fun, so lets zero-in on the problem record. We can either just jump straight to the transaction offset that we got from the error log using POSITION (or POS) followed by NEXT:
Logdump 12 >pos 6636
Reading forward from RBA 6636
Logdump 13 >n
-------------------------------------------------------------------
Hdr-Ind : E (x45) Partition : . (x0c)
UndoFlag : . (x00) BeforeAfter: A (x41)
RecLength : 256 (x0100) IO Time : 2016/09/06 11:59:23.000.589
IOType : 5 (x05) OrigNode : 255 (xff)
TransInd : . (x00) FormatType : R (x52)
SyskeyLen : 0 (x00) Incomplete : . (x00)
AuditRBA : 393 AuditPos : 30266384
Continued : N (x00) RecCount : 1 (x01)
2016/09/06 11:59:23.000.589 Insert Len 256 RBA 6636
Name: ORCL.SOE.CUSTOMERS (TDR Index: 3)
After Image: Partition 12 G b
0000 000a 0000 0000 0000 0001 86a1 0001 000a 0000 | ....................
0006 616e 7477 616e 0002 000b 0000 0007 7361 6d70 | ..antwan........samp
736f 6e00 0300 0600 0000 0275 7300 0400 0b00 0000 | son........us.......
0741 4d45 5249 4341 0005 000a 0000 0000 0000 0000 | .AMERICA............
8980 0006 001d 0000 0019 616e 7477 616e 2e73 616d | ..........antwan.sam
7073 6f6e 406f 7261 636c 652e 636f 6d00 0700 0a00 | pson@oracle.com.....
0000 0000 0000 0000 9500 0800 1500 0032 3031 362d | ...............2016-
Column 0 (x0000), Len 10 (x000a)
0000 0000 0000 0001 86a1 | ..........
Column 1 (x0001), Len 10 (x000a)
0000 0006 616e 7477 616e | ....antwan
Column 2 (x0002), Len 11 (x000b)
0000 0007 7361 6d70 736f 6e | ....sampson
Column 3 (x0003), Len 6 (x0006)
0000 0002 7573 | ....us
Column 4 (x0004), Len 11 (x000b)
0000 0007 414d 4552 4943 41 | ....AMERICA
Column 5 (x0005), Len 10 (x000a)
0000 0000 0000 0000 8980 | ..........
Column 6 (x0006), Len 29 (x001d)
0000 0019 616e 7477 616e 2e73 616d 7073 6f6e 406f | ....antwan.sampson@o
7261 636c 652e 636f 6d | racle.com
Column 7 (x0007), Len 10 (x000a)
0000 0000 0000 0000 0095 | ..........
Column 8 (x0008), Len 21 (x0015)
0000 3230 3136 2d30 392d 3036 3a30 303a 3030 3a30 | ..2016-09-06:00:00:0
30 | 0
Column 9 (x0009), Len 14 (x000e)
0000 000a 4f63 6361 7369 6f6e 616c | ....Occasional
Column 10 (x000a), Len 9 (x0009)
0000 0005 4d75 7369 63 | ....Music
Column 11 (x000b), Len 21 (x0015)
0000 3139 3635 2d30 352d 3130 3a30 303a 3030 3a30 | ..1965-05-10:00:00:0
30 | 0
Column 12 (x000c), Len 5 (x0005)
0000 0001 59 | ....Y
Column 13 (x000d), Len 5 (x0005)
0000 0001 4e | ....N
Column 14 (x000e), Len 10 (x000a)
0000 0000 0000 0002 49f1 | ........I.
Column 15 (x000f), Len 10 (x000a)
0000 0000 0000 0002 49f1 | ........I.
or we can also use the FILTER command, but we'll come back to that in a moment. First let's have a look at the record in question that's causing the Kafka handler to abend. It's shown in full above.
The table name matches - ORCL.SOE.CUSTOMERS, and we can see that the operation was an INSERT along with the values for sixteen columns. Now, since we know that the error thrown by the Kafka handler was something to do with schema and columns, let's take a step back. The record we're looking at is the actual data record, but in the trail file will also be metadata about the table itself which will have been read by the handler. We can look for all records in the trail file relating to this table using the FILTER command (preceeded by a POS 0 to move the read back to the beginning of the file):
Logdump 37 >POS 0
Reading forward from RBA 0
Logdump 38 >FILTER INCLUDE FILENAME ORCL.SOE.CUSTOMERS
Logdump 39 >N
-------------------------------------------------------------------
Hdr-Ind : E (x45) Partition : . (x00)
UndoFlag : . (x00) BeforeAfter: A (x41)
RecLength : 1464 (x05b8) IO Time : 2016/09/06 11:59:26.461.886
IOType : 170 (xaa) OrigNode : 2 (x02)
TransInd : . (x03) FormatType : R (x52)
SyskeyLen : 0 (x00) Incomplete : . (x00)
DDR/TDR Idx: (002, 003) AuditPos : 30266384
Continued : N (x00) RecCount : 1 (x01)
2016/09/06 11:59:26.461.886 Metadata Len 1464 RBA 5103
Name: ORCL.SOE.CUSTOMERS
*
1)Name 2)Data Type 3)External Length 4)Fetch Offset 5)Scale 6)Level
7)Null 8)Bump if Odd 9)Internal Length 10)Binary Length 11)Table Length 12)Most Sig DT
13)Least Sig DT 14)High Precision 15)Low Precision 16)Elementary Item 17)Occurs 18)Key Column
19)Sub DataType 20)Native DataType 21)Character Set 22)Character Length 23)LOB Type 24)Partial Type
*
TDR version: 1
Definition for table ORCL.SOE.CUSTOMERS
Record Length: 542
Columns: 18
CUSTOMER_ID 134 13 0 0 0 1 0 8 8 8 0 0 0 0 1 0 1 3 2 -1 0 0 0
CUST_FIRST_NAME 64 40 12 0 0 1 0 40 40 0 0 0 0 0 1 0 0 0 1 -1 0 0 0
CUST_LAST_NAME 64 40 58 0 0 1 0 40 40 0 0 0 0 0 1 0 0 0 1 -1 0 0 0
NLS_LANGUAGE 64 3 104 0 0 1 0 3 3 0 0 0 0 0 1 0 0 0 1 -1 0 0 0
NLS_TERRITORY 64 30 112 0 0 1 0 30 30 0 0 0 0 0 1 0 0 0 1 -1 0 0 0
CREDIT_LIMIT 134 11 148 2 0 1 0 8 8 8 0 0 0 0 1 0 0 3 2 -1 0 0 0
CUST_EMAIL 64 100 160 0 0 1 0 100 100 0 0 0 0 0 1 0 0 0 1 -1 0 0 0
ACCOUNT_MGR_ID 134 13 266 0 0 1 0 8 8 8 0 0 0 0 1 0 0 3 2 -1 0 0 0
CUSTOMER_SINCE 192 19 278 0 0 1 0 19 19 19 0 5 0 0 1 0 0 0 12 -1 0 0 0
CUSTOMER_CLASS 64 40 300 0 0 1 0 40 40 0 0 0 0 0 1 0 0 0 1 -1 0 0 0
SUGGESTIONS 64 40 346 0 0 1 0 40 40 0 0 0 0 0 1 0 0 0 1 -1 0 0 0
DOB 192 19 392 0 0 1 0 19 19 19 0 5 0 0 1 0 0 0 12 -1 0 0 0
MAILSHOT 64 1 414 0 0 1 0 1 1 0 0 0 0 0 1 0 0 0 1 -1 0 0 0
PARTNER_MAILSHOT 64 1 420 0 0 1 0 1 1 0 0 0 0 0 1 0 0 0 1 -1 0 0 0
PREFERRED_ADDRESS 134 13 426 0 0 1 0 8 8 8 0 0 0 0 1 0 0 3 2 -1 0 0 0
PREFERRED_CARD 134 13 438 0 0 1 0 8 8 8 0 0 0 0 1 0 0 3 2 -1 0 0 0
SYS_NC00017$ 64 40 450 0 0 1 0 40 40 0 0 0 0 0 1 0 0 0 1 -1 0 0 0
SYS_NC00018$ 64 40 496 0 0 1 0 40 40 0 0 0 0 0 1 0 0 0 1 -1 0 0 0
End of definition
I spy with my little eye ... SYS_NC00017$, which was named in the debug log that we saw above. Also note:
Columns: 18
So the OGG metadata for the table shows it with eighteen columns, including two SYS_[...]. If you look at the data shown in the record at position 6636 above you'll see that there are only sixteen columns of data. Let's now check out the schema for the table in question in Oracle.
SQL> select COLUMN_NAME,DATA_TYPE from user_tab_columns where table_name = 'CUSTOMERS';
COLUMN_NAME DATA_TYPE
-------------------- ----------------
PREFERRED_CARD NUMBER
PREFERRED_ADDRESS NUMBER
PARTNER_MAILSHOT VARCHAR2
MAILSHOT VARCHAR2
DOB DATE
SUGGESTIONS VARCHAR2
CUSTOMER_CLASS VARCHAR2
CUSTOMER_SINCE DATE
ACCOUNT_MGR_ID NUMBER
CUST_EMAIL VARCHAR2
CREDIT_LIMIT NUMBER
NLS_TERRITORY VARCHAR2
NLS_LANGUAGE VARCHAR2
CUST_LAST_NAME VARCHAR2
CUST_FIRST_NAME VARCHAR2
CUSTOMER_ID NUMBER
16 rows selected.
Sixteen columns. Not eighteen, as the OGG trail file Metadata record showed. Hmmm.
Interestingly, Google throws up a match for this very column in which the output of Dbvisit's replicate tool run against the Swingbench schema announces:
Column SYS_NC00017$ is special: virtual column. Excluding.
Column SYS_NC00017$ is special: hidden column. Excluding.
Column SYS_NC00017$ is special: system-generated column. Excluding.
That it's a hidden column we'd pretty much guessed given its elusiveness. But - virtual column? system generated? This then prompted me to look at the indices on the table:
SQL> SELECT TABLE_NAME, INDEX_NAME, COLUMN_NAME
FROM USER_IND_COLUMNS
WHERE TABLE_NAME = 'CUSTOMERS';
TABLE_NAME INDEX_NAME COLUMN_NAME
---------------- -------------------------------- --------------------
CUSTOMERS CUST_ACCOUNT_MANAGER_IX ACCOUNT_MGR_ID
CUSTOMERS CUST_EMAIL_IX CUST_EMAIL
CUSTOMERS CUST_FUNC_LOWER_NAME_IX SYS_NC00017$
CUSTOMERS CUST_FUNC_LOWER_NAME_IX SYS_NC00018$
CUSTOMERS CUSTOMERS_PK CUSTOMER_ID
CUSTOMERS CUST_DOB_IX DOB
Aha! I spy system generated columns! Let's take a closer look at the CUST_FUNC_LOWER_NAME_IX index:
SQL> SELECT INDEX_NAME, INDEX_TYPE
FROM USER_INDEXES
WHERE TABLE_NAME = 'CUSTOMERS'
AND INDEX_NAME='CUST_FUNC_LOWER_NAME_IX';
INDEX_NAME INDEX_TYPE
-------------------------------- ---------------------------
CUST_FUNC_LOWER_NAME_IX FUNCTION-BASED NORMAL
So we have a function-based index, which in the background appears to implement itself via two hidden columns. My guess is that the Kafka handler code is taking the metadata definition record of 18 columns too literally, and expecting to find a value for it in the transaction record when it reads it and falls over when it can't. Similar behaviour happens with the Kafka Connect OGG connector when it tries to process this particular record:
ERROR 2016-08-30 17:25:09,548 [main] ERROR (KafkaConnectFormatter.java:251) - The Kafka Connect Row Formatter formatOp operation failed.
java.lang.IndexOutOfBoundsException: Index: 16, Size: 16
at java.util.ArrayList.rangeCheck(ArrayList.java:653)
at java.util.ArrayList.get(ArrayList.java:429)
at oracle.goldengate.datasource.meta.TableMetaData.getColumnMetaData(TableMetaData.java:73)
at oracle.goldengate.kafkaconnect.formatter.KafkaConnectFormatter.formatAfterValues(KafkaConnectFormatter.java:329)
at oracle.goldengate.kafkaconnect.formatter.KafkaConnectFormatter.formatAfterValuesOp(KafkaConnectFormatter.java:278)
at oracle.goldengate.kafkaconnect.formatter.KafkaConnectFormatter.formatOp(KafkaConnectFormatter.java:212)
at oracle.goldengate.kafkaconnect.KafkaConnectHandler.formatOp(KafkaConnectHandler.java:309)
at oracle.goldengate.kafkaconnect.KafkaConnectHandler.transactionCommit(KafkaConnectHandler.java:186)
at oracle.goldengate.datasource.DsEventManager$2.send(DsEventManager.java:414)
at oracle.goldengate.datasource.DsEventManager$EventDispatcher.distributeEvent(DsEventManager.java:231)
at oracle.goldengate.datasource.DsEventManager.fireTransactionCommit(DsEventManager.java:422)
at oracle.goldengate.datasource.AbstractDataSource.fireTransactionCommit(AbstractDataSource.java:490)
at oracle.goldengate.datasource.UserExitDataSource.commitActiveTransaction(UserExitDataSource.java:1582)
at oracle.goldengate.datasource.UserExitDataSource.commitTx(UserExitDataSource.java:1525)
ERROR 2016-08-30 17:25:09,550 [main] ERROR (KafkaConnectHandler.java:312) - Confluent Kafka Handler failed to format and process operation: table=[PDB.SOE.CUSTOMERS], op pos=00000000000000008091, tx pos=00000000000000003011, op ts=2016-07-29 14:59:47.000137
java.lang.IndexOutOfBoundsException: Index: 16, Size: 16
at java.util.ArrayList.rangeCheck(ArrayList.java:653)
at java.util.ArrayList.get(ArrayList.java:429)
at oracle.goldengate.datasource.meta.TableMetaData.getColumnMetaData(TableMetaData.java:73)
Note the IndexOutOfBoundsException error.
Working around the error
I'm in the fortunate position of being in a sandbox environment in which I can modify the source schema to suit my needs - so I just dropped the function-based index. In reality this evidently would not be a good approach on the assumption that the index was there for a good reason!
DROP INDEX "SOE"."CUST_FUNC_LOWER_NAME_IX";
Having run this, we still have the question of how to get the replicat working. To do this we could go the whole-hog and drop and recreate the extracts; or, we can get the replicat to skip the section of the trail file with the records in that we can't process. Assuming you've run the above DROP and then written more data to the table, there'll be a second metadata record in the OGG trail file. We can use the FILTER command to find this:
Logdump 69 >FILTER INCLUDE FILENAME ORCL.SOE.CUSTOMERS;FILTER EXCLUDE RECTYPE 5,134;FILTER MATCH ALL
This shows records for just this table, and excludes record types 5 and 134 (INSERT and UPDATE respectively). We can then scan through the file with NEXT command and see:
Logdump 72 >n
Scanned 10000 records, RBA 2365691, 2016/09/06 12:12:16.001.191
Scanned 20000 records, RBA 4716374, 2016/09/06 14:48:54.971.161
Scanned 30000 records, RBA 7067022, 2016/09/06 14:57:34.000.170
Scanned 40000 records, RBA 9413177, 2016/09/06 15:07:41.000.186
Scanned 50000 records, RBA 11773709, 2016/09/06 15:16:07.000.594
Scanned 60000 records, RBA 14126750, 2016/09/06 15:24:38.001.063
-------------------------------------------------------------------
Hdr-Ind : E (x45) Partition : . (x00)
UndoFlag : . (x00) BeforeAfter: A (x41)
RecLength : 1308 (x051c) IO Time : 2016/09/06 17:11:21.717.818
IOType : 170 (xaa) OrigNode : 2 (x02)
TransInd : . (x03) FormatType : R (x52)
SyskeyLen : 0 (x00) Incomplete : . (x00)
DDR/TDR Idx: (002, 009) AuditPos : 9986576
Continued : N (x00) RecCount : 1 (x01)
2016/09/06 17:11:21.717.818 Metadata Len 1308 RBA 14702330
Name: ORCL.SOE.CUSTOMERS
*
1)Name 2)Data Type 3)External Length 4)Fetch Offset 5)Scale 6)Level
7)Null 8)Bump if Odd 9)Internal Length 10)Binary Length 11)Table Length 12)Most Sig DT
13)Least Sig DT 14)High Precision 15)Low Precision 16)Elementary Item 17)Occurs 18)Key Column
19)Sub DataType 20)Native DataType 21)Character Set 22)Character Length 23)LOB Type 24)Partial Type
*
TDR version: 1
Definition for table ORCL.SOE.CUSTOMERS
Record Length: 450
Columns: 16
CUSTOMER_ID 134 13 0 0 0 1 0 8 8 8 0 0 0 0 1 0 1 3 2 -1 0 0 0
CUST_FIRST_NAME 64 40 12 0 0 1 0 40 40 0 0 0 0 0 1 0 0 0 1 -1 0 0 0
CUST_LAST_NAME 64 40 58 0 0 1 0 40 40 0 0 0 0 0 1 0 0 0 1 -1 0 0 0
NLS_LANGUAGE 64 3 104 0 0 1 0 3 3 0 0 0 0 0 1 0 0 0 1 -1 0 0 0
NLS_TERRITORY 64 30 112 0 0 1 0 30 30 0 0 0 0 0 1 0 0 0 1 -1 0 0 0
CREDIT_LIMIT 134 11 148 2 0 1 0 8 8 8 0 0 0 0 1 0 0 3 2 -1 0 0 0
CUST_EMAIL 64 100 160 0 0 1 0 100 100 0 0 0 0 0 1 0 0 0 1 -1 0 0 0
ACCOUNT_MGR_ID 134 13 266 0 0 1 0 8 8 8 0 0 0 0 1 0 0 3 2 -1 0 0 0
CUSTOMER_SINCE 192 19 278 0 0 1 0 19 19 19 0 5 0 0 1 0 0 0 12 -1 0 0 0
CUSTOMER_CLASS 64 40 300 0 0 1 0 40 40 0 0 0 0 0 1 0 0 0 1 -1 0 0 0
SUGGESTIONS 64 40 346 0 0 1 0 40 40 0 0 0 0 0 1 0 0 0 1 -1 0 0 0
DOB 192 19 392 0 0 1 0 19 19 19 0 5 0 0 1 0 0 0 12 -1 0 0 0
MAILSHOT 64 1 414 0 0 1 0 1 1 0 0 0 0 0 1 0 0 0 1 -1 0 0 0
PARTNER_MAILSHOT 64 1 420 0 0 1 0 1 1 0 0 0 0 0 1 0 0 0 1 -1 0 0 0
PREFERRED_ADDRESS 134 13 426 0 0 1 0 8 8 8 0 0 0 0 1 0 0 3 2 -1 0 0 0
PREFERRED_CARD 134 13 438 0 0 1 0 8 8 8 0 0 0 0 1 0 0 3 2 -1 0 0 0
End of definition
Filtering suppressed 62444 records
Here's the new table metadata, for sixten columns only and minus the SYS_[...] columns. Its position as shown in the record above is RBA 14702330. To get the commit sequence number (CSN), which we can use to restart the replicat, we need to enable the display of OGG-generated data in the records (ref):
GGSTOKEN ON
GGSTOKEN DETAIL
The Metadata record itself doesn't have a CSN, so disable the filtering
FILTER OFF
and then go to the next record
Logdump 123 >FILTER OFF
Logdump 124 >N
-------------------------------------------------------------------
Hdr-Ind : E (x45) Partition : . (x0c)
UndoFlag : . (x00) BeforeAfter: A (x41)
RecLength : 255 (x00ff) IO Time : 2016/09/06 17:11:18.000.200
IOType : 5 (x05) OrigNode : 255 (xff)
TransInd : . (x00) FormatType : R (x52)
SyskeyLen : 0 (x00) Incomplete : . (x00)
AuditRBA : 396 AuditPos : 9986576
Continued : N (x00) RecCount : 1 (x01)
2016/09/06 17:11:18.000.200 Insert Len 255 RBA 14703707
Name: ORCL.SOE.CUSTOMERS (TDR Index: 9)
After Image: Partition 12 G b
0000 000a 0000 0000 0000 0009 27c1 0001 000b 0000 | ............'.......
0007 6775 7374 6176 6f00 0200 0a00 0000 0663 6173 | ..gustavo........cas
[...]
GGS tokens:
TokenID x52 'R' ORAROWID Info x00 Length 20
4141 4166 632f 4141 4141 4141 434d 6541 4162 0001 | AAAfc/AAAAAACMeAAb..
TokenID x4c 'L' LOGCSN Info x00 Length 8
3131 3637 3235 3433 | 11672543
TokenID x36 '6' TRANID Info x00 Length 9
3236 2e32 372e 3139 35 | 26.27.195
TokenID x69 'i' ORATHREADID Info x01 Length 2
0001 | ..
It's an INSERT record for our table, with the LOGCSN shown as 11672543.
So if we're happy to ditch all the data in the trail file since it was set up until the point at which we 'fixed' the virtual column issue, we can run in GGSCI:
GGSCI (bigdatalite.localdomain) 44> start rkafka atcsn 0.11672543
Sending START request to MANAGER ...
REPLICAT RKAFKA starting
GGSCI (bigdatalite.localdomain) 49> info rkafka
REPLICAT RKAFKA Last Started 2016-09-06 17:32 Status RUNNING
Checkpoint Lag 00:00:00 (updated 00:00:09 ago)
Process ID 25860
Log Read Checkpoint File ./dirdat/rt000000000
2016-09-06 17:11:22.000764 RBA 14724721
and over in Kafka itself we can now see the records coming through:
$ kafka-console-consumer --zookeeper localhost --topic ORCL.SOE.LOGON
ORCL.SOE.LOGONI42016-09-02 14:56:26.00041142016-09-06T15:50:52.194000(00000000000000002010LOGON_IDCUSTOMER_IDLOGON_DATE4242&2016-09-02:15:56:25
ORCL.SOE.LOGONI42016-09-05 14:39:02.00040942016-09-06T15:50:52.875000(00000000000000002437LOGON_IDCUSTOMER_IDLOGON_DATE4242&2016-09-05:15:39:00
ORCL.SOE.LOGONI42016-09-05 14:44:15.00046042016-09-06T15:50:52.877000(00000000000000002593LOGON_IDCUSTOMER_IDLOGON_DATE4242&2016-09-05:15:44:13
ORCL.SOE.LOGONI42016-09-05 14:46:16.00043642016-09-06T15:50:52.879000(00000000000000002748LOGON_IDCUSTOMER_IDLOGON_DATE4242&2016-09-05:15:46:11
ORCL.SOE.LOGONI42016-09-05 16:17:25.00014242016-09-06T15:50:52.881000(00000000000000002903LOGON_IDCUSTOMER_IDLOGON_DATE4242&2016-09-05:17:17:24
ORCL.SOE.LOGONI42016-09-05 16:22:38.00040142016-09-06T15:50:52.883000(00000000000000003058LOGON_IDCUSTOMER_IDLOGON_DATE4242&2016-09-05:17:22:37
ORCL.SOE.LOGONI42016-09-05 16:25:16.00015142016-09-06T15:50:52.885000(00000000000000003215LOGON_IDCUSTOMER_IDLOGON_DATE4242&2016-09-05:17:25:16
ORCL.SOE.LOGONI42016-09-05 16:26:25.00017542016-09-06T15:50:52.886000(00000000000000003372LOGON_IDCUSTOMER_IDLOGON_DATE4242&2016-09-05:17:26:25
ORCL.SOE.LOGONI42016-09-05 16:27:20.00018642016-09-06T15:50:52.888000(00000000000000003527LOGON_IDCUSTOMER_IDLOGON_DATE4242&2016-09-05:17:27:19
A Better Workaround?
Per Handling Other Database Properties, virtual columns can be handled by using the TABLE FETCHCOLS configuration on the extract to read the virtual values and MAP of the replicat to map them to actual columns on the target. Unfortunately, the system-generated column name isn't accepted by OGG in the FETCHCOLS syntax:
INFO OGG-06507 Oracle GoldenGate Capture for Oracle, ext1.prm: MAP (TABLE) resolved (entry ORCL.SOE.CUSTOMERS): TABLE "ORCL"."SOE"."CUSTOMERS", FETCHCOLS(SYS_NC00017$).
ERROR OGG-00366 Oracle GoldenGate Capture for Oracle, ext1.prm: Invalid column specified in FETCHCOLS/FETCHCOLSEXCEPT: SYS_NC00017$.
ERROR OGG-01668 Oracle GoldenGate Capture for Oracle, ext1.prm: PROCESS ABENDING.
Another tack to try, given that in our case we simply want to make sure the virtual columns don't get picked up at all - is to try and ignore the column altogether. Unfortunately from my experimentation with COLSEXCEPT it appears that OGG excludes specified columns from record data, but not the initial metadata (which is what causes the above problems in the first place). Even if this had worked, COLSEXCEPT doesn't like the system-generated column name, abending the Extract process with:
INFO OGG-06507 Oracle GoldenGate Capture for Oracle, ext1.prm: MAP (TABLE) resolved (entry ORCL.SOE.CUSTOMERS): TABLE "ORCL"."SOE"."CUSTOMERS", COLSEXCEPT(SYS_NC00017$).
ERROR OGG-00366 Oracle GoldenGate Capture for Oracle, ext1.prm: Invalid column specified in COLS/COLSEXCEPT: SYS_NC00017$.
ERROR OGG-01668 Oracle GoldenGate Capture for Oracle, ext1.prm: PROCESS ABENDING.
Conclusion
Oracle GoldenGate is a fantastic way to stream changes from many different RDBMS to a variety of targets, including Kafka. The potential that this offers in terms of data integration and pipelines is great. This post has hopefully shed a little bit of light on how to go about troubleshooting issues that can occur when using this set of tools. Do let me know in the comments below if you have better suggestions for how to deal with the virtual columns created as a result of the function-based index!
An Introduction to Apache Drill
Apache Drill is an engine that can connect to many different data sources, and provide a SQL interface to them. It's not just a wanna-be SQL interface that trips over at anything complex - it's a hugely functional one including support for many built in functions as well as windowing functions. Whilst it can connect to standard data sources that you'd be able to query with SQL anyway, like Oracle or MySQL, it can also work with flat files such as CSV or JSON, as well as Avro and Parquet formats. It's this capability to run SQL against files that first piqued my interest in Apache Drill. I've been spending a lot of time looking at Big Data architectures and tools, including Big Data Discovery. As part of this, and experimenting with data pipeline options one of the gaps that I've found is the functionality to dig through files in their raw state, before they've been brought into something like Hive which would enable their exploration through BDD and other tools.
In this article I'll walk through getting started with Apache Drill, and show some of the types of queries that I think are a great example of how useful it can be.
Getting Started
It's very simple to get going with Apache Drill - just download and unpack it, and run. Whilst it can run distributed across machines for performance, it can also run standalone on a laptop.
To launch it
cd /opt/apache-drill-1.7.0/
bin/sqlline -u jdbc:drill:zk=local
If you get No current connection or com.fasterxml.jackson.databind.JavaType.isReferenceType()Z then you have a conflicting JAR problem (e.g. I encountered this on Oracle's BigDataLite VM), and should launch it with a clean environment
env -i HOME="$HOME" LC_CTYPE="${LC_ALL:-${LC_CTYPE:-$LANG}}" PATH="$PATH" USER="$USER" /opt/apache-drill-1.7.0/bin/drill-embedded
There's a built in dataset that you can use for testing:
USE cp;
SELECT employee_id, first_name FROM `employee.json` limit 5;
This should return five rows, in a very familiar environment if you're used to using SQL*Plus and similar tools:
0: jdbc:drill:zk=local> USE cp;
+-------+---------------------------------+
| ok | summary |
+-------+---------------------------------+
| true | Default schema changed to [cp] |
+-------+---------------------------------+
1 row selected (1.776 seconds)
0: jdbc:drill:zk=local> SELECT employee_id, first_name FROM `employee.json` limit 5;
+--------------+-------------+
| employee_id | first_name |
+--------------+-------------+
| 1 | Sheri |
| 2 | Derrick |
| 4 | Michael |
| 5 | Maya |
| 6 | Roberta |
+--------------+-------------+
5 rows selected (3.624 seconds)
So far, so SQL, so relational - so familiar, really. Where Apache Drill starts to deviate from the obvious is its use of storage handlers. In the above query cp is the 'database' that we're running our query against, but this is in fact a "classpath" (hence "cp") storage handler that's defined by default. Within a 'database' there are 'schemas' which are sub-configurations of the storage handler. We'll have a look at viewing and defining these later on. For now, it's useful to know that you can also list out the available databases:
0: jdbc:drill:zk=local> show databases;
+---------------------+
| SCHEMA_NAME |
+---------------------+
| INFORMATION_SCHEMA |
| cp.default |
| dfs.default |
| dfs.root |
| dfs.tmp |
| sys |
+---------------------+
Note databases command is a synonym for schemas; it's the <database>.<schema> that's returned for both. In Apache Drill the backtick is used to enclose identifiers (such as schema names, column names, and so on), and it's quite particular about it. For example, this is valid:
0: jdbc:drill:zk=local> USE `cp.default`;
+-------+-----------------------------------------+
| ok | summary |
+-------+-----------------------------------------+
| true | Default schema changed to [cp.default] |
+-------+-----------------------------------------+
1 row selected (0.171 seconds)
whilst this isn't:
0: jdbc:drill:zk=local> USE cp.default;
Error: PARSE ERROR: Encountered ". default" at line 1, column 7.
Was expecting one of:
<EOF>
"." <IDENTIFIER> ...
"." <QUOTED_IDENTIFIER> ...
"." <BACK_QUOTED_IDENTIFIER> ...
"." <BRACKET_QUOTED_IDENTIFIER> ...
"." <UNICODE_QUOTED_IDENTIFIER> ...
"." "*" ...
SQL Query USE cp.default
This is because default is a reserved word, and hence must be quoted. Hence, you can also use
0: jdbc:drill:zk=local> use cp.`default`;
but not
0: jdbc:drill:zk=local> use `cp`.default;
Querying JSON data
On the Apache Drill website there's some useful tutorials, including one using data provided by Yelp . This was the dataset that originally got me looking at Drill, since I was using it as an input to Big Data Discovery (BDD) but struggling on two counts. First up was how best to define a suitable Hive table over it in order to ingest it to BDD. Following from this was trying to understand what value there might be in the data which would drive how long to spend perfecting the way in which I exposed the data in Hive. The examples below show the kind of complications that complex JSON can introduce when queried in a tabular fashion.
First up, querying a JSON file, with the schema inferred automagically. Pretty cool.
0: jdbc:drill:zk=local> select * from `/user/oracle/incoming/yelp/tip_json/yelp_academic_dataset_tip.json` limit 5;
+---------+------+-------------+-------+------+------+
| user_id | text | business_id | likes | date | type |
+---------+------+-------------+-------+------+------+
| -6rEfobYjMxpUWLNxszaxQ | Don't waste your time. | cE27W9VPgO88Qxe4ol6y_g | 0 | 2013-04-18 | tip |
| EZ0r9dKKtEGVx2CdnowPCw | Your GPS will not allow you to find this place. Put Rankin police department in instead. They are directly across the street. | mVHrayjG3uZ_RLHkLj-AMg | 1 | 2013-01-06 | tip |
| xb6zEQCw9I-Gl0g06e1KsQ | Great drink specials! | KayYbHCt-RkbGcPdGOThNg | 0 | 2013-12-03 | tip |
| QawZN4PSW7ng_9SP7pjsVQ | Friendly staff, good food, great beer selection, and relaxing atmosphere | KayYbHCt-RkbGcPdGOThNg | 0 | 2015-07-08 | tip |
| MLQre1nvUtW-RqMTc4iC9A | Beautiful restoration. | 1_lU0-eSWJCRvNGk78Zh9Q | 0 | 2015-10-25 | tip |
+---------+------+-------------+-------+------+------+
5 rows selected (2.341 seconds)
We can use standard SQL aggregations such as COUNT:
0: jdbc:drill:zk=local> select count(*) from `/user/oracle/incoming/yelp/tip_json/yelp_academic_dataset_tip.json`;
+---------+
| EXPR$0 |
+---------+
| 591864 |
+---------+
1 row selected (4.495 seconds)
as well as GROUP BY operation:
0: jdbc:drill:zk=local> select `date`,count(*) as tip_count from `/user/oracle/incoming/yelp/tip_json/yelp_academic_dataset_tip.json` group by `date` order by 2 desc limit 5;
+-------------+------------+
| date | tip_count |
+-------------+------------+
| 2012-07-21 | 719 |
| 2012-05-19 | 718 |
| 2012-08-04 | 699 |
| 2012-06-23 | 690 |
| 2012-07-28 | 682 |
+-------------+------------+
5 rows selected (7.111 seconds)
Digging into the data a bit, we can see that it's not entirely flat - note, for example, the hours column, which is a nested JSON object:
0: jdbc:drill:zk=local> select full_address,city,hours from `/user/oracle/incoming/yelp/business_json` b limit 5;
+--------------+------+-------+
| full_address | city | hours |
+--------------+------+-------+
| 4734 Lebanon Church Rd
Dravosburg, PA 15034 | Dravosburg | {"Friday":{"close":"21:00","open":"11:00"},"Tuesday":{"close":"21:00","open":"11:00"},"Thursday":{"close":"21:00","open":"11:00"},"Wednesday":{"close":"21:00","open":"11:00"},"Monday":{"close":"21:00","open":"11:00"},"Sunday":{},"Saturday":{}} |
| 202 McClure St
Dravosburg, PA 15034 | Dravosburg | {"Friday":{},"Tuesday":{},"Thursday":{},"Wednesday":{},"Monday":{},"Sunday":{},"Saturday":{}} |
| 1 Ravine St
Dravosburg, PA 15034 | Dravosburg | {"Friday":{},"Tuesday":{},"Thursday":{},"Wednesday":{},"Monday":{},"Sunday":{},"Saturday":{}} |
| 1530 Hamilton Rd
Bethel Park, PA 15234 | Bethel Park | {"Friday":{},"Tuesday":{},"Thursday":{},"Wednesday":{},"Monday":{},"Sunday":{},"Saturday":{}} |
| 301 South Hills Village
Pittsburgh, PA 15241 | Pittsburgh | {"Friday":{"close":"17:00","open":"10:00"},"Tuesday":{"close":"21:00","open":"10:00"},"Thursday":{"close":"17:00","open":"10:00"},"Wednesday":{"close":"21:00","open":"10:00"},"Monday":{"close":"21:00","open":"10:00"},"Sunday":{"close":"18:00","open":"11:00"},"Saturday":{"close":"21:00","open":"10:00"}} |
+--------------+------+-------+
5 rows selected (0.721 seconds)
0: jdbc:drill:zk=local>
With Apache Drill we can simply use dot notation to access nested values. It's necessary to alias the table (b in this example) when you're doing this:
0: jdbc:drill:zk=local> select b.hours from `/user/oracle/incoming/yelp/business_json` b limit 1;
+-------+
| hours |
+-------+
| {"Friday":{"close":"21:00","open":"11:00"},"Tuesday":{"close":"21:00","open":"11:00"},"Thursday":{"close":"21:00","open":"11:00"},"Wednesday":{"close":"21:00","open":"11:00"},"Monday":{"close":"21:00","open":"11:00"},"Sunday":{},"Saturday":{}} |
+-------+
Nested objects can themselves be nested - not a problem with Apache Drill, we just chain the dot notation further:
0: jdbc:drill:zk=local> select b.hours.Friday from `/user/oracle/incoming/yelp/business_json` b limit 1;
+-----------------------------------+
| EXPR$0 |
+-----------------------------------+
| {"close":"21:00","open":"11:00"} |
+-----------------------------------+
1 row selected (0.238 seconds)
Note the use of backtick (`) to quote the reserved open and close keywords:
0: jdbc:drill:zk=local> select b.hours.Friday.`open`,b.hours.Friday.`close` from `/user/oracle/incoming/yelp/business_json` b limit 1;
+---------+---------+
| EXPR$0 | EXPR$1 |
+---------+---------+
| 11:00 | 21:00 |
+---------+---------+
1 row selected (0.58 seconds)
Nested columns are proper objects in their own right in the query, and can be used as predicates too:
0: jdbc:drill:zk=local> select b.name,b.full_address,b.hours.Friday.`open` from `/user/oracle/incoming/yelp/business_json` b where b.hours.Friday.`open` = '11:00' limit 5;
+------------------------+------------------------------------------------+---------+
| name | full_address | EXPR$2 |
+------------------------+------------------------------------------------+---------+
| Mr Hoagie | 4734 Lebanon Church Rd
Dravosburg, PA 15034 | 11:00 |
| Alexion's Bar & Grill | 141 Hawthorne St
Greentree
Carnegie, PA 15106 | 11:00 |
| Rocky's Lounge | 1201 Washington Ave
Carnegie, PA 15106 | 11:00 |
| Papa J's | 200 E Main St
Carnegie
Carnegie, PA 15106 | 11:00 |
| Italian Village Pizza | 2615 Main St
Homestead, PA 15120 | 11:00 |
+------------------------+------------------------------------------------+---------+
5 rows selected (0.404 seconds)
You'll notice in the above output that the full_address field has line breaks in -- we can just use a SQL Function to replace line breaks with commas:
0: jdbc:drill:zk=local> select b.name,regexp_replace(b.full_address,'n',','),b.hours.Friday.`open` from `/user/oracle/incoming/yelp/business_json` b where b.hours.Friday.`open` = '11:00' limit 5;
+------------------------+------------------------------------------------+---------+
| name | EXPR$1 | EXPR$2 |
+------------------------+------------------------------------------------+---------+
| Mr Hoagie | 4734 Lebanon Church Rd,Dravosburg, PA 15034 | 11:00 |
| Alexion's Bar & Grill | 141 Hawthorne St,Greentree,Carnegie, PA 15106 | 11:00 |
| Rocky's Lounge | 1201 Washington Ave,Carnegie, PA 15106 | 11:00 |
| Papa J's | 200 E Main St,Carnegie,Carnegie, PA 15106 | 11:00 |
| Italian Village Pizza | 2615 Main St,Homestead, PA 15120 | 11:00 |
+------------------------+------------------------------------------------+---------+
5 rows selected (1.346 seconds)
Query Federation
So Apache Drill enables you to run SQL queries against data in a multitude of formats and locations, which is rather useful in itself. But even better than that, it lets you federate these sources in a single query. Here's an example of joining between data in HDFS and Oracle:
0: jdbc:drill:zk=local> select X.text,
. . . . . . . . . . . > Y.NAME
. . . . . . . . . . . > from hdfs.`/user/oracle/incoming/yelp/tip_json/yelp_academic_dataset_tip.json` X
. . . . . . . . . . . > inner join ora.MOVIEDEMO.YELP_BUSINESS Y
. . . . . . . . . . . > on X.business_id = Y.BUSINESS_ID
. . . . . . . . . . . > where Y.NAME = 'Chick-fil-A'
. . . . . . . . . . . > limit 5;
+--------------------------------------------------------------------+--------------+
| text | NAME |
+--------------------------------------------------------------------+--------------+
| It's daddy daughter date night here and they go ALL OUT! | Chick-fil-A |
| Chicken minis! The best part of waking up Saturday mornings. :) | Chick-fil-A |
| Nice folks as always unlike those ghetto joints | Chick-fil-A |
| Great clean and delicious chicken sandwiches! | Chick-fil-A |
| Spicy Chicken with lettuce, tomato, and pepperjack cheese FTW! | Chick-fil-A |
+--------------------------------------------------------------------+--------------+
5 rows selected (3.234 seconds)
You can define a view over this:
0: jdbc:drill:zk=local> create or replace view dfs.tmp.yelp_tips as select X.text as tip_text, Y.NAME as business_name from hdfs.`/user/oracle/incoming/yelp/tip_json/yelp_academic_dataset_tip.json` X inner join ora.MOVIEDEMO.YELP_BUSINESS Y on X.business_id = Y.BUSINESS_ID ;
+-------+-------------------------------------------------------------+
| ok | summary |
+-------+-------------------------------------------------------------+
| true | View 'yelp_tips' replaced successfully in 'dfs.tmp' schema |
+-------+-------------------------------------------------------------+
1 row selected (0.574 seconds)
0: jdbc:drill:zk=local> describe dfs.tmp.yelp_tips;
+----------------+--------------------+--------------+
| COLUMN_NAME | DATA_TYPE | IS_NULLABLE |
+----------------+--------------------+--------------+
| tip_text | ANY | YES |
| business_name | CHARACTER VARYING | YES |
+----------------+--------------------+--------------+
2 rows selected (0.756 seconds)
and then query it as any regular object:
0: jdbc:drill:zk=local> select tip_text,business_name from dfs.tmp.yelp_tips where business_name like '%Grill' limit 5;
+------+------+
| text | NAME |
+------+------+
| Great drink specials! | Alexion's Bar & Grill |
| Friendly staff, good food, great beer selection, and relaxing atmosphere | Alexion's Bar & Grill |
| Pretty quiet here... | Uno Pizzeria & Grill |
| I recommend this location for quick lunches. 10 min or less lunch menu. Soup bar ( all you can eat) the broccoli cheddar soup is delicious. | Uno Pizzeria & Grill |
| Instead of pizza, come here for dessert. The deep dish sundae is really good. | Uno Pizzeria & Grill |
+------+------+
5 rows selected (3.272 seconds)
Querying Twitter JSON data
Here's an example of using Drill to query a local file holding some Twitter data. You can download the file here if you want to try querying it yourself.
To start with I switched to using the dfs storage plugin:
0: jdbc:drill:zk=local> use dfs;
+-------+----------------------------------+
| ok | summary |
+-------+----------------------------------+
| true | Default schema changed to [dfs] |
+-------+----------------------------------+
And then tried a select against the file. Note the limit 5 clause - very useful when you're just examining the structure of a file.
0: jdbc:drill:zk=local> select * from `/user/oracle/incoming/twitter/geo_tweets.json` limit 5;
Error: DATA_READ ERROR: Error parsing JSON - Unexpected end-of-input within/between OBJECT entries
File /user/oracle/incoming/twitter/geo_tweets.json
Record 2819
Column 3503
Fragment 0:0
An error? That's not supposed to happen. I've got a JSON file, right? It turns out the JSON file is one complete JSON object per line. Except that it's not on the last record. Note the record count given in the error above - 2819:
[oracle@bigdatalite ~]$ wc -l geo_tweets.json
2818 geo_tweets.json
So the file only has 2818 complete lines. Hmmm. Let's take a look at that record, using a head/tail bash combo :
[oracle@bigdatalite ~]$ head -n 2819 geo_tweets.json |tail -n1
{"created_at":"Sun Jul 24 21:00:44 +0000 2016","id":757319630432067584,"id_str":"757319630432067584","text":"And now @HillaryClinton hires @DWStweets: Honorary Campaign Manager across the USA #corruption #hillarysamerica https://t.co/8jAGUu6w2f","source":"<a href="http://www.handmark.com" rel="nofollow">TweetCaster for iOS</a>","truncated":false,"in_reply_to_status_id":null,"in_reply_to_status_id_str":null,"in_reply_to_user_id":null,"in_reply_to_user_id_str":null,"in_reply_to_screen_name":null,"user":{"id":2170786369,"id_str":"2170786369","name":"Patricia Weber","screen_name":"InnieBabyBoomer","location":"Williamsburg, VA","url":"http://lovesrantsandraves.blogspot.com/","description":"Baby Boomer, Swing Voter, Conservative, Spiritual, #Introvert, Wife, Grandma, Italian, ♥ Books, Cars, Ferrari, F1 Race♥ #tcot","protected":false,"verified":false,"followers_count":861,"friends_count":918,"listed_count":22,"favourites_count":17,"statuses_count":2363,"created_at":"Sat Nov 02 19:13:06 +0000 2013","utc_offset":null,"time_zone":null,"geo_enabled":true,"lang":"en","contributors_enabled":false,"is_translator":false,"profile_background_color":"C0DEED","profile_background_image_url":"http://pbs.twimg.com/profile_background_images/378800000107659131/3589f
That's the complete data in the file - so Drill is right - the JSON is corrupted. If we drop that last record and create a new file (geo_tweets.fixed.json)
head -n2818 geo_tweets.json > geo_tweets.fixed.json
and query it again, we get something!
0: jdbc:drill:zk=local> select text from `/users/rmoff/data/geo_tweets.fixed.json` limit 5;
+------+
| text |
+------+
| Vancouver trends now: Trump, Evander Kane, Munich, 2016HCC and dcc16. https://t.co/joI9GMfRim |
| We're #hiring! Click to apply: Bench Jeweler - SEC Oracle & Wetmore - https://t.co/Oe2SHaL0Hh #Job #SkilledTrade #Tucson, AZ #Jobs |
| Donald Trump accepted the Republican nomination last night. Isis claimed responsibility. |
| Obama: "We must stand together and stop terrorism"
Trump: "We don't want these people in our country"
� |
| Someone built a wall around Trump's star on the Hollywood Walk of Fame. #lol #nowthatsfunny @… https://t.co/qHWuJXnzbw |
+------+
5 rows selected (0.246 seconds)
text here being one of the json fields. I could do a select * but it's not so intelligable:
0: jdbc:drill:zk=local> select * from `/users/rmoff/data/geo_tweets.fixed.json` limit 5;
+------------+----+--------+------+--------+-----------+------+-----+-------------+-------+-----------------+---------------+----------------+----------+-----------+-----------+--------------------+--------------+------+--------------+----------+------------+-----------+------------------+----------------------+--------------------+-------------------+-----------------------+---------------------+-----------------+------------+---------------+---------------+------------+-----------+--------------------------------+-----------+----------+----------------+-------------------+---------------------------------+-----------------------+---------------------------+---------------------+-------------------------+-------------------------+------------------+-----------------------+------------------+----------------------+---------------+
| created_at | id | id_str | text | source | truncated | user | geo | coordinates | place | is_quote_status | retweet_count | favorite_count | entities | favorited | retweeted | possibly_sensitive | filter_level | lang | timestamp_ms | @version | @timestamp | user_name | user_screen_name | user_followers_count | user_friends_count | user_listed_count | user_favourites_count | user_statuses_count | user_created_at | place_name | place_country | hashtags_list | urls_array | urls_list | user_mentions_screen_name_list | longitude | latitude | hashtags_array | extended_entities | user_mentions_screen_name_array | in_reply_to_status_id | in_reply_to_status_id_str | in_reply_to_user_id | in_reply_to_user_id_str | in_reply_to_screen_name | retweeted_status | retweeted_screen_name | quoted_status_id | quoted_status_id_str | quoted_status |
+------------+----+--------+------+--------+-----------+------+-----+-------------+-------+-----------------+---------------+----------------+----------+-----------+-----------+--------------------+--------------+------+--------------+----------+------------+-----------+------------------+----------------------+--------------------+-------------------+-----------------------+---------------------+-----------------+------------+---------------+---------------+------------+-----------+--------------------------------+-----------+----------+----------------+-------------------+---------------------------------+-----------------------+---------------------------+---------------------+-------------------------+-------------------------+------------------+-----------------------+------------------+----------------------+---------------+
| Fri Jul 22 19:37:11 +0000 2016 | 756573827589545984 | 756573827589545984 | Vancouver trends now: Trump, Evander Kane, Munich, 2016HCC and dcc16. https://t.co/joI9GMfRim | <a href="http://dlvr.it" rel="nofollow">dlvr.it</a> | false | {"id":67898674,"id_str":"67898674","name":"Vancouver Press","screen_name":"Vancouver_CP","location":"Vancouver, BC","url":"http://vancouver.cityandpress.com/","description":"Latest news from Vancouver. Updates are frequent.","protected":false,"verified":false,"followers_count":807,"friends_count":13,"listed_count":94,"favourites_count":1,"statuses_count":131010,"created_at":"Sat Aug 22 14:25:37 +0000 2009","utc_offset":-25200,"time_zone":"Pacific Time (US & Canada)","geo_enabled":true,"lang":"en","contributors_enabled":false,"is_translator":false,"profile_background_color":"FFFFFF","profile_background_image_url":"http://abs.twimg.com/images/themes/theme1/bg.png","profile_background_image_url_https":"https://abs.twimg.com/images/themes/theme1/bg.png","profile_background_tile":false,"profile_link_color":"8A1C3B","profile_sidebar_border_color":"FFFFFF","profile_sidebar_fill_color":"FFFFFF","profile_text_color":"2A2C31","profile_use_background_image":false,"profile_image_url":"http://pbs.twimg.com/profile_images/515841109553983490/_t0QWPco_normal.png","profile_image_url_https":"https://pbs.twimg.com/profile_images/515841109553983490/_t0QWPco_normal.png","profile_banner_url":"https://pbs.twimg.com/profile_banners/67898674/1411821103","default_profile":false,"default_profile_image":false} | {"type":"Point","coordinates":[49.2814375,-123.12109067]} | {"type":"Point","coordinates":[-123.12109067,49.2814375]} | {"id":"1e5cb4d0509db554","url":"https://api.twitter.com/1.1/geo/id/1e5cb4d0509db554.json","place_type":"city","name":"Vancouver","full_name":"Vancouver, British Columbia","country_code":"CA","country":"Canada","bounding_box":{"type":"Polygon","coordinates":[[[-123.224215,49.19854],[-123.224215,49.316738],[-123.022947,49.316738],[-123.022947,49.19854]]]},"attributes":{}} | false | 0 | 0 | {"urls":[{"url":"https://t.co/joI9GMfRim","expanded_url":"http://toplocalnow.com/ca/vancouver?section=trends","display_url":"toplocalnow.com/ca/vancouver?s…","indices":[70,93]}],"hashtags":[],"user_mentions":[],"media":[],"symbols":[]} | false | false | false | low | en | 1469216231616 | 1 | 2016-07-22T19:37:11.000Z | Vancouver Press | Vancouver_CP | 807 | 13 | 94 | 1 | 131010 | Sat Aug 22 14:25:37 +0000 2009 | Vancouver | Canada | | ["toplocalnow.com/ca/vancouver?s…"] | toplocalnow.com/ca/vancouver?s… | | -123.12109067 | 49.2814375 | [] | {"media":[]} | [] | null | null | null | null | null | {"user":{},"entities":{"user_mentions":[],"media":[],"hashtags":[],"urls":[]},"extended_entities":{"media":[]},"quoted_status":{"user":{},"entities":{"hashtags":[],"user_mentions":[],"media":[],"urls":[]},"extended_entities":{"media":[]}}} | null | null | null | {"user":{},"entities":{"user_mentions":[],"media":[],"urls":[],"hashtags":[]},"extended_entities":{"media":[]},"place":{"bounding_box":{"coordinates":[]},"attributes":{}},"geo":{"coordinates":[]},"coordinates":{"coordinates":[]}} |
Within the twitter data there's root-level fields, such as text, as well as nested ones such as information about the tweeter in the user field. As we saw above you reference nested fields using dot notation. Now's a good time to point out a couple of common mistakes that you may encounter. The first is not quoting reserved words, and is the first thing to check for if you get an error such as Encountered ".":
0: jdbc:drill:zk=local> select user.screen_name,text from `/users/rmoff/data/geo_tweets.fixed.json` limit 5;
Error: PARSE ERROR: Encountered "." at line 1, column 12.
[...]
Second is declaring the table alias when using dot notation - if you don't then Apache Drill thinks that the parent column is actually the table name (VALIDATION ERROR: [...] Table 'user' not found):
0: jdbc:drill:zk=local> select `user`.screen_name,text from dfs.`/users/rmoff/data/geo_tweets.fixed.json` limit 5;
Aug 10, 2016 11:16:45 PM org.apache.calcite.sql.validate.SqlValidatorException <init>
SEVERE: org.apache.calcite.sql.validate.SqlValidatorException: Table 'user' not found
Aug 10, 2016 11:16:45 PM org.apache.calcite.runtime.CalciteException <init>
SEVERE: org.apache.calcite.runtime.CalciteContextException: From line 1, column 8 to line 1, column 13: Table 'user' not found
Error: VALIDATION ERROR: From line 1, column 8 to line 1, column 13: Table 'user' not found
SQL Query null
[Error Id: 1427fd23-e180-40be-a751-b6f1f838233a on 192.168.56.1:31010] (state=,code=0)
With those mistakes fixed, we can see the user's screenname:
0: jdbc:drill:zk=local> select tweets.`user`.`screen_name` as user_screen_name,text from dfs.`/users/rmoff/data/geo_tweets.fixed.json` tweets limit 2;
+------------------+------+
| user_screen_name | text |
+------------------+------+
| Vancouver_CP | Vancouver trends now: Trump, Evander Kane, Munich, 2016HCC and dcc16. https://t.co/joI9GMfRim |
| tmj_TUC_skltrd | We're #hiring! Click to apply: Bench Jeweler - SEC Oracle & Wetmore - https://t.co/Oe2SHaL0Hh #Job #SkilledTrade #Tucson, AZ #Jobs |
+------------------+------+
2 rows selected (0.256 seconds)
0: jdbc:drill:zk=local>
As well as nested objects, JSON supports arrays. An example of this in twitter data is hashtags, or URLs, both of which there can be zero, one, or many of in a given tweet.
0: jdbc:drill:zk=local> select tweets.entities.hashtags from dfs.`/users/rmoff/data/geo_tweets.fixed.json` tweets limit 5;
+--------+
| EXPR$0 |
+--------+
| [] |
| [{"text":"hiring","indices":[6,13]},{"text":"Job","indices":[98,102]},{"text":"SkilledTrade","indices":[103,116]},{"text":"Tucson","indices":[117,124]},{"text":"Jobs","indices":[129,134]}] |
| [] |
| [] |
| [{"text":"lol","indices":[72,76]},{"text":"nowthatsfunny","indices":[77,91]}] |
+--------+
5 rows selected (0.286 seconds)
Using the FLATTEN function each array entry becomes a new row, thus:
0: jdbc:drill:zk=local> select flatten(tweets.entities.hashtags) from dfs.`/users/rmoff/data/geo_tweets.fixed.json` tweets limit 5;
+----------------------------------------------+
| EXPR$0 |
+----------------------------------------------+
| {"text":"hiring","indices":[6,13]} |
| {"text":"Job","indices":[98,102]} |
| {"text":"SkilledTrade","indices":[103,116]} |
| {"text":"Tucson","indices":[117,124]} |
| {"text":"Jobs","indices":[129,134]} |
+----------------------------------------------+
5 rows selected (0.139 seconds)
Note that the limit 5 clause is showing only the first five array instances, which is actually just hashtags from the first tweet in the above list.
To access the text of the hashtag we use a subquery and the dot notation to access the text field:
0: jdbc:drill:zk=local> select ent_hashtags.hashtags.text from (select flatten(tweets.entities.hashtags) as hashtags from dfs.`/users/rmoff/data/geo_tweets.fixed.json` tweets) as ent_hashtags limit 5;
+---------------+
| EXPR$0 |
+---------------+
| hiring |
| Job |
| SkilledTrade |
| Tucson |
| Jobs |
+---------------+
5 rows selected (0.168 seconds)
This can be made more readable by using Common Table Expressions (CTE, also known as subquery factoring) for the same result:
0: jdbc:drill:zk=local> with ent_hashtags as (select flatten(tweets.entities.hashtags) as hashtags from dfs.`/users/rmoff/data/geo_tweets.fixed.json` tweets)
. . . . . . . . . . . > select ent_hashtags.hashtags.text from ent_hashtags
. . . . . . . . . . . > limit 5;
+---------------+
| EXPR$0 |
+---------------+
| hiring |
| Job |
| SkilledTrade |
| Tucson |
| Jobs |
+---------------+
5 rows selected (0.253 seconds)
Combining the flattened array with existing fields enables us to see things like a list of tweets with their associated hashtags:
0: jdbc:drill:zk=local> with tmp as ( select flatten(tweets.entities.hashtags) as hashtags,tweets.text,tweets.`user`.screen_name as user_screen_name from dfs.`/users/rmoff/data/geo_tweets.fixed.json` tweets) select tmp.user_screen_name,tmp.text,tmp.hashtags.text as hashtag from tmp limit 10;
+------------------+------+---------+
| user_screen_name | text | hashtag |
+------------------+------+---------+
| tmj_TUC_skltrd | We're #hiring! Click to apply: Bench Jeweler - SEC Oracle & Wetmore - https://t.co/Oe2SHaL0Hh #Job #SkilledTrade #Tucson, AZ #Jobs | hiring |
| tmj_TUC_skltrd | We're #hiring! Click to apply: Bench Jeweler - SEC Oracle & Wetmore - https://t.co/Oe2SHaL0Hh #Job #SkilledTrade #Tucson, AZ #Jobs | Job |
| tmj_TUC_skltrd | We're #hiring! Click to apply: Bench Jeweler - SEC Oracle & Wetmore - https://t.co/Oe2SHaL0Hh #Job #SkilledTrade #Tucson, AZ #Jobs | SkilledTrade |
| tmj_TUC_skltrd | We're #hiring! Click to apply: Bench Jeweler - SEC Oracle & Wetmore - https://t.co/Oe2SHaL0Hh #Job #SkilledTrade #Tucson, AZ #Jobs | Tucson |
| tmj_TUC_skltrd | We're #hiring! Click to apply: Bench Jeweler - SEC Oracle & Wetmore - https://t.co/Oe2SHaL0Hh #Job #SkilledTrade #Tucson, AZ #Jobs | Jobs |
| johnmayberry | Someone built a wall around Trump's star on the Hollywood Walk of Fame. #lol #nowthatsfunny @… https://t.co/qHWuJXnzbw | lol |
| johnmayberry | Someone built a wall around Trump's star on the Hollywood Walk of Fame. #lol #nowthatsfunny @… https://t.co/qHWuJXnzbw | nowthatsfunny |
| greensboro_nc | #WinstonSalem Time and place announced for Donald Trump's visit to… https://t.co/6OVl7crshw #ws @winston_salem_ https://t.co/l5h220otj4 | WinstonSalem |
| greensboro_nc | #WinstonSalem Time and place announced for Donald Trump's visit to… https://t.co/6OVl7crshw #ws @winston_salem_ https://t.co/l5h220otj4 | ws |
| trendinaliaSG | 6. Hit The Stage
7. TTTT
8. Demi Lovato
9. Beijing
10. Donald Trump
2016/7/23 03:36 SGT #trndnl https://t.co/psP0GzBgZB | trndnl |
+------------------+------+---------+
10 rows selected (0.166 seconds)
We can also filter based on hashtag:
0: jdbc:drill:zk=local> with tmp as ( select flatten(tweets.entities.hashtags) as hashtags,tweets.text,tweets.`user`.screen_name as user_screen_name from dfs.`/users/rmoff/data/geo_tweets.fixed.json` tweets) select tmp.user_screen_name,tmp.text,tmp.hashtags.text as hashtag from tmp where tmp.hashtags.text = 'Job' limit 5;
+------------------+------+---------+
| user_screen_name | text | hashtag |
+------------------+------+---------+
| tmj_TUC_skltrd | We're #hiring! Click to apply: Bench Jeweler - SEC Oracle & Wetmore - https://t.co/Oe2SHaL0Hh #Job #SkilledTrade #Tucson, AZ #Jobs | Job |
| tmj_VAL_health | Want to work at Genesis Rehab Services? We're #hiring in #Clinton, MD! Click for details: https://t.co/4lt7I4gMZk #Job #Healthcare #Jobs | Job |
| tmj_in_retail | Want to work in #Clinton, IN? View our latest opening: https://t.co/UiimnlubYs #Job #Retail #Jobs #Hiring #CareerArc | Job |
| tmj_la_hrta | Want to work at SONIC Drive-In? We're #hiring in #Clinton, LA! Click for details: https://t.co/aQ1FrWc7iR #Job #SONIC #Hospitality #Jobs | Job |
| tmj_ia_hrta | We're #hiring! Click to apply: Department Manager - https://t.co/SnoKcwwHFk #Job #Hospitality #Clinton, IA #Jobs #CareerArc | Job |
+------------------+------+---------+
5 rows selected (0.207 seconds)
as well as summarise hashtag counts:
0: jdbc:drill:zk=local> with ent_hashtags as (select flatten(tweets.entities.hashtags) as hashtags from dfs.`/users/rmoff/data/geo_tweets.fixed.json` tweets)
. . . . . . . . . . . > select ent_hashtags.hashtags.text,count(ent_hashtags.hashtags.text) from ent_hashtags
. . . . . . . . . . . > group by ent_hashtags.hashtags.text
. . . . . . . . . . . > order by 2 desc;
+-----------------------------+---------+
| EXPR$0 | EXPR$1 |
+-----------------------------+---------+
| Trump | 365 |
| trndnl | 176 |
| job | 170 |
| Hiring | 127 |
| Clinton | 108 |
| Yorkshire | 100 |
| CareerArc | 100 |
[...]
To filter out records that may not have array values (such as hashtags, which not every tweet has) and without with the query may fail, use IS NOT NULL against an attribute of first index of the array:
0: jdbc:drill:zk=local> select tweets.entities.hashtags from dfs.`/users/rmoff/data/geo_tweets.fixed.json` tweets where tweets.entities.hashtags[0].text is not null limit 5;
+--------+
| EXPR$0 |
+--------+
| [{"text":"hiring","indices":[6,13]},{"text":"Job","indices":[98,102]},{"text":"SkilledTrade","indices":[103,116]},{"text":"Tucson","indices":[117,124]},{"text":"Jobs","indices":[129,134]}] |
| [{"text":"lol","indices":[72,76]},{"text":"nowthatsfunny","indices":[77,91]}] |
| [{"text":"WinstonSalem","indices":[0,13]},{"text":"ws","indices":[92,95]}] |
| [{"text":"trndnl","indices":[89,96]}] |
| [{"text":"trndnl","indices":[92,99]}] |
+--------+
5 rows selected (0.187 seconds)
If you try and compare the array itself, it doesn't work:
0: jdbc:drill:zk=local> select tweets.entities.hashtags from dfs.`/users/rmoff/data/geo_tweets.fixed.json` tweets where tweets.entities.hashtags is not null limit 5;
Error: SYSTEM ERROR: SchemaChangeException: Failure while trying to materialize incoming schema. Errors:
Error in expression at index -1. Error: Missing function implementation: [isnotnull(MAP-REPEATED)]. Full expression: --UNKNOWN EXPRESSION--..
Fragment 0:0
[Error Id: 99ac12aa-f6b4-4692-b815-8f483da682c4 on 192.168.56.1:31010] (state=,code=0)
The above example demonstrates using array indexing, which is an alternative to FLATTEN for accessing individual objects in the array if you know they're going to exist:
0: jdbc:drill:zk=local> select tweets.entities.hashtags[0].text as first_hashtag,text from dfs.`/users/rmoff/data/geo_tweets.fixed.json` tweets where tweets.entities.hashtags[0].text is not null limit 5;
+---------------+------+
| first_hashtag | text |
+---------------+------+
| hiring | We're #hiring! Click to apply: Bench Jeweler - SEC Oracle & Wetmore - https://t.co/Oe2SHaL0Hh #Job #SkilledTrade #Tucson, AZ #Jobs |
| lol | Someone built a wall around Trump's star on the Hollywood Walk of Fame. #lol #nowthatsfunny @… https://t.co/qHWuJXnzbw |
| WinstonSalem | #WinstonSalem Time and place announced for Donald Trump's visit to… https://t.co/6OVl7crshw #ws @winston_salem_ https://t.co/l5h220otj4 |
Querying CSV files
JSON files are relatively easy to interpret because they have a semi-defined schema within them, including column names. CSV (and character delimited files in general), on the other hand, are a bit more of a 'wild west' when it comes to reliably inferring column names. You can configure Apache Drill to ignore the first line of a CSV file (on the assumption that it's a header) if you want to, or to take them as column names. If you don't do this and query a CSV file that looks like this:
[oracle@bigdatalite ~]$ head nyc_parking_violations.csv
Summons Number,Plate ID,Registration State,Plate Type,Issue Date,Violation Code,Vehicle Body Type,Vehicle Make,Issuing Agency,Street Code1,Street Code2,Street Code3,Vehicle Expiration Date,Violation Location,Violation Precinct,Issuer Precinct,Issuer Code,Issuer Command,Issuer Squad,Violation Time,Time First Observed,Violation County,Violation In Front Of Or Opposite,House Number,Street Name,Intersecting Street,Date First Observed,Law Section,Sub Division,Violation Legal Code,Days Parking In Effect ,From Hours In Effect,To Hours In Effect,Vehicle Color,Unregistered Vehicle?,Vehicle Year,Meter Number,Feet From Curb,Violation Post Code,Violation Description,No Standing or Stopping Violation,Hydrant Violation,Double Parking Violation
1360858775,PHW9801,OH,PAS,07/01/2015,20,SUBN,HONDA,P,61490,26160,26190,0,0044,44,44,929822,0044,0000,0653P,,BX,O,651,RIVER AVE,,0,408,D,,BBBBBBB,ALL,ALL,,0,0,-,0,,,,,
You'll get two records, each one column wide, as an array:
0: jdbc:drill:zk=local> select * from `/user/oracle/incoming/nyc_parking/nyc_parking_violations.csv` LIMIT 5;
+---------+
| columns |
+---------+
| ["Summons Number","Plate ID","Registration State","Plate Type","Issue Date","Violation Code","Vehicle Body Type","Vehicle Make","Issuing Agency","Street Code1","Street Code2","Street Code3","Vehicle Expiration Date","Violation Location","Violation Precinct","Issuer Precinct","Issuer Code","Issuer Command","Issuer Squad","Violation Time","Time First Observed","Violation County","Violation In Front Of Or Opposite","House Number","Street Name","Intersecting Street","Date First Observed","Law Section","Sub Division","Violation Legal Code","Days Parking In Effect ","From Hours In Effect","To Hours In Effect","Vehicle Color","Unregistered Vehicle?","Vehicle Year","Meter Number","Feet From Curb","Violation Post Code","Violation Description","No Standing or Stopping Violation","Hydrant Violation","Double Parking Violation"] |
| ["1360858775","PHW9801","OH","PAS","07/01/2015","20","SUBN","HONDA","P","61490","26160","26190","0","0044","44","44","929822","0044","0000","0653P","","BX","O","651","RIVER AVE","","0","408","D","","BBBBBBB","ALL","ALL","","0","0","-","0","","","","",""] |
To access the actual columns in the CSV file you need to use columns[x] syntax to reference them. Watch out that columns is case-sensitive, and the numbering is zero-based:
0: jdbc:drill:zk=local> select columns[1] as `PlateID`, columns[2] as `RegistrationState` from `/user/oracle/incoming/nyc_parking/nyc_parking_violations.csv` limit 5;
+----------+--------------------+
| PlateID | RegistrationState |
+----------+--------------------+
| AR877A | NJ |
| 73268ME | NY |
| 2050240 | IN |
| 2250017 | IN |
| AH524C | NJ |
+----------+--------------------+
5 rows selected (0.247 seconds)
To make it easier to work with the data on a repeated basis you can define a view over the data:
0: jdbc:drill:zk=local> create view dfs.tmp.NYC_Parking_01 as select columns[1] as `PlateID`, columns[2] as `RegistrationState` from `/user/oracle/incoming/nyc_parking/nyc_parking_violations.csv`;
+-------+-----------------------------------------------------------------+
| ok | summary |
+-------+-----------------------------------------------------------------+
| true | View 'NYC_Parking_01' created successfully in 'dfs.tmp' schema |
+-------+-----------------------------------------------------------------+
1 row selected (0.304 seconds)
This is using the dfs storage plugin and the tmp schema within it, which has the following storage configuration - note that writeable is true
"tmp": {
"location": "/tmp",
"writable": true,
"defaultInputFormat": null
}
(if you use the wrong database [storage plugin] or schema you'll get Schema [hdfs] is immutable.)
Query the new view
0: jdbc:drill:zk=local> select * from dfs.tmp.NYC_Parking_01 limit 5;
+-----------+---------------------+
| PlateID | RegistrationState |
+-----------+---------------------+
| Plate ID | Registration State |
| PHW9801 | OH |
| K8010F | TN |
| GFG6211 | NY |
| GHL1805 | NY |
+-----------+---------------------+
5 rows selected (0.191 seconds)
Through the view, or direct against the CSV path, you can also run aggregates:
0: jdbc:drill:zk=local> select PlateID,count(*) from dfs.tmp.NYC_Parking_01 group by PlateID having count(*) > 1 limit 1;
+----------+---------+
| PlateID | EXPR$1 |
+----------+---------+
| 2050240 | 4 |
+----------+---------+
1 row selected (15.983 seconds)
Although this isn't rerunnable for the same result - probably because of the limit clause
0: jdbc:drill:zk=local> select PlateID,count(*) from dfs.tmp.NYC_Parking_01 group by PlateID having count(*) > 1 limit 1;
+----------+---------+
| PlateID | EXPR$1 |
+----------+---------+
| AR877A | 3 |
+----------+---------+
1 row selected (12.881 seconds)
Under the covers the view definition is written to /tmp - you'll want to move this path if you're wanting to preserve this data past reboot:
[oracle@bigdatalite parking]$ cat /tmp/NYC_Parking_01.view.drill
{
"name" : "NYC_Parking_01",
"sql" : "SELECT `columns`[1] AS `PlateID`, `columns`[2] AS `RegistrationState`nFROM `/user/oracle/incoming/nyc_parking/nyc_parking_violations.csv`",
"fields" : [ {
"name" : "PlateID",
"type" : "ANY",
"isNullable" : true
}, {
"name" : "RegistrationState",
"type" : "ANY",
"isNullable" : true
} ],
"workspaceSchemaPath" : [ "hdfs" ]
You can also create an actual table using CTAS (Create Table As Select):
0: jdbc:drill:zk=local> create table dfs.tmp.parking as select columns[1] as `PlateID`, columns[2] as `RegistrationState` from `/user/oracle/incoming/nyc_parking/nyc_parking_violations.csv`;
+-----------+----------------------------+
| Fragment | Number of records written |
+-----------+----------------------------+
| 1_1 | 4471875 |
| 1_0 | 4788421 |
+-----------+----------------------------+
2 rows selected (42.913 seconds)
This is stored on disk (per the dfs config) and by default in Parquet format:
[oracle@bigdatalite parking]$ ls -l /tmp/parking/
total 76508
-rw-r--r--. 1 oracle oinstall 40623288 Aug 10 22:53 1_0_0.parquet
-rw-r--r--. 1 oracle oinstall 37717804 Aug 10 22:53 1_1_0.parquet
Drill's Web Interface
Drill comes with a web interface which you can access at http://<IP>:8047/ and is useful for
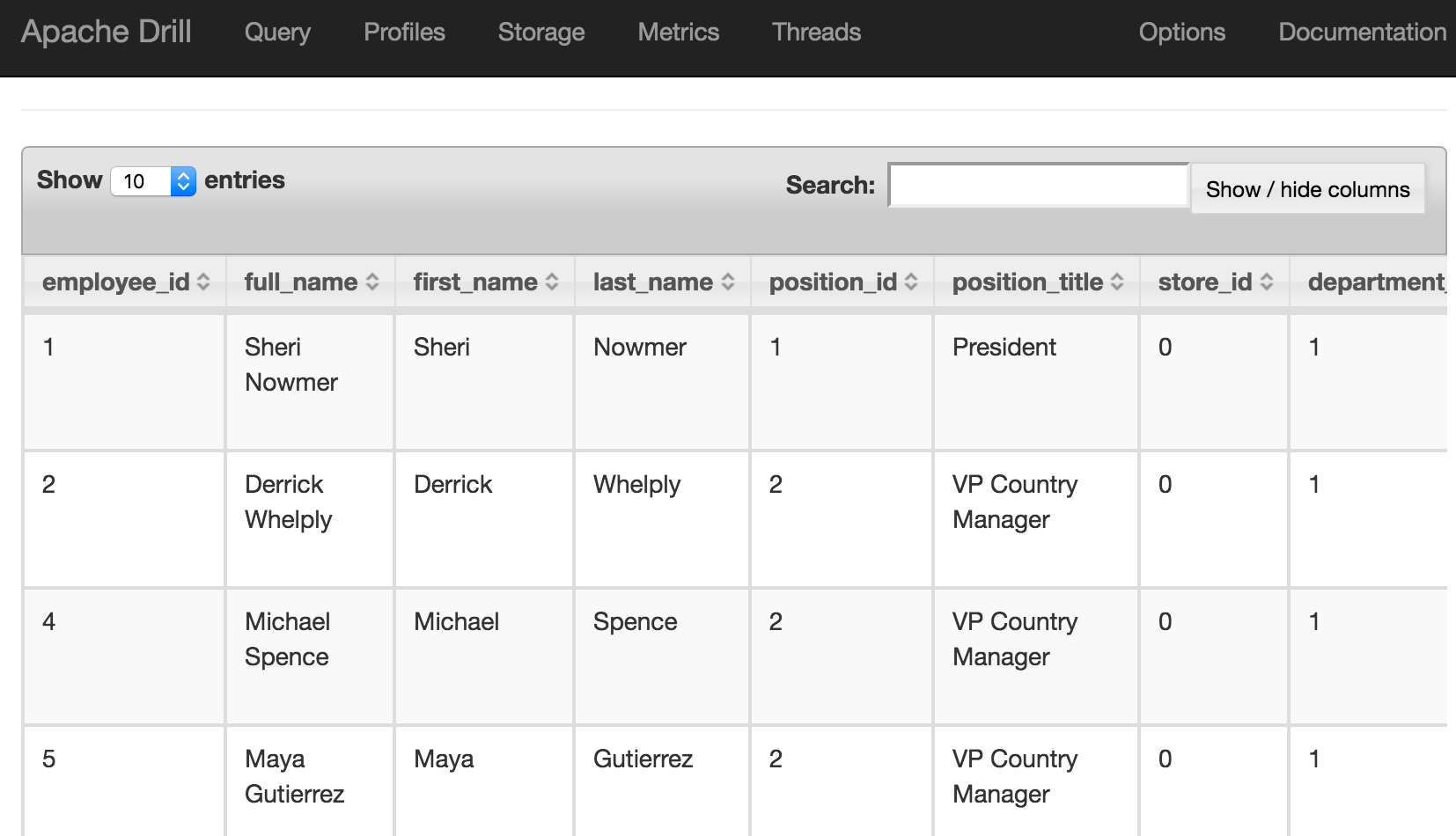
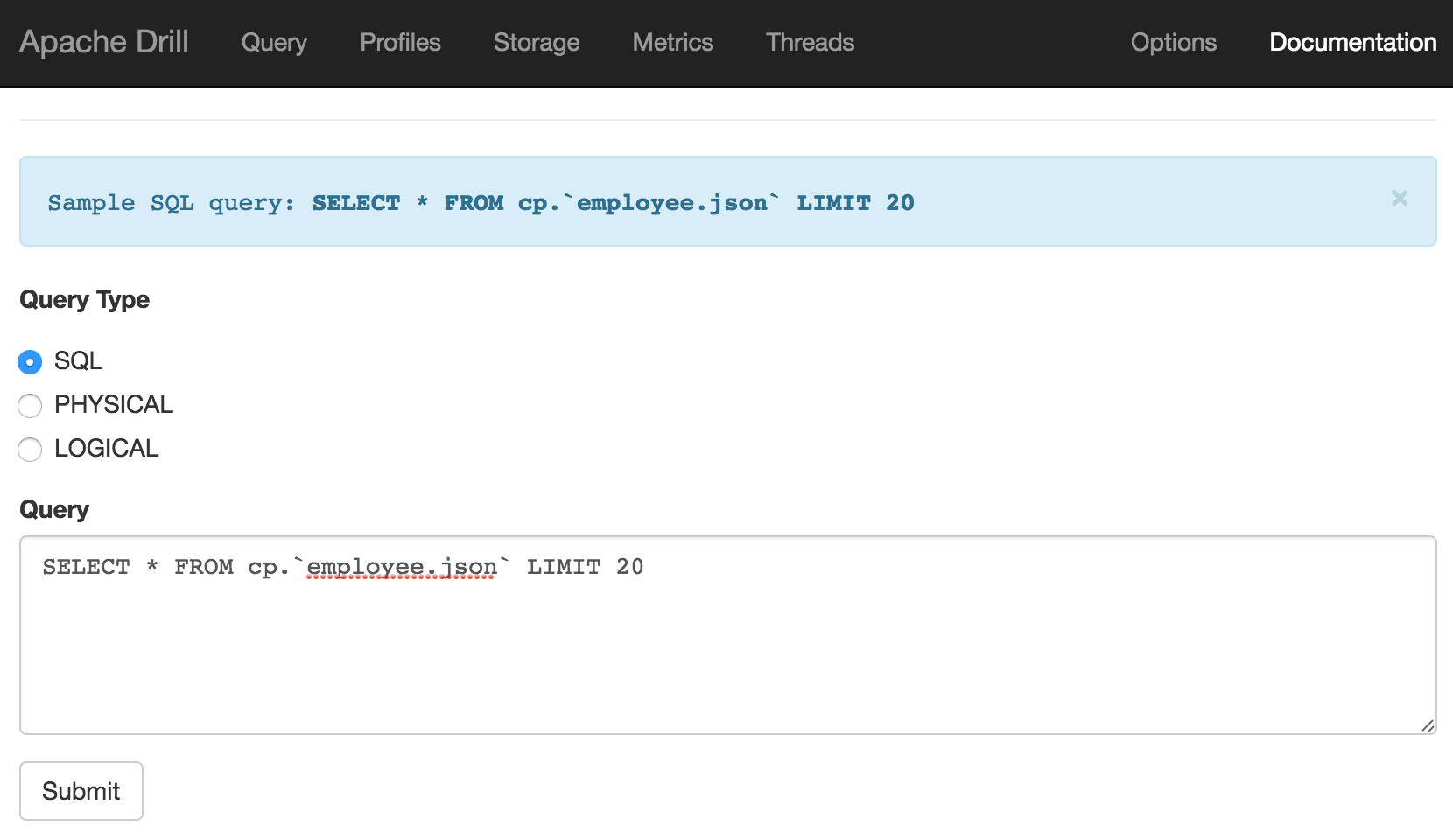
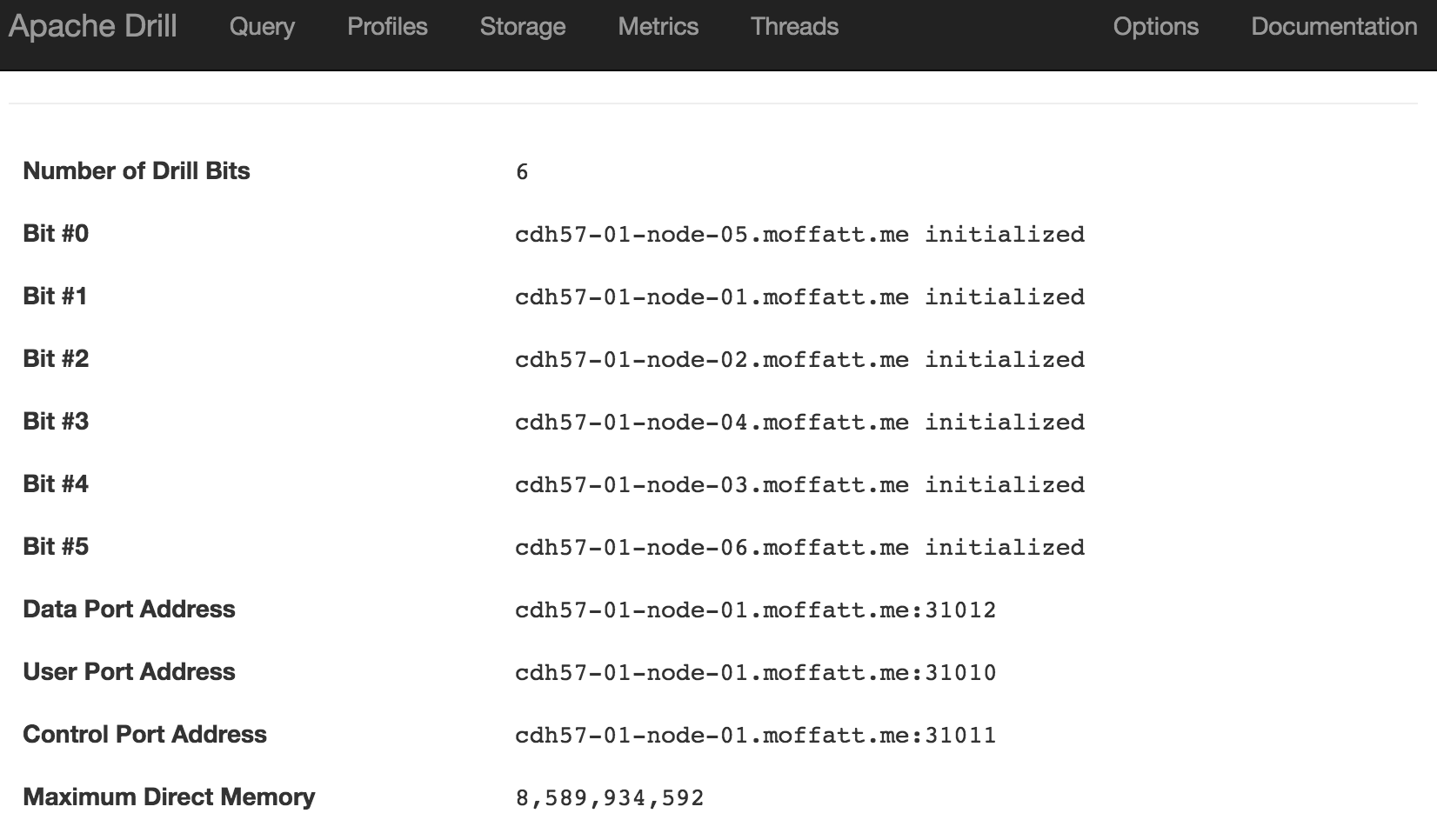
Defining Storage Plugins
From the Drill web interface you can view existing storage plugins, or define new ones. To create a new one, enter its name (for example, hdfs, but could be fred for all that it matters - it's just a label) under New Storage Plugin on the Storage page, and click on Create. Paste the necessary JSON definition in the Configuration box, and then click Create. If you don't want to use the GUI there's also a REST API.
Storage plugin configuration is stored either within Zookeeper (when running Drill distributed), or locally in the sys.store.provider.local.path path when running standalone. By default this is under /tmp which gets cleared down at server reboot. To persist custom storage configurations amend the sys.store.provider.local.path in drill-override.conf, for example:
drill.exec: {
cluster-id: "drillbits1",
zk.connect: "localhost:2181"
sys.store.provider.local.path="/home/oracle/drill/"
}
Working with filesystem data
Here's an example of a storage configuration that enables Drill to access a CDH cluster's HDFS:
{
"type": "file",
"enabled": true,
"connection": "hdfs://cdh57-01-node-01:8020/",
"config": null,
"workspaces": {
"root": {
"location": "/",
"writable": true,
"defaultInputFormat": null
}
},
"formats": {
"csv": {
"type": "text",
"extensions": [
"csv"
],
"delimiter": ","
},
"json": {
"type": "json",
"extensions": [
"json"
]
}
}
}
As well as the connection parameter itself for HDFS, the important bit in this configuration is the formats section. This tells Drill how to interpet files that it finds, without the end-user having to explicitly declare their type.
For the filesystem-based plugin dfs (which can include local files, HDFS, even Amazon S3), you can browse the available "tables":
List the files in HDFS (previously selected with use hdfs;)
0: jdbc:drill:zk=local> show files;
+--------+--------------+---------+---------+--------+-------------+--------------+------------------------+--------------------------+
| name | isDirectory | isFile | length | owner | group | permissions | accessTime | modificationTime |
+--------+--------------+---------+---------+--------+-------------+--------------+------------------------+--------------------------+
| hbase | true | false | 0 | hbase | supergroup | rwxr-xr-x | 1969-12-31 19:00:00.0 | 2016-07-25 14:46:08.212 |
| share | true | false | 0 | hdfs | supergroup | rwxrwxrwx | 1969-12-31 19:00:00.0 | 2016-05-15 12:28:08.152 |
| solr | true | false | 0 | solr | solr | rwxr-xr-x | 1969-12-31 19:00:00.0 | 2016-06-01 18:34:50.716 |
| tmp | true | false | 0 | hdfs | supergroup | rwxrwxrwt | 1969-12-31 19:00:00.0 | 2016-06-24 04:54:41.491 |
| user | true | false | 0 | hdfs | supergroup | rwxrwxrwx | 1969-12-31 19:00:00.0 | 2016-06-21 15:55:59.084 |
| var | true | false | 0 | hdfs | supergroup | rwxr-xr-x | 1969-12-31 19:00:00.0 | 2016-05-11 17:53:29.804 |
+--------+--------------+---------+---------+--------+-------------+--------------+------------------------+--------------------------+
6 rows selected (0.145 seconds)
Show files in a given path:
0: jdbc:drill:zk=local> show files in `/user/oracle`;
+----------------+--------------+---------+---------+---------+---------+--------------+------------------------+--------------------------+
| name | isDirectory | isFile | length | owner | group | permissions | accessTime | modificationTime |
+----------------+--------------+---------+---------+---------+---------+--------------+------------------------+--------------------------+
| .Trash | true | false | 0 | oracle | oracle | rwxr-xr-x | 1969-12-31 19:00:00.0 | 2016-05-23 20:42:34.815 |
| .sparkStaging | true | false | 0 | oracle | oracle | rwxr-xr-x | 1969-12-31 19:00:00.0 | 2016-07-06 03:56:38.863 |
| .staging | true | false | 0 | oracle | oracle | rwx------ | 1969-12-31 19:00:00.0 | 2016-06-01 18:37:04.005 |
| incoming | true | false | 0 | oracle | oracle | rwxr-xr-x | 1969-12-31 19:00:00.0 | 2016-08-03 05:34:12.38 |
| mediademo | true | false | 0 | oracle | oracle | rwxr-xr-x | 1969-12-31 19:00:00.0 | 2016-06-01 18:59:45.653 |
| moviedemo | true | false | 0 | oracle | oracle | rwxr-xr-x | 1969-12-31 19:00:00.0 | 2016-05-15 12:02:55.652 |
| moviework | true | false | 0 | oracle | oracle | rwxr-xr-x | 1969-12-31 19:00:00.0 | 2016-05-15 12:03:01.497 |
| oggdemo | true | false | 0 | oracle | oracle | rwxr-xr-x | 1969-12-31 19:00:00.0 | 2016-05-15 12:03:01.552 |
| oozie-oozi | true | false | 0 | oracle | oracle | rwxr-xr-x | 1969-12-31 19:00:00.0 | 2016-05-15 12:03:01.651 |
+----------------+--------------+---------+---------+---------+---------+--------------+------------------------+--------------------------+
9 rows selected (0.428 seconds)
You can also query across multiple files by specifying a wildcard match. Here's the truncated list of files available:
0: jdbc:drill:zk=cdh57-01-node-01.moffatt.me:> show files in `hdfs`.`/user/rmoff/incoming/twitter/2016/06/17/tweets/`;
+--------------------------+--------------+---------+----------+--------+--------+--------------+--------------------------+--------------------------+
| name | isDirectory | isFile | length | owner | group | permissions | accessTime | modificationTime |
+--------------------------+--------------+---------+----------+--------+--------+--------------+--------------------------+--------------------------+
| FlumeData.1466176113171 | false | true | 1055675 | rmoff | rmoff | rw-r--r-- | 2016-08-10 21:28:27.072 | 2016-06-17 16:08:38.023 |
| FlumeData.1466176113172 | false | true | 1051411 | rmoff | rmoff | rw-r--r-- | 2016-08-05 20:46:51.756 | 2016-06-17 16:08:40.597 |
| FlumeData.1466176113173 | false | true | 1054734 | rmoff | rmoff | rw-r--r-- | 2016-08-05 20:46:51.752 | 2016-06-17 16:08:43.33 |
| FlumeData.1466176113174 | false | true | 1050991 | rmoff | rmoff | rw-r--r-- | 2016-08-05 20:46:51.743 | 2016-06-17 16:08:44.361 |
| FlumeData.1466176113175 | false | true | 1053577 | rmoff | rmoff | rw-r--r-- | 2016-08-05 20:46:51.748 | 2016-06-17 16:08:45.162 |
| FlumeData.1466176113176 | false | true | 1051965 | rmoff | rmoff | rw-r--r-- | 2016-08-05 20:46:51.752 | 2016-06-17 16:08:46.261 |
| FlumeData.1466176113177 | false | true | 1049555 | rmoff | rmoff | rw-r--r-- | 2016-08-05 20:46:51.758 | 2016-06-17 16:08:47.425 |
| FlumeData.1466176113178 | false | true | 1050566 | rmoff | rmoff | rw-r--r-- | 2016-08-05 20:46:51.758 | 2016-06-17 16:08:48.23 |
| FlumeData.1466176113179 | false | true | 1051751 | rmoff | rmoff | rw-r--r-- | 2016-08-05 20:46:51.756 | 2016-06-17 16:08:49.381 |
| FlumeData.1466176113180 | false | true | 1052249 | rmoff | rmoff | rw-r--r-- | 2016-08-05 20:46:51.757 | 2016-06-17 16:08:50.042 |
| FlumeData.1466176113181 | false | true | 1055002 | rmoff | rmoff | rw-r--r-- | 2016-08-05 20:46:51.758 | 2016-06-17 16:08:50.896 |
| FlumeData.1466176113182 | false | true | 1050812 | rmoff | rmoff | rw-r--r-- | 2016-08-05 20:46:51.758 | 2016-06-17 16:08:52.191 |
| FlumeData.1466176113183 | false | true | 1048954 | rmoff | rmoff | rw-r--r-- | 2016-08-05 20:46:51.757 | 2016-06-17 16:08:52.994 |
| FlumeData.1466176113184 | false | true | 1051559 | rmoff | rmoff | rw-r--r-- | 2016-08-05 20:46:51.773 | 2016-06-17 16:08:54.025 |
[...]
Count number of records in one file (FlumeData.1466176113171):
0: jdbc:drill:zk=cdh57-01-node-01.moffatt.me:> SELECT count(*) FROM table(`hdfs`.`/user/rmoff/incoming/twitter/2016/06/17/tweets/FlumeData.1466176113171`(type => 'json'));
+---------+
| EXPR$0 |
+---------+
| 277 |
+---------+
1 row selected (0.798 seconds)
In several files (FlumeData.146617611317*):
0: jdbc:drill:zk=cdh57-01-node-01.moffatt.me:> SELECT count(*) FROM table(`hdfs`.`/user/rmoff/incoming/twitter/2016/06/17/tweets/FlumeData.146617611317*`(type => 'json'));
+---------+
| EXPR$0 |
+---------+
| 2415 |
+---------+
1 row selected (2.466 seconds)
In all files in the folder (*):
0: jdbc:drill:zk=cdh57-01-node-01.moffatt.me:> SELECT count(*) FROM table(`hdfs`.`/user/rmoff/incoming/twitter/2016/06/17/tweets/*`(type => 'json'));
+---------+
| EXPR$0 |
+---------+
| 7414 |
+---------+
1 row selected (3.867 seconds)
And even across multiple folders:
0: jdbc:drill:zk=cdh57-01-node-01.moffatt.me:> SELECT count(*) FROM table(`hdfs`.`/user/flume/incoming/twitter/2016/06/*/*`(type => 'json'));
+---------+
| EXPR$0 |
+---------+
| 206793 |
+---------+
1 row selected (87.545 seconds)
Querying data without an identifying extension
Drill relies on the format clause of the storage extension configurations in orer to determine how to interpret files based on their extensions. You won't always have that luxury of extensions being available, or being defined. If you try and query such data, you'll not get far. In this example I'm querying data on HDFS that's in JSON format but without the .json suffix:
0: jdbc:drill:zk=cdh57-01-node-01.moffatt.me:> SELECT text FROM `hdfs`.`/user/rmoff/incoming/twitter/2016/06/17/tweets/FlumeData.1466176113171` limit 5;
Error: VALIDATION ERROR: From line 1, column 18 to line 1, column 23: Table 'hdfs./user/rmoff/incoming/twitter/2016/06/17/tweets/FlumeData.1466176113171' not found
SQL Query null
Fear not - you can declare them as part of the query syntax.
0: jdbc:drill:zk=cdh57-01-node-01.moffatt.me:> SELECT text FROM table(`hdfs`.`/user/rmoff/incoming/twitter/2016/06/17/tweets/FlumeData.1466176113171`(type => 'json')) limit 5;
+------+
| text |
+------+
| RT @jjkukrl: susu bayi jg lagi mahal nih ugh ayah harus semangat cari duit ^^9 https://t.co/2NvTOShRbI |
| Oracle Java 1Z0-808 Web Exam Simulator https://t.co/tZ3gU8EMj3 |
| @TribuneSelatan ahaha kudu gaya atuh da arek lebarann ahahaha |
| Short impression of yesterday's speech. What a great day it was! #lifeatoracle #team #salesincentive #oracle https://t.co/SVK2ovOe3U |
| Want to work at Oracle? We're #hiring in New York! Click for details: https://t.co/NMTo1WMHVw #Sales #Job #Jobs #CareerArc |
+------+
5 rows selected (1.267 seconds)
Storage Configuration - Oracle
Per the documentation it's easy to query data residing in a RDBMS, such as Oracle. Simply copy the JDBC driver into Apache Drill's jar folder:
cp /u01/app/oracle/product/12.1.0.2/dbhome_1/jdbc/lib/ojdbc7.jar /opt/apache-drill-1.7.0/jars/3rdparty/
And then add the necessary storage configuration, which I called ora:
{
"type": "jdbc",
"driver": "oracle.jdbc.OracleDriver",
"url": "jdbc:oracle:thin:moviedemo/welcome1@localhost:1521/ORCL",
"username": null,
"password": null,
"enabled": true
}
If you get an error Please retry: error (unable to create/ update storage) then check that the target Oracle database is up, the password is correct, and so on.
You can then query the data within Hive:
0: jdbc:drill:zk=local> use ora.MOVIEDEMO;
+-------+--------------------------------------------+
| ok | summary |
+-------+--------------------------------------------+
| true | Default schema changed to [ora.MOVIEDEMO] |
+-------+--------------------------------------------+
1 row selected (0.205 seconds)
0: jdbc:drill:zk=local> show tables;
+----------------+-----------------------------+
| TABLE_SCHEMA | TABLE_NAME |
+----------------+-----------------------------+
| ora.MOVIEDEMO | ACTIVITY |
| ora.MOVIEDEMO | BDS_CUSTOMER_RFM |
| ora.MOVIEDEMO | BUSINESS_REVIEW_SUMMARY |
[...]
0: jdbc:drill:zk=local> select * from ACTIVITY limit 5;
+--------------+---------+
| ACTIVITY_ID | NAME |
+--------------+---------+
| 3.0 | Pause |
| 6.0 | List |
| 7.0 | Search |
| 8.0 | Login |
| 9.0 | Logout |
+--------------+---------+
5 rows selected (1.644 seconds)
If you get Error: DATA_READ ERROR: The JDBC storage plugin failed while trying setup the SQL query. then enable verbose errors in Apache Drill to see what the problem is:
0: jdbc:drill:zk=local> ALTER SESSION SET `exec.errors.verbose` = true;
+-------+-------------------------------+
| ok | summary |
+-------+-------------------------------+
| true | exec.errors.verbose updated. |
+-------+-------------------------------+
1 row selected (0.154 seconds)
0: jdbc:drill:zk=local> select * from ora.MOVIEDEMO.YELP_BUSINESS limit 1;
Error: DATA_READ ERROR: The JDBC storage plugin failed while trying setup the SQL query.
sql SELECT *
FROM "MOVIEDEMO"."YELP_BUSINESS"
plugin ora
Fragment 0:0
[Error Id: 40343dd5-1354-48ed-90ef-77ae1390411b on bigdatalite.localdomain:31010]
(java.sql.SQLException) ORA-29913: error in executing ODCIEXTTABLEOPEN callout
ORA-29400: data cartridge error
KUP-11504: error from external driver: MetaException(message:Could not connect to meta store using any of the URIs provided. Most recent failure: org.apache.thrift.transport.TTransportException: java.net.ConnectException: Connection refused
Here the problem was with the external table that Oracle was querying (ORA-29913: error in executing ODCIEXTTABLEOPEN). It's actually an Oracle external table over a Hive table, which obviously Drill could be querying directly - but hey, we're just sandboxing here...
Query Execution
Just as Oracle has its Cost Based Optimiser (CBO) which helps it determine how to execute a query, and do so most efficiently, Apache Drill has an execution engine that determines how to actually execute the query you give it. This also includes how to split it up over multiple nodes ("drillbits") if available, as well as optimisations such as partition pruning in certain cases. You can read more about how the query execution works here, and view the explain plan for a query using explain plan :
0: jdbc:drill:zk=local> !set maxwidth 10000
0: jdbc:drill:zk=local> explain plan for select `date`,count(*) as tip_count from `/user/oracle/incoming/yelp/tip_json/yelp_academic_dataset_tip.json` group by `date` order by 2 desc limit 5;
+------+------+
| text | json |
+------+------+
| 00-00 Screen
00-01 Project(date=[$0], tip_count=[$1])
00-02 SelectionVectorRemover
00-03 Limit(fetch=[5])
00-04 SelectionVectorRemover
00-05 TopN(limit=[5])
00-06 HashAgg(group=[{0}], tip_count=[$SUM0($1)])
00-07 HashAgg(group=[{0}], tip_count=[COUNT()])
00-08 Scan(groupscan=[EasyGroupScan [selectionRoot=hdfs://localhost:8020/user/oracle/incoming/yelp/tip_json/yelp_academic_dataset_tip.json, numFiles=1, columns=[`date`], files=[hdfs://localhost:8020/user/oracle/incoming/yelp/tip_json/yelp_academic_dataset_tip.json]]])
| {
"head" : {
"version" : 1,
"generator" : {
"type" : "ExplainHandler",
"info" : ""
[...]
You can also use the Drill web interface to see information about how a query executed:
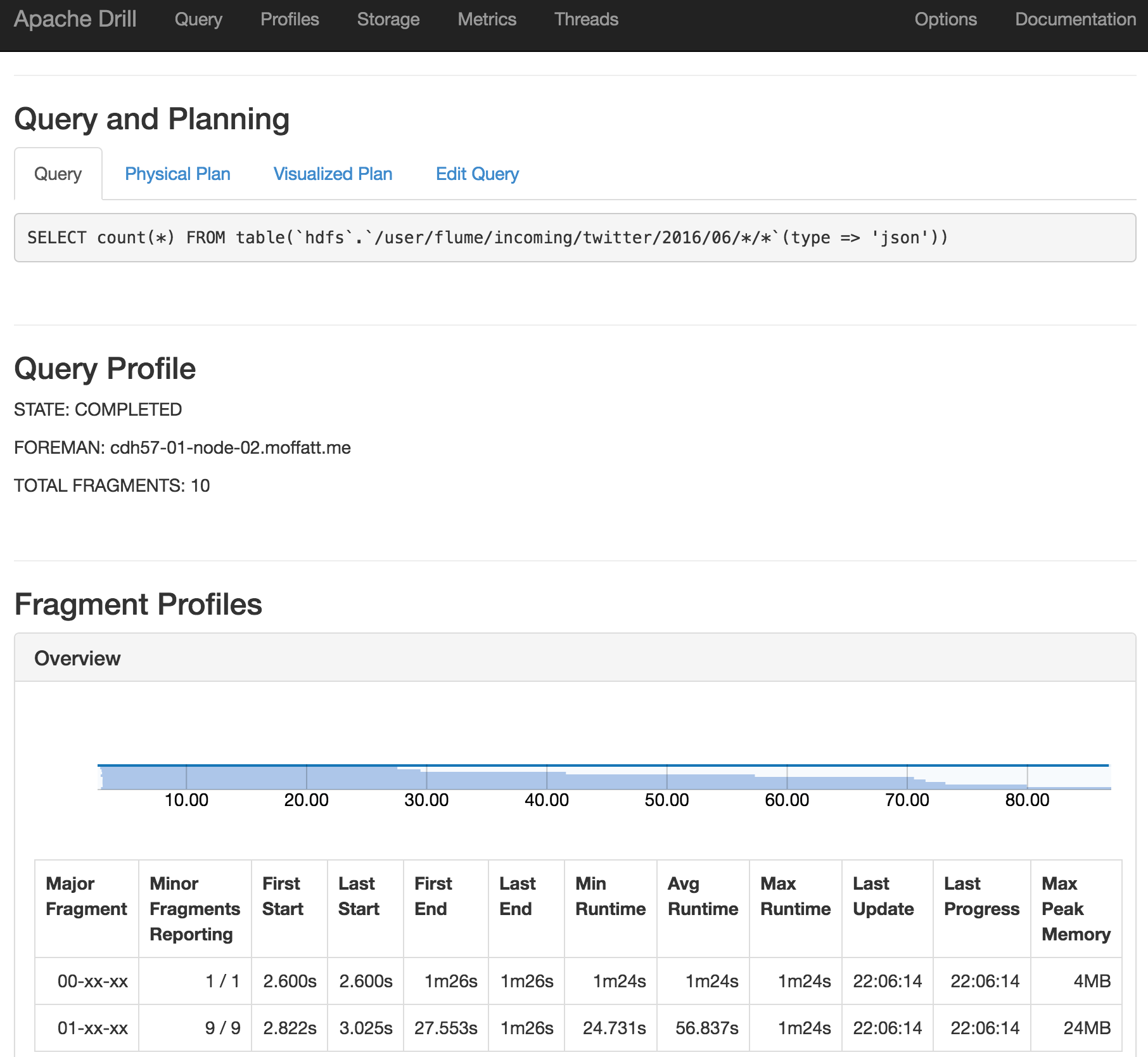
Drill Explorer
The MapR Drill ODBC driver comes with a tool called Drill Explorer. This is a GUI that enables you to explore the data by navigating the databases (==storage plugins) and folders/files within, previewing the data and even creating views on it.
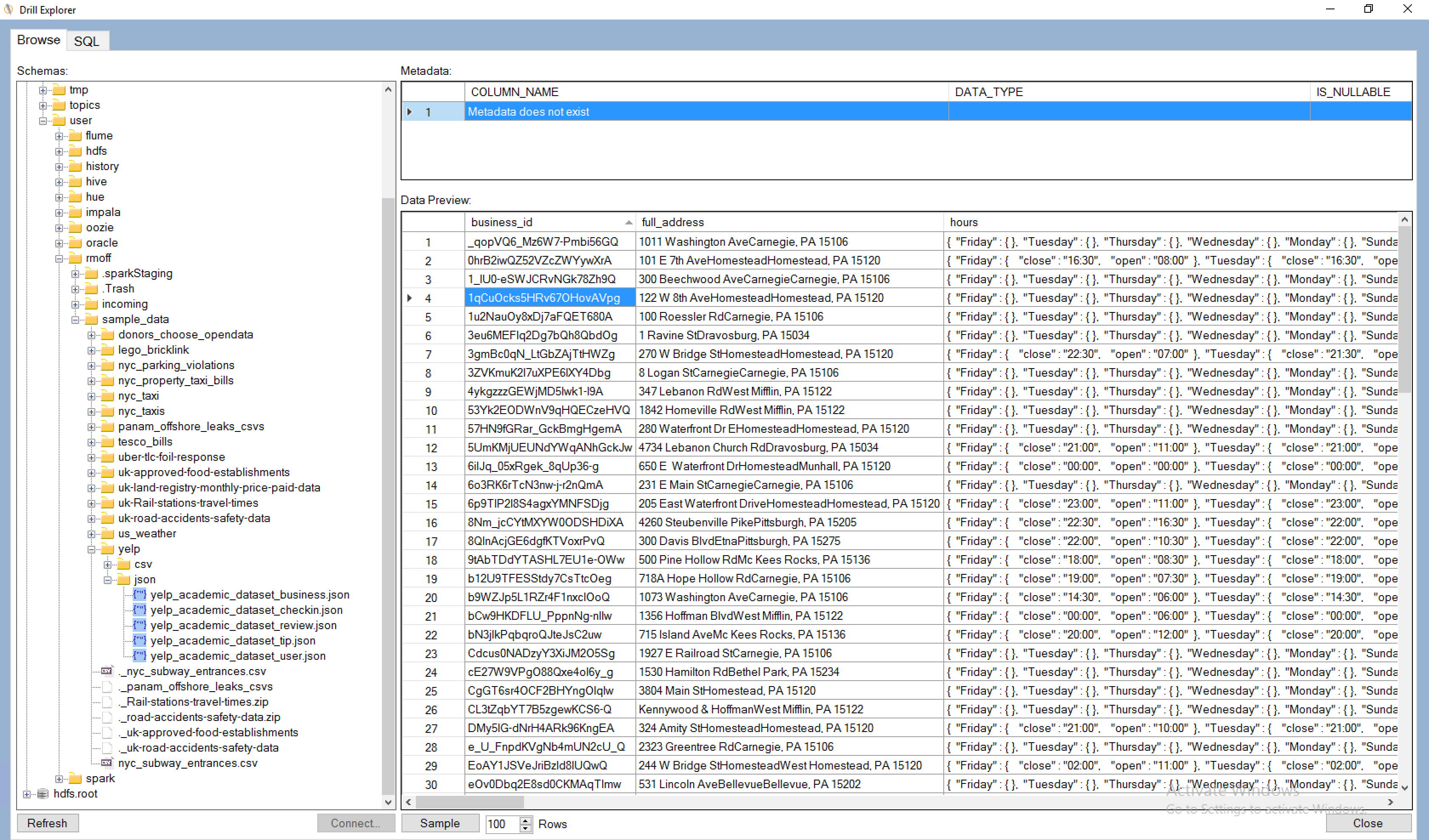
Drill Client
Within the Drill client there are various settings available:
0: jdbc:drill:zk=local> !set
autocommit true
autosave false
color true
fastconnect true
force false
headerinterval 100
historyfile /home/oracle/.sqlline/history
incremental true
isolation TRANSACTION_REPEATABLE_READ
maxcolumnwidth 15
maxheight 56
maxwidth 1000000
numberformat default
outputformat table
propertiesfile /home/oracle/.sqlline/sqlline.properties
rowlimit 0
showelapsedtime true
showheader true
shownestederrs false
showwarnings true
silent false
timeout -1
trimscripts true
verbose false
To change one, such as the width of output displayed:
0: jdbc:drill:zk=local> !set maxwidth 10000
To connect to remote Drill specify the Zookeeper node(s) that store the Drillbit connection information:
rmoff@asgard-3:apache-drill-1.7.0> bin/sqlline -u jdbc:drill:zk=cdh57-01-node-01.moffatt.me:2181,cdh57-01-node-02.moffatt.me:2181,cdh57-01-node-03.moffatt.me:2181
Conclusion
Apache Drill is a powerful tool for using familiar querying language (SQL) against different data sources. On a small scale, simply being able to slice and dice through structured files like JSON is a massive win. On a larger scale, it will be interesting to experiment with how Apache Drill compares when querying larger volumes of data across a cluster of machines, maybe compared to a tool such as Impala.
For more information about Apache Drill see how to access Drill from within OBIEE, as well as bonus geeky blog coming soon explaining the debug tools I used to try and figure out why it wouldn't initially work...
Stream Analytics and Processing with Kafka and Oracle Stream Analytics
In my previous post I looked the latest release of Oracle Stream Analytics (OSA), and saw how it provided a graphical interface to “Fast Data”. Users can analyse streaming data as it arrives based on conditions and rules. They can also transform the stream data, publishing it back out as a stream in its own right. In this article we’ll see how OSA can be used with Kafka.
Kafka is one of the foremost streaming technologies nowadays, for very good reasons. It is highly scalable and flexible, supporting multiple concurrent consumers. Oracle Streaming Analytics supports Kafka as both a source and target. To set up an inbound stream from Kafka, first we define the Connection:


Once the Connection is defined, we can create a Stream for a given Kafka topic:

If you get an error at this point of Unable to deploy OEP application then check the OSA log – it could be a connectivity issue to Zookeeper.
Exception in thread "SpringOsgiExtenderThread-286" org.springframework.beans.FatalBeanException: Error in context lifecycle initialization; nested exception is com.bea.wlevs.ede.api.EventProcessingException: org.I0Itec.zkclient.exception.ZkTimeoutException: Unable to connect to zookeeper server within timeout: 6000
Assuming that the Stream is saved with no errors, you can then create an Exploration based on the stream and all being well, the live tweets are soon shown. Unlike the example at the top of this article, these tweets are coming in via Kafka, rather than the built-in OSA Twitter Stream. This is partly to demonstrate the Kafka capabilities, but also because the built-in OSA Twitter Stream only includes a subset of the available twitter data fields.

Avro? Nope.
Data in Kafka can be serialised in many formats, including Avro – which OSA doesn’t seem to like. No error is thrown to the GUI but the exploration remains blank.

Looking in the OSA log file there’s a whole lot of errors recorded similar to this:
line 1:0 no viable alternative at character '?' line 1:1 no viable alternative at character '?' line 1:2 no viable alternative at character '?' line 1:3 no viable alternative at character '?' line 1:4 no viable alternative at character '?' line 1:5 no viable alternative at character '?' line 1:6 no viable alternative at character '?' line 1:7 no viable alternative at character '?' line 1:8 no viable alternative at character ''
JSON? Kinda.
One of the challenges that I found working with OSA was defining the “Shape” (data model) of the inbound stream data. JSON is a format used widely as a technology-agnostic data interchange format, including for the twitter data that I was working with. You can see a sample record here. One of the powerful features of JSON is its ability to nest objects in a record, as well as create arrays of them. You can read more about this detail in a recent article I wrote here. Unfortunately it seems that OSA does not support flattening out JSON, meaning that only elements in the root of the model are accessible. For twitter, that means we can see the text, and who it was in reply to, but not the user who tweeted it, since the latter is a nested element (along with many other fields, including hashtags which are also an array):
root |-- created_at: string (nullable = true) |-- entities: struct (nullable = true) | |-- hashtags: array (nullable = true) | | |-- element: struct (containsNull = true) | | | |-- indices: array (nullable = true) | | | | |-- element: long (containsNull = true) | | | |-- text: string (nullable = true) | |-- user_mentions: array (nullable = true) | | |-- element: struct (containsNull = true) | | | |-- id: long (nullable = true) | | | |-- id_str: string (nullable = true) | | | |-- indices: array (nullable = true) | | | | |-- element: long (containsNull = true) | | | |-- name: string (nullable = true) | | | |-- screen_name: string (nullable = true) |-- source: string (nullable = true) |-- text: string (nullable = true) |-- timestamp_ms: string (nullable = true) |-- truncated: boolean (nullable = true) |-- user: struct (nullable = true) | |-- followers_count: long (nullable = true) | |-- following: string (nullable = true) | |-- friends_count: long (nullable = true) | |-- name: string (nullable = true) | |-- screen_name: string (nullable = true)
So what to do if the inbound streaming data is in nested-JSON format? It seems to me the only option is to pre-process it to flatten it. There are a variety of tools that could be used here – in the first instance I’d generally reach for Logstash, it being the one I’m most familiar with. To get an idea of the schema of a JSON record you can use jsonschema.net. Funnily enough when I was researching this blog post I came across the exact same problem on a forum posted by … me! Early last year I was working with the same dataset, and had the same issue with embedded arrays. The way to do it in Logstash is with a bit of Ruby code to flatten the arrays, and a standard mutate to bring nested objects up to the root level. Sample code:
mutate {
add_field => { "user_name" => "%{[user][name]}" }
add_field => { "user_screen_name" => "%{[user][screen_name]}" }
}
ruby {
code => 'event["hashtags_array"] = event["[entities][hashtags]"].collect { |m| m["text"] } unless event["[entities][hashtags]"].nil?
event["hashtags_list"] = event["hashtags_array"].join(",") unless event["[hashtags_array]"].nil?'
}
You can find the full Logstash code on gist here. With this logstash code running I set up a new OSA Stream pointing to the new Kafka topic that Logstash was writing, and added the flattened fields to the Shape:

We can then see in the Exploration the fields that we wanted to get at – user name, hashtags, and so on:

Other Shape Gotchas
One of the fields in Twitter data is ‘source’ – which unfortunately is a reserved identifier in the CQL language that OSA uses behind the scenes.
Caused By: org.springframework.beans.FatalBeanException: Exception initializing channel; nested exception is com.bea.wlevs.ede.api.ConfigurationException: Event type [sx-10-16-Kafka_Technology_Tweets_JSON-1] of channel [channel] uses invalid or reserved CQL identifier = , source
It’s not clear how to define a shape in which the source data field is named after a reserved identifier.
Further Exploration of Twitter Streams with OSA
Using the flattened Twitter stream coming via Kafka that I demonstrated above, let’s now look at more OSA functionality.
Depending on the source of your data stream, and your purpose for analysing it, you may well want to filter out certain content. This can be done from the Exploration screen:

The Business Rules section of the Exploration enables you to define rules about the data and set field values based on it. This can be static values, or expressions based on data in the stream. There doens’t seem to be a way to add arbitrary fields via this, so I amended the Stream Shape to include a ‘spare’ field that I then populated:


Kafka Stream Transformation with OSA
Here we’ll see how OSA can be used to ingest one Kafka topic, apply a transformation, and stream it to another Kafka topic.
The OSA exploration screen offers a basic aggregation (‘summary’) function, here showing the number of tweets per language:

Using the Windows icon to the right of the Sources box the time window can be defined, along with the refresh frequency:

This means that the count of tweets per language will be calculated looking at the data for the past 30 seconds, and this will be evaluated every five seconds. More complex functionality such as pivoting on the group-by column (so as to be able to chart out the number of tweets per language as separate metrics) doesn’t seem to be present in this release; arguably this is moving over into per analytics territory such as would be found in Oracle’s Big Data Discovery.
Taking the summarised stream (count of tweets, by language) I first Publish the exploration, making it available for use as the input to a subsequent exploration. Then from the Catalog page select a Pattern, which I’m going to use to build a stream showing the most common languages in the past five seconds. With the Top N pattern you specify the event stream (in this case, the summarised stream that I built above), and the metric by which to order the events which here is the count of tweets per language.

For completeness, I’m going to stream the output of this pattern exploration back to a Kafka topic


Note that I’ve defined a new Shape here based on the columns in the pattern. In the pattern itself I renamed the COUNT column to a clearer one (tweet_count_5_sec). Renaming it wasn’t strictly necessary since it’s possible to define the field/shape mapping when you configure the Target:

For the target to take effect, I publish the pattern exploration, and then using kafka-console-consumer can see the topic being populated in realtime by OSA:

Being able to apply transformations to streams in realtime like this and stream the results is pretty useful. There are some limitations to the capabilities of OSA through the front end GUI. For example, support for nested json, and integration with the Kafka Schema Registry to automatically derive Shapes for inbound topics would both be great. Lower-level, the option to specify the consumer group id, as well as the start point for consumption (beginning of topic, or streaming at the end) are both things that would probably be necessary sooner or later using OSA for full-blown development.
OSA and Spatial
One of the Patterns that OSA provides is a Spatial one, which can be used to analyse source data that includes geo-location data. This could be to simply plot the occurrence of the data point (as we’ll see shortly) on a map. It can also be used in a more sophisticated manner, to track a given entity’s movements on a map. An example of this could be a fleet of trucks reporting their position back at regular intervals. Areas on a map can be defined and conditions triggered as the entity enters or leaves the area. For now though, we’ll keep it simple. Using the flattened Twitter stream from Kafka that I produced from Logstash above, I’m going to plot Tweets in realtime on a map, along with a very simplistic tagging of the broad area in which they came from.
In my source Kafka topic I have two fields, latitude and longitude. I expose these as part of the ‘flattening’ of the JSON in this logstash script, since by default they’re nested within the coordinates field and as an array too. When defining the Stream’s Shape make sure you define the datatype correctly (Double) – OSA is not very forgiving of stupidity and I spent a frustrating time trying to work out why “-80.1422195” was coming through as zero – obviously defined as an Integer this was never going to work!
Not entirely necessary, but useful for debug purposes, I setup an exploration based on the flattened Twitter stream, with a filter to only include tweets that had geo-location data in them. This way I knew what tweets I should expect to be seeing in the next step. One of the things that I have found with OSA is that it has a tendency to fail silently; instead of throwing errors you’ll just not get any data. By setting up the filter exploration I could at least debug things a bit more easily.

After this I created a new object, a Map. A Map object defines a set of named areas, which could be sourced from a database table, or drawn manually – which is what I did here by setting the Map Type to ‘None (Create Manually)’. One thing to note about the maps is that they’re sourced online (openstreetmap.org) so you’ll need an internet connection to do this. Once the Map is open, click the Polygon Tool icon and click-drag a shape around the area that you want to “geo-fence”. Each area is given a name, and this is what is used in the streaming data to label the event’s geographical area.

Having got our source data stream with geo-data in, and a Map on which to plot it and analyse the location of each event, we now use the Spatial General pattern to create an Exploration. The topology looks like this:

The fields in the Spatial General pattern are all pretty obvious. Object key is the field to use to track the same entity across multiple events, if you want to use the enter/exit/stay statuses. For tweets we just use ‘Enter’, but for people or vehicles, for example, you might get multiple status reports and want to track them on a map. For example, when a person is near a point of interest that you’re tracking, or a vehicle has remained in a set area for too long.

If you let the Exploration now run, depending on the rate of event ingest, you’ll sooner or later see points appearing on the map and event details underneath. The “status” column is populated (blank if the event is outside of the defined geo-fences), as is the “Place”, based on the geo-fence names that you defined.

Summary
I can see OSA being used in two ways. The first as an ‘endpoint’ for streams with users taking actions based on the data, with some of the use cases listed here. The second is for prototyping transformations and analyses on streams prior to productionising them. The visual interface and immediacy of feedback on transformations applied means that users can quickly understand what further processing they may want to apply to the stream using actual streaming data to inform this.
This latter concept – that of prototyping – is similar to that which we see with another of Oracle’s products, Big Data Discovery. With BDD users can analyse data in the organisation’s data reservoir, as well as apply transformations to it (read more). Just as BDD doesn’t replace OBIEE or Visual Analyzer but enables users to understand how they do want to model the data in these tools, OSA wouldn’t replace “production grade” integration done by Oracle Data Integrator. What it would do is allow users to get a clearer idea of the transformations they would want performed in it.
OSA’s user interface is easy to use and intuitive, and this is definitely a tool that you would put in front of technically minded business users. There are limitations to what can be achieved technically through the web GUI alone and something like Oracle Data Integrator (ODI) would still be a more appropriate fit for complex streaming work. At Oracle Open World last year it was announced (slides) that a beta would be starting for ODI using Spark Streaming for ETL and stream processing, so it’ll be interesting to see this when it comes out.
Further Reading
- Providing Oracle Stream Analytics 12c environment using Docker, by Guido Schmutz
- Real-Time Data Streaming & Exploration with Oracle GoldenGate & Oracle Stream Analytics, by Issam Hijazi
- Demonstration of Oracle Stream Explorer for live device monitoring – collect, filter, aggregate, pattern match, enrich and publish by Lucas Jellema
- OTN OSA home page
- Documentation index
The post Stream Analytics and Processing with Kafka and Oracle Stream Analytics appeared first on Rittman Mead Consulting.

