What we call a complex SQL SELECT statement really depends on the context. When talking about translating SQL queries into ODI Mappings, pretty much anything that goes beyond a trivial SELECT * FROM <a_single_source_table> can be called complex.
SQL statements are meant for humans to be written and for RDBMS servers like Oracle Database to be understood and executed. RDBMS servers benefit from a wealth of knowledge about the database we are querying and are willing to give us a lot of leeway about how we write those queries, to make it as easy as possible for us. Let me show you what I mean:
SELECT
FIRST_NAME,
AGE - '5' LIE_ABOUT_YOUR_AGE,
REGION.*
FROM
CUSTOMER
INNER JOIN REGION ON "CUSTOMER_REGION_ID" = REGION.REGION_ID
We are selecting from two source tables, yet we have not bothered about specifying source tables for columns (apart from one instance in the filter). That is fine - the RDBMS server can fill that detail in for us by looking through all source tables, whilst also checking for column name duplicates. We can use numeric strings like '567' instead of proper numbers in our expressions, relying on the server to perform implicit conversion. And the * will always be substituted with a full list of columns from the source table(s).
All that makes it really convenient for us to write queries. But when it comes to parsing them, the convenience becomes a burden. However, despite lacking the knowledge the the RDBMS server possesses, we can still successfully parse and then generate an ODI Mapping for quite complex SELECT statements. Let us have a look at our Sql2Odi translator handling various challenges.
Rittman Mead's Sql2Odi Translator in Action
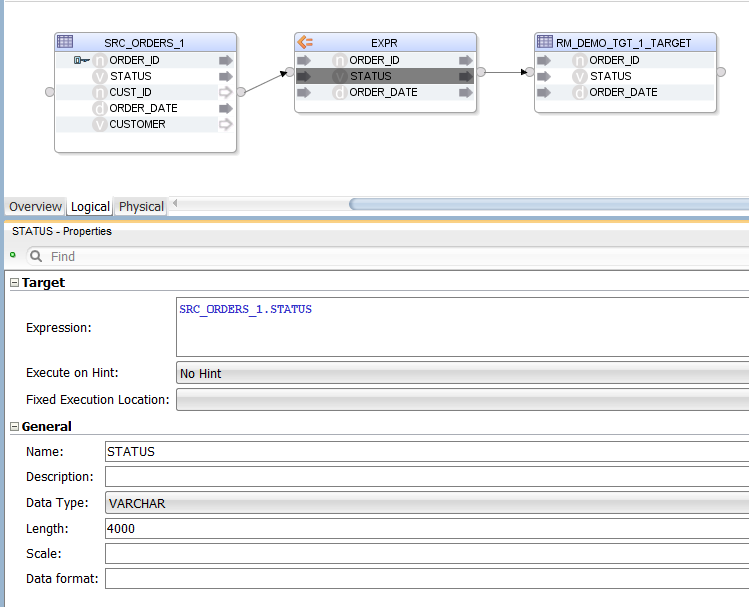
Let us start with the simplest of queries:
SELECT
ORDER_ID,
STATUS,
ORDER_DATE
FROM
ODI_DEMO.SRC_ORDERS
The result in ODI looks like this:
Sql2Odi has created an Expression, in which we have the list of selected columns. The columns are mapped to the target table by name (alternatively, they could be mapped by position). The target table is provided in the Sql2Odi metadata table along with the SELECT statement and other Mapping generation related configuration.
Can we replace the list of columns in the SELECT list with a *?
SELECT * FROM ODI_DEMO.SRC_ORDERS
The only difference from the previously generated Mapping is that the Expression now has a full list of source table columns. We could not get the list of those columns while parsing the statement but we can look them up from the source ODI Datastore when generating the mapping. Groovy!
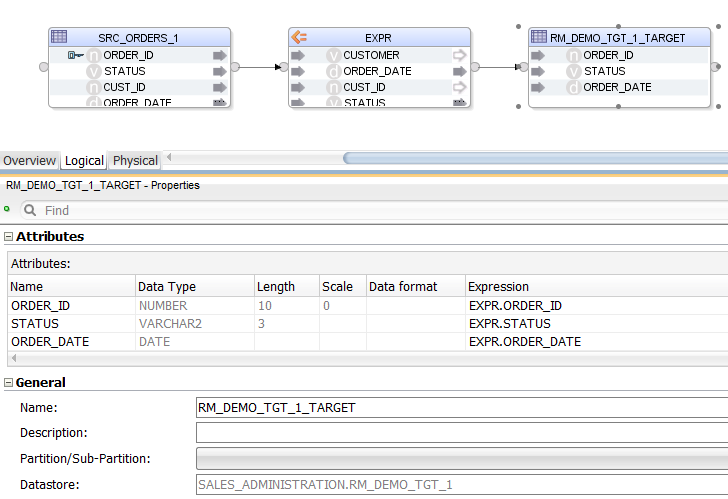
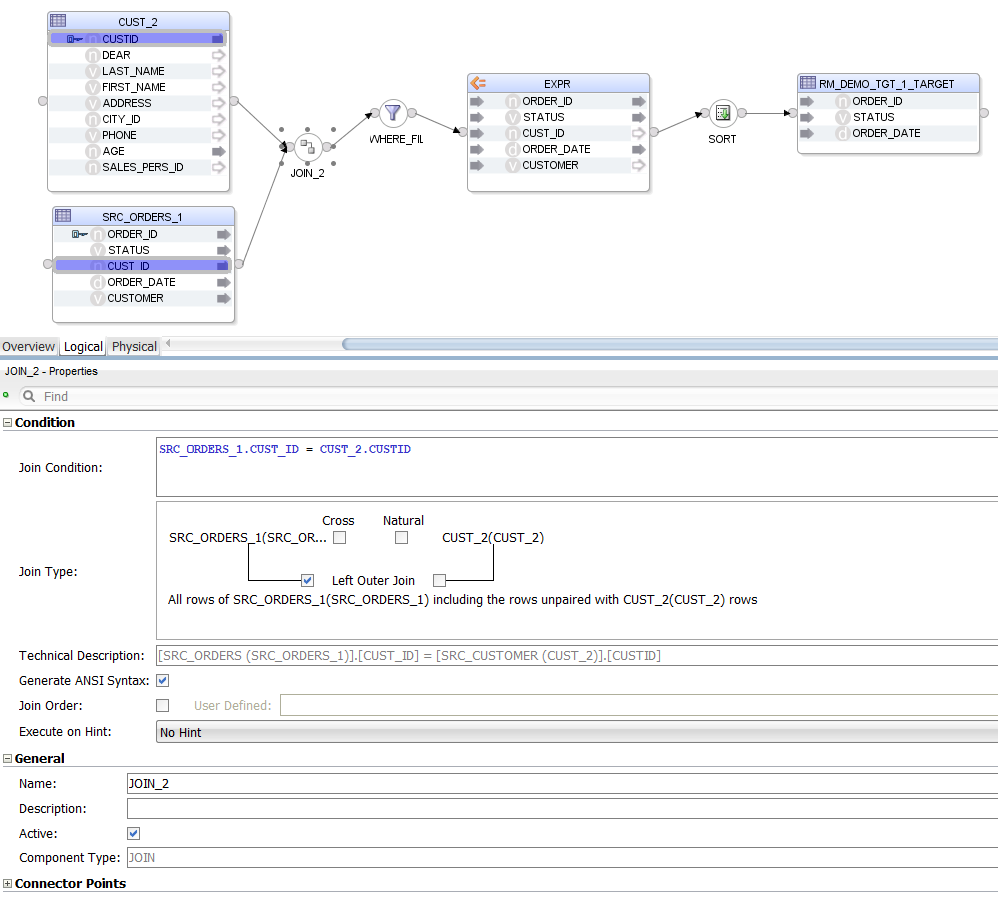
Let us increase the complexity by adding a JOIN, a WHERE filter and an ORDER BY clause to the mix:
SELECT
SRC_ORDERS.*
FROM
ODI_DEMO.SRC_ORDERS
LEFT JOIN ODI_DEMO.SRC_CUSTOMER CUST ON
SRC_ORDERS.CUST_ID = CUST.CUSTID
WHERE
CUST.AGE BETWEEN 20 AND 50
ORDER BY CUST.AGE
The Mapping looks more crowded now. Notice that we are selecting * from one source table only - again, that is not something that the parser alone can handle.
We are not using ODI Mapping Datasets - a design decision was made not to use them because of the way Sql2Odi handles subqueries.
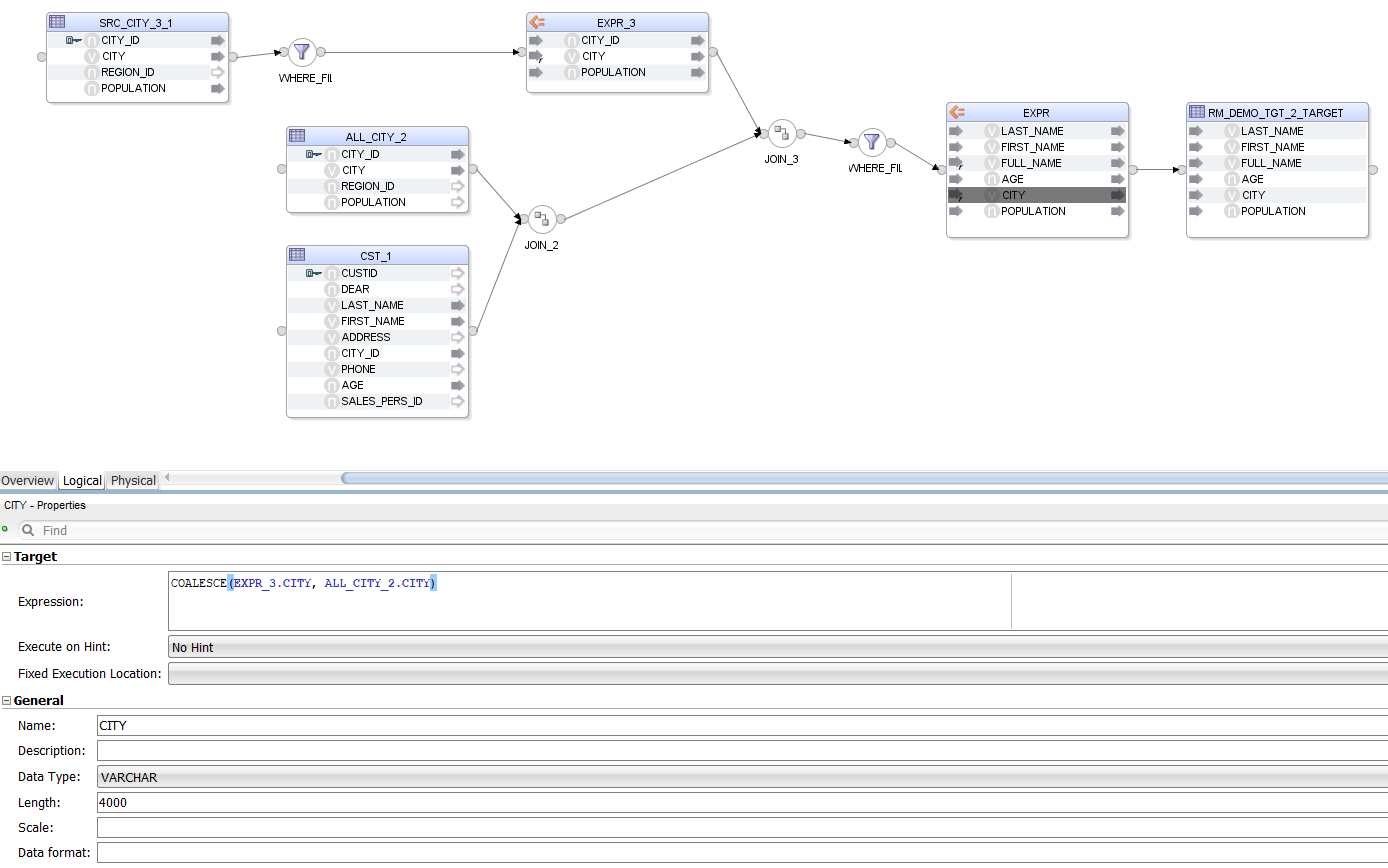
Speaking of subqueries, let us give them a try - in the FROM clause you can source your data not only from tables but also from sub-SELECT statements or subqueries.
SELECT
LAST_NAME,
FIRST_NAME,
LAST_NAME || ' ' || FIRST_NAME AS FULL_NAME,
AGE,
COALESCE(LARGE_CITY.CITY, ALL_CITY.CITY) CITY,
LARGE_CITY.POPULATION
FROM
ODI_DEMO.SRC_CUSTOMER CST
INNER JOIN ODI_DEMO.SRC_CITY ALL_CITY ON ALL_CITY.CITY_ID = CST.CITY_ID
LEFT JOIN (
SELECT
CITY_ID,
UPPER(CITY) CITY,
POPULATION
FROM ODI_DEMO.SRC_CITY
WHERE POPULATION > 750000
) LARGE_CITY ON LARGE_CITY.CITY_ID = CST.CITY_ID
WHERE AGE BETWEEN 25 AND 45
As we can see, a sub-SELECT statement is handled the same way as a source table, the only difference being that we also get a WHERE Filter and an Expression that together give us the data set of the subquery. All Components representing the subquery are suffixed with a 3 or _3_1 in the Mapping.
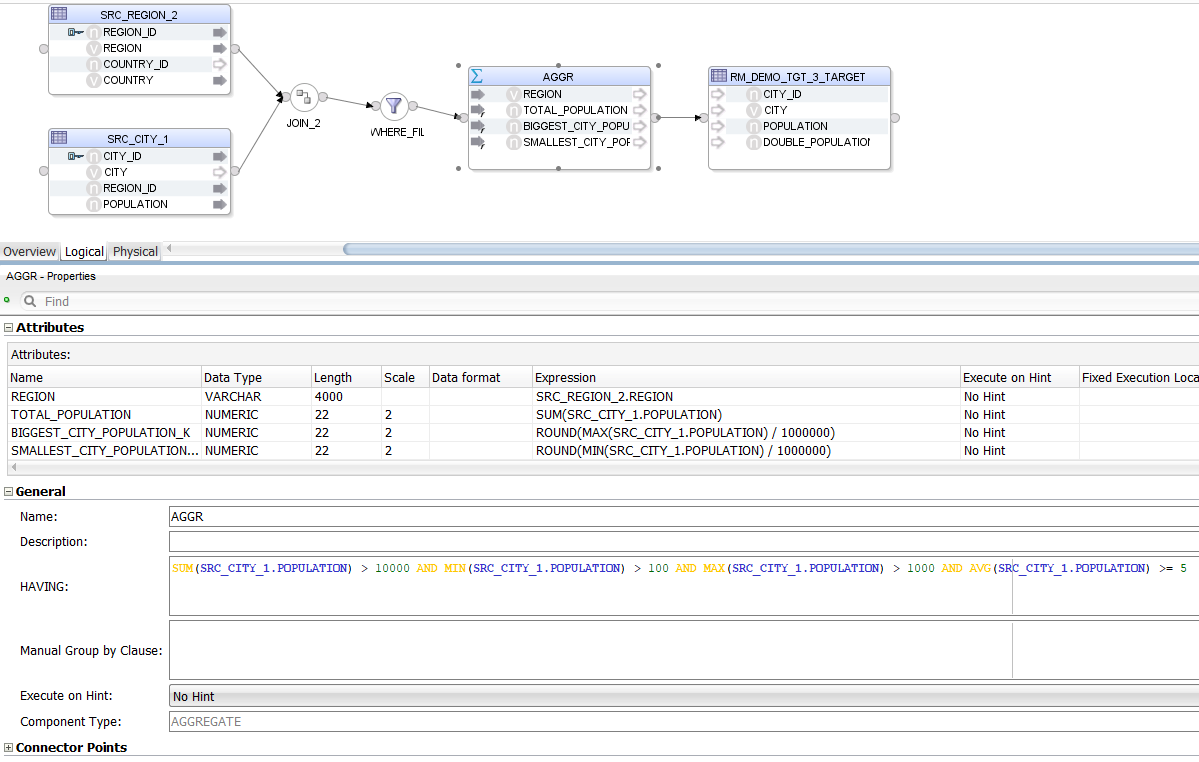
Now let us try Aggregates.
SELECT
REGION,
SUM(POPULATION) TOTAL_POPULATION,
ROUND(MAX(SRC_CITY.POPULATION) / 1000000) BIGGEST_CITY_POPULATION_K,
ROUND(MIN(SRC_CITY.POPULATION) / 1000000) SMALLEST_CITY_POPULATION_K
FROM
ODI_DEMO.SRC_CITY
INNER JOIN ODI_DEMO.SRC_REGION ON SRC_CITY.REGION_ID = SRC_REGION.REGION_ID
WHERE
CITY_ID > 20 AND
"SRC_CITY"."CITY_ID" < 1000 AND
ODI_DEMO.SRC_CITY.CITY_ID != 999 AND
COUNTRY IN ('USA', 'France', 'Germany', 'Great Britain', 'Japan')
GROUP BY
REGION
HAVING
SUM(POPULATION) > 10000 AND
MIN(SRC_CITY.POPULATION) > 100 AND
MAX("POPULATION") > 1000 AND
AVG(ODI_DEMO.SRC_CITY.POPULATION) >= 5
This time, instead of an Expression we have an Aggregate. The parser has no problem handling the many different "styles" of column references provided in the HAVING clause - all of them are rewritten to be understood by ODI.
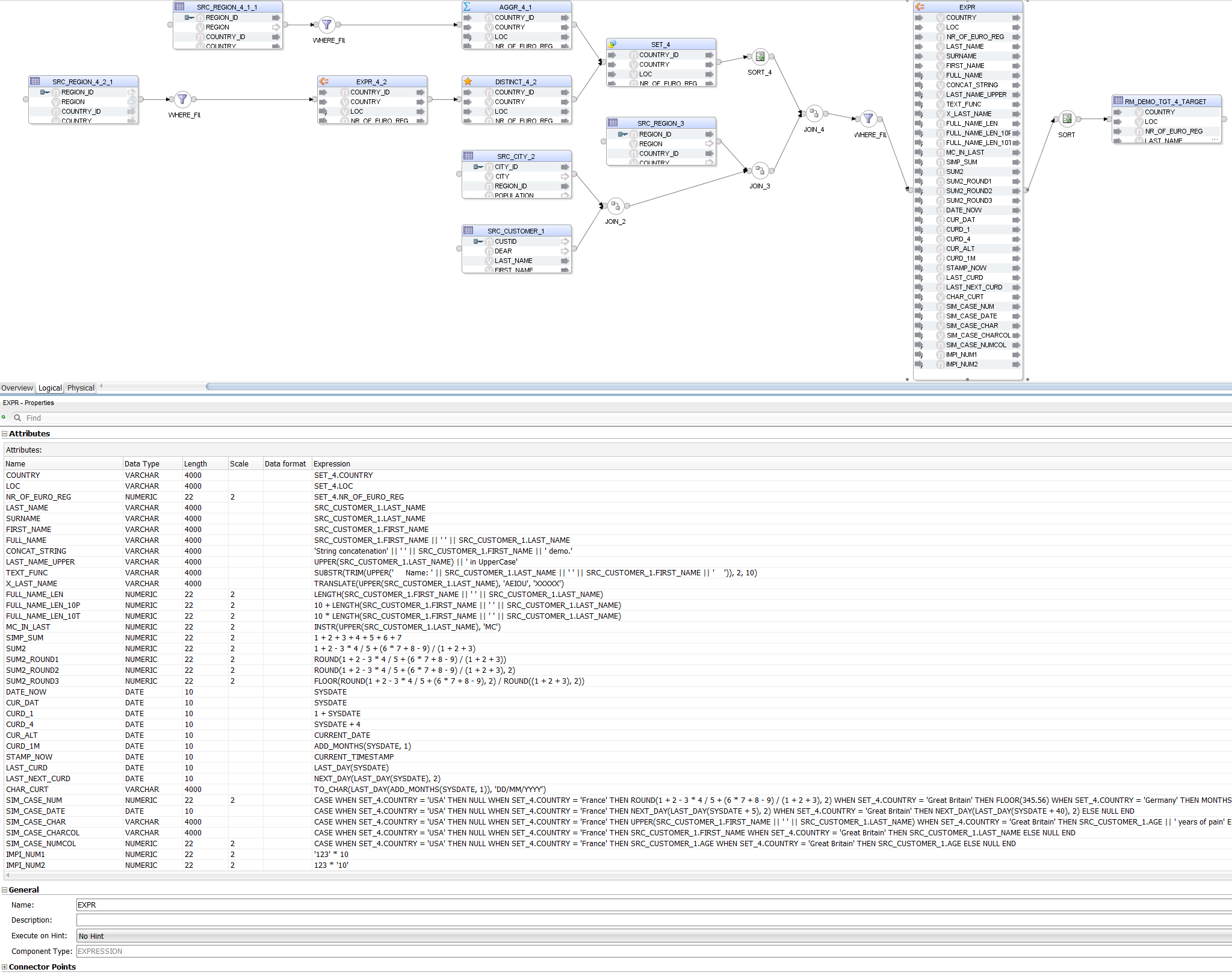
Now let us throw different Expressions at it, to see how well they are handled.
SELECT
REG_COUNTRY.COUNTRY,
REG_COUNTRY.LOC,
REG_COUNTRY.NR_OF_EURO_REG,
LAST_NAME,
LAST_NAME AS SURNAME,
FIRST_NAME,
FIRST_NAME || ' ' || LAST_NAME FULL_NAME,
'String concatenation' || ' ' || FIRST_NAME || ' demo.' CONCAT_STRING,
UPPER(LAST_NAME) || ' in UpperCase' AS LAST_NAME_UPPER,
SUBSTR(TRIM(UPPER(' Name: ' || LAST_NAME || ' ' || FIRST_NAME || ' ')), 2, 10) TEXT_FUNC,
TRANSLATE(UPPER(LAST_NAME), 'AEIOU', 'XXXXX') X_LAST_NAME,
LENGTH(FIRST_NAME || ' ' || LAST_NAME) FULL_NAME_LEN,
10 + LENGTH(FIRST_NAME || ' ' || LAST_NAME) FULL_NAME_LEN_10P,
10 * LENGTH(FIRST_NAME || ' ' || LAST_NAME) FULL_NAME_LEN_10T,
INSTR(UPPER(LAST_NAME), 'MC') MC_IN_LAST,
1 + 2 + 3 + 4 +5+6+7 SIMP_SUM,
1+2-3*4/5+(6*7+8-9)/(1+2+3) SUM2,
ROUND(1+2-3*4/5+(6*7+8-9)/(1+2+3)) SUM2_ROUND1,
ROUND(1+2-3*4/5+(6*7+8-9)/(1+2+3), 2) SUM2_ROUND2,
FLOOR(ROUND(1+2-3*4/5+(6*7+8-9), 2) / ROUND((1+2+3), 2)) SUM2_ROUND3,
SYSDATE DATE_NOW,
SYSDATE AS CUR_DAT,
1 + SYSDATE AS CURD_1,
SYSDATE + 4 AS CURD_4,
CURRENT_DATE AS CUR_ALT,
ADD_MONTHS(SYSDATE, 1) CURD_1M,
CURRENT_TIMESTAMP STAMP_NOW,
LAST_DAY(SYSDATE) LAST_CURD,
NEXT_DAY(LAST_DAY(SYSDATE), 2) LAST_NEXT_CURD,
TO_CHAR(LAST_DAY(ADD_MONTHS(SYSDATE, 1)), 'DD/MM/YYYY') CHAR_CURT,
CASE
WHEN REG_COUNTRY.COUNTRY = 'USA' THEN NULL
WHEN REG_COUNTRY.COUNTRY = 'France' THEN ROUND(1+2-3*4/5+(6*7+8-9)/(1+2+3), 2)
WHEN REG_COUNTRY.COUNTRY = 'Great Britain' THEN FLOOR(345.56)
WHEN REG_COUNTRY.COUNTRY = 'Germany' THEN MONTHS_BETWEEN(SYSDATE, SYSDATE+1000)
ELSE NULL
END SIM_CASE_NUM,
CASE
WHEN REG_COUNTRY.COUNTRY = 'USA' THEN NULL
WHEN REG_COUNTRY.COUNTRY = 'France' THEN NEXT_DAY(LAST_DAY(SYSDATE+5), 2)
WHEN REG_COUNTRY.COUNTRY = 'Great Britain' THEN NEXT_DAY(LAST_DAY(SYSDATE+40), 2)
ELSE NULL
END SIM_CASE_DATE,
CASE
WHEN REG_COUNTRY.COUNTRY = 'USA' THEN NULL
WHEN REG_COUNTRY.COUNTRY = 'France' THEN UPPER(FIRST_NAME || ' ' || LAST_NAME)
WHEN REG_COUNTRY.COUNTRY = 'Great Britain' THEN AGE || ' years of pain'
ELSE NULL
END SIM_CASE_CHAR,
CASE
WHEN REG_COUNTRY.COUNTRY = 'USA' THEN NULL
WHEN REG_COUNTRY.COUNTRY = 'France' THEN FIRST_NAME
WHEN REG_COUNTRY.COUNTRY = 'Great Britain' THEN LAST_NAME
ELSE NULL
END SIM_CASE_CHARCOL,
CASE
WHEN REG_COUNTRY.COUNTRY = 'USA' THEN NULL
WHEN REG_COUNTRY.COUNTRY = 'France' THEN AGE
WHEN REG_COUNTRY.COUNTRY = 'Great Britain' THEN AGE
ELSE NULL
END SIM_CASE_NUMCOL,
'123' * 10 IMPI_NUM1,
123 * '10' IMPI_NUM2
FROM
ODI_DEMO.SRC_CUSTOMER
INNER JOIN ODI_DEMO.SRC_CITY ON SRC_CITY.CITY_ID = SRC_CUSTOMER.CITY_ID
INNER JOIN ODI_DEMO.SRC_REGION ON SRC_CITY.REGION_ID = SRC_REGION.REGION_ID
INNER JOIN (
SELECT COUNTRY_ID, COUNTRY, 'Europe' LOC, COUNT(DISTINCT REGION_ID) NR_OF_EURO_REG FROM ODI_DEMO.SRC_REGION WHERE COUNTRY IN ('France','Great Britain','Germany') GROUP BY COUNTRY_ID, COUNTRY
UNION
SELECT DISTINCT COUNTRY_ID, COUNTRY, 'Non-Europe' LOC, 0 NR_OF_EURO_REG FROM ODI_DEMO.SRC_REGION WHERE COUNTRY IN ('USA','Australia','Japan')
ORDER BY NR_OF_EURO_REG
) REG_COUNTRY ON SRC_REGION.COUNTRY_ID = REG_COUNTRY.COUNTRY_ID
WHERE
REG_COUNTRY.COUNTRY IN ('USA', 'France', 'Great Britain', 'Germany', 'Australia')
ORDER BY
LOC, COUNTRY
Notice that, apart from parsing the different Expressions, Sql2Odi also resolves data types:
1 + SYSDATE is correctly resolved as a DATE value whereas TO_CHAR(LAST_DAY(ADD_MONTHS(SYSDATE, 1)), 'DD/MM/YYYY') CHAR_CURT is recognised as a VARCHAR value - because of the TO_CHAR function;
LAST_NAME and FIRST_NAME are resolved as VARCHAR values because that is their type in the source table;
AGE || ' years of pain' is resolved as a VARCHAR despite AGE being a numeric value - because of the concatenation operator;
More challenging is data type resolution for CASE statements, but those are handled based on the datatypes we encounter in the THEN and ELSE parts of the statement.
Also notice that we have a UNION joiner for the two subqueries - that is translated into an ODI Set Component.
As we can see, Sql2Odi is capable of handling quite complex SELECT statements. Alas, that does not mean it can handle 100% of them - Oracle hierarchical queries, anything involving PIVOTs, the old Oracle (+) notation, the WITH statement - those are a few examples of constructs Sql2Odi, as of this writing, cannot yet handle.
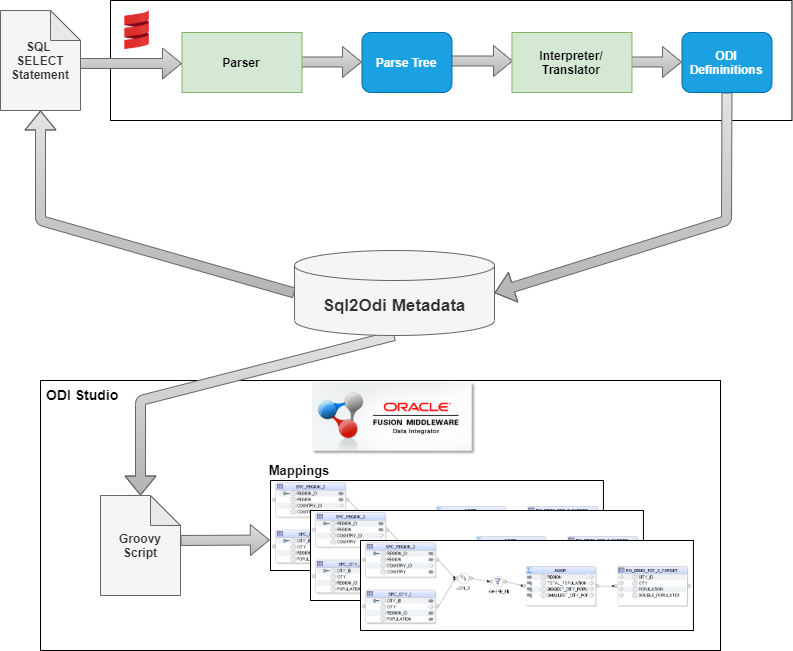
Sql2Odi - what is under the hood?
Scala's Combinator Parsing library was used for lexical and syntactic analysis. We went with a context-free grammar definition for the SELECT statement, because our goal was never to establish if a SELECT statement is 100% valid - only the RDBMS server can do that. Hence we start with the assumption that the SELECT statement is valid. An invalid SELECT statement, depending on the nature of the error, may or may not result in a parsing error.
For example, the Expression ADD_MONTHS(CUSTOMER.FIRST_NAME, 3) is obviously wrong but our parser assumes that the FIRST_NAME column is a DATE value.
Part of the parsing-translation process was also data type recognition. In the example above, the parser recognises that the function being used returns a datetime value. Therefore it concludes that the whole expression, regardless of what the input to that function is - a column, a constant or another complex Expression - will always be a DATE value.
The output of the Translator is a structured data value containing definitions for ODI Mapping Components and their joins. I chose JSON format but XML would have done the trick as well.
The ODI Mapping definitions are then read by a Groovy script from within ODI Studio and Mappings are generated one by one.
Mapping generation takes much longer than parsing. Parsing for a mapping is done in a split second whereas generating an ODI Mapping, depending on its size, can take a couple of seconds.
Conclusion
It is possible to convert SQL SELECT statements to ODI Mappings, even quite complex ones. This can make migrations from SQL-based legacy ETL tools to ODI much quicker, allows to refactor an SQL-based ETL prototype to ODI without having to implement the same data extraction and transformation logic twice.
Cloud computing has gone from being a cutting-edge technology to a well-established best practice for businesses of all sizes and industries. According to Flexera’s 2020 State of the Cloud Report, 98 percent of organizations are now using at least one public or private cloud.
Beneath the umbrella of “the cloud,” however, there are several cloud services. The term XaaS (“anything as a service”) is shorthand for the proliferation of cloud services in recent years—everything from databases and artificial intelligence to unified communications and disaster recovery is now available from your choice of cloud provider.
In this article, we’ll discuss the three “pillars” of cloud computing—SaaS, IaaS, and PaaS—and discuss how you might use any or all of them when migrating to the Oracle cloud.
Oracle SaaS (Software as a Service)
SaaS (“software as a service”) refers to software applications that are hosted on a remote server and provisioned to customers over the Internet. Oracle’s SaaS cloud offerings include:
Oracle EPM Cloud
Oracle ERP—Financials Cloud
Oracle HCM Cloud
Oracle Analytics Cloud
Oracle SCM and Manufacturing Cloud
Oracle Data Cloud
Using SaaS is best in the following situations:
Your software needs to prioritize scalability and accessibility from anywhere at any time.
Your processes are standardized across the enterprise or can be changed to fit the application.
An off-the-shelf product straight from the vendor can fit your business requirements.
You prefer a monthly or an annual payment scheme to large one-time capital expenses.
Oracle IaaS (Infrastructure as a Service)
IaaS (“infrastructure as a service”) refers to physical IT infrastructure (i.e. compute, network, storage, etc.) that is remotely provisioned and managed over the Internet. Oracle’s IaaS offering is Oracle Cloud Infrastructure (OCI), which includes everything from bare-metal servers and virtual machines (VMs) to more advanced offerings like GPUs (graphics processing units) and high-performance computing.
Using IaaS is best in the following situations:
You have the necessary expertise in-house to remotely manage your IT infrastructure.
You want to save money by only paying for the computing resources you actually use.
Your IT environment is flexible and workloads are variable.
You need to be able to quickly provision IT resources while shutting down excess capacity when demand is low.
Oracle PaaS (Platform as a Service)
Last but not least, PaaS (“platform as a service”) refers to a complete cloud platform for software development and deployment. PaaS includes the essential infrastructure and middleware as well as technologies such as artificial intelligence, the Internet of Things (IoT), containerization, and big data analytics.
Oracle’s PaaS offering is also incorporated within OCI and makes use of both Oracle and open-source technologies. Oracle PaaS includes functionality for application development, content management, and business analytics, among others.
Unlike SaaS and IaaS, using PaaS isn’t a choice that you can make in isolation. Each SaaS or IaaS platform usually works best with one or two PaaS options, which considerably narrows your choices.
Conclusion
SaaS, IaaS, and PaaS: although each one falls under the umbrella of “cloud computing,” each one has a very different role to play for your organization’s IT environment. If you need more advice on which one is right for you, reach out to a knowledgeable, qualified Oracle cloud partner like Datavail.
Discussing the various Oracle cloud options is especially timely right now—the end of support (EOS) date for Oracle Hyperion EPM 11.1.2.4 on-premises is arriving in December 2021. EPM 11.1 users who don’t upgrade will fall out of compliance, exposing themselves to security vulnerabilities and missing out on new features and functionality.
Considering an Oracle EPM cloud migration? As an Oracle Platinum Partner with 17 different specializations, Datavail can assist with every stage of the process, from roadmaps and strategic planning to post-launch support and maintenance. Read our white paper to learn more about the upcoming Hyperion deadline and how Datavail can help.
Welcome to the Monthly Index for March 2021
This blog provides quick links to recent Proactive Support Blog postings for Oracle Business Intelligence and Hyperion EPM from the past month.
Oracle Enterprise Business Suite (EBS) is used by thousands of enterprise customers around the world, with applications ranging from enterprise resource planning (ERP) to customer relationship management (CRM). While this rich array of software is tremendously useful, the complexity of your Oracle EBS environment can quickly become overwhelming if you don’t actively work to manage it.
Below, we’ll discuss one of the most pressing concerns for Oracle EBS: data lifecycle management (DLM). If you’re not careful, the size of your Oracle EBS environment can quickly swell, increasing your IT expenses and slowing down the system’s performance. Data lifecycle management for Oracle EBS is an essential practice that can slim down the size of your EBS footprint while preserving access to data for the users who need it.
The 4 Stages of Data Lifecycle Management
Every piece of data that your organization handles is located at a particular stage in the enterprise data lifecycle. The 4 basic stages of data lifecycle management are:
Creation: First, data is created and/or collected. For example, you might acquire data from a third party, manually create it with data entry, or observe it with a given tool, process, or sensor.
Storage: Data that is useful long-term needs to be securely stored and backed up on a regular basis. However, this need for secure storage also must be balanced with the ability to easily view, modify, and analyze the data.
Archival: Information that is no longer used, or used only infrequently, should be archived in a separate location. Archiving files helps limit the data bloat of your Oracle EBS footprint, while also ensuring compliance with the necessary standards and regulations, such as GDPR and CCPA.
Deletion: Once data is no longer useful, and no longer subject to regulatory compliance, it can be safely deleted. In particular, sensitive and confidential information must be handled with care and properly wiped so that it’s not exposed to a third party.
How to Practice Data Lifecycle Management for Oracle EBS
The data lifecycle management stages listed above are ideal for any organization that relies heavily on its enterprise data (and these days, that’s pretty much all of them). Unfortunately, far too many businesses aren’t able to achieve a fluid, efficient DLM process for their enterprise data—whether that’s due to organizational inertia or lack of in-house technical expertise.
However, practicing good data lifecycle management for Oracle EBS is a must. By archiving and deleting the data you use infrequently or not at all, you’ll have less information in your EBS deployment to manage. This has several advantages: you’ll no longer be replicating unused data when cloning a new EBS environment, and your reports and analyses will speed up significantly.
A few data lifecycle management best practices for Oracle EBS include:
Understand the data you collect: Oracle EBS databases are capable of storing a wide variety of information, from customer records to accounting spreadsheets. Each type of data, and the database in which it’s stored, may also have separate concerns regarding regulatory compliance and data privacy. The first step in data lifecycle management for Oracle EBS is understanding exactly what type of information you have on hand and how it needs to be managed.
Have a backup and business continuity plan: While archiving data is a best practice for the information you rarely use anymore, the data you use on a daily basis should be backed up on a regular basis to help preserve business continuity. On-premises backups are perhaps easiest, but they’re also at risk in the event of an on-site natural disaster. Cloud backups securely replicate your files on multiple servers and can easily scale up as the amount of your enterprise data increases.
Working with a third-party managed services provider can help with DLM—but you’ll need to choose the right one. Your choice of Oracle EBS MSP should be familiar with your business goals and requirements so that they can help advise you about which data to preserve and how to preserve it.
Conclusion
By applying data lifecycle management best practices for Oracle EBS, you can make your enterprise IT significantly less complicated, while also improving performance and slashing costs. However, DLM is just one of the many IT challenges that Oracle EBS users need to address.
As an Oracle Platinum Partner, Datavail has many years of experience helping our clients manage and maintain their Oracle EBS deployments. To learn more about the complexities of using Oracle EBS, and how you can take steps to resolve them, check out our white paper The Top 6 Challenges of Managing Oracle EBS Environments.