Last week, I spent a couple of days with Oracle at Thames Valley Park and this presented me with a perfect opportunity to sit down and get to grips with the full extent of the Oracle Analytics Cloud (OAC) suite...without having to worry about client requirements or project deadlines!
As a company, Rittman Mead already has solid experience of OAC, but my personal exposure has been limited to presentations, product demonstrations, reading the various postings in the blog community and my existing experiences of Data Visualisation and BI cloud services (DVCS and BICS respectively). You’ll find Francesco’s post a good starting place if you need an overview of OAC and how it differs (or aligns) to Data Visualisation and BI Cloud Services.
So, having spent some time looking at the overall suite and, more importantly, trying to interpret what it could mean for organisations thinking about making a move to the cloud, here are my top three takeaways:
Clouds Come In Different Shapes and Flavours
Two of the main benefits that a move to the cloud offers are simplification in platform provisioning and an increase in flexibility, being able to ramp up or scale down resources at will. These both comes with a potential cost benefit, depending on your given scenario and requirement. The first step is understanding the different options in the OAC licensing and feature matrix.
First, we need to draw a distinction between Analytics Cloud and the Autonomous Analytics Cloud (interestingly, both options point to the same page on cloud.oracle.com, which makes things immediately confusing!). In a nutshell though, the distinction comes down to who takes responsibility for the service management: Autonomous Analytics Cloud is managed by Oracle, whilst Analytics Cloud is managed by yourself. It’s interesting to note that the Autonomous offering is marginally cheaper.
Next, Oracle have chosen to extend their BYOL (Bring Your Own License) option from their IaaS services to now incorporate PaaS services. This means that if you have existing licenses for the on-premise software, then you are able to take advantage of what appears to be a significantly discounted cost. Clearly, this is targeted to incentivise existing Oracle customers to make the leap into the Cloud, and should be considered against your ongoing annual support fees.
Since the start of the year, Analytics Cloud now comes in three different versions, with the Standard and Enterprise editions now being separated by the new Data Lake edition. The important things to note are that (possibly confusingly) Essbase is now incorporated into the Data Lake edition of the Autonomous Analytics Cloud and that for the full enterprise capability you have with OBIEE, you will need the Enterprise edition. Each version inherits the functionality of its preceding version: Enterprise edition gives you everything in the Data Lake edition; Data Lake edition incorporates everything in the Standard edition.

Finally, it’s worth noting that OAC aligns to the Universal Credit consumption model, whereby the cost is determined based on the size and shape of the cloud that you need. Services can be purchased as Pay as You Go or Monthly Flex options (with differential costing to match). The PAYG model is based on hourly consumption and is paid for in arrears, making it the obvious choice for short term prototyping or POC activities. Conversely, the Monthly Flex model is paid in advance and requires a minimum 12 month investment and therefore makes sense for full scale implementations. Then, the final piece of the jigsaw comes with the shape of the service you consume. This is measured in OCPU’s (Oracle Compute Units) and the larger your memory requirements, the more OCPU’s you consume.
Where You Put Your Data Will Always Matter
Moving your analytics platform into the cloud may make a lot of sense and could therefore be a relatively simple decision to make. However, the question of where your data resides is a more challenging subject, given the sensitivities and increasing legislative constraints that exist around where your data can or should be stored. The answer to that question will influence the performance and data latency you can expect from your analytics platform.
OAC is architected to be flexible when it comes to its data sources and consequently the options available for data access are pretty broad. At a high level, your choices are similar to those you would have when implementing on-premise, namely:
- perform ELT processing to transform and move the data (into the cloud);
- replicate data from source to target (in the cloud) or;
- query data sources via direct access.
These are supplemented by a fourth option to use the inbuilt Data Connectors available in OAC to connect to cloud or on-premise databases, other proprietary platforms or any other source accessible via JDBC. This is probably a decent path for exploratory data usage within DV, but I’m not sure it would always make the best long term option.
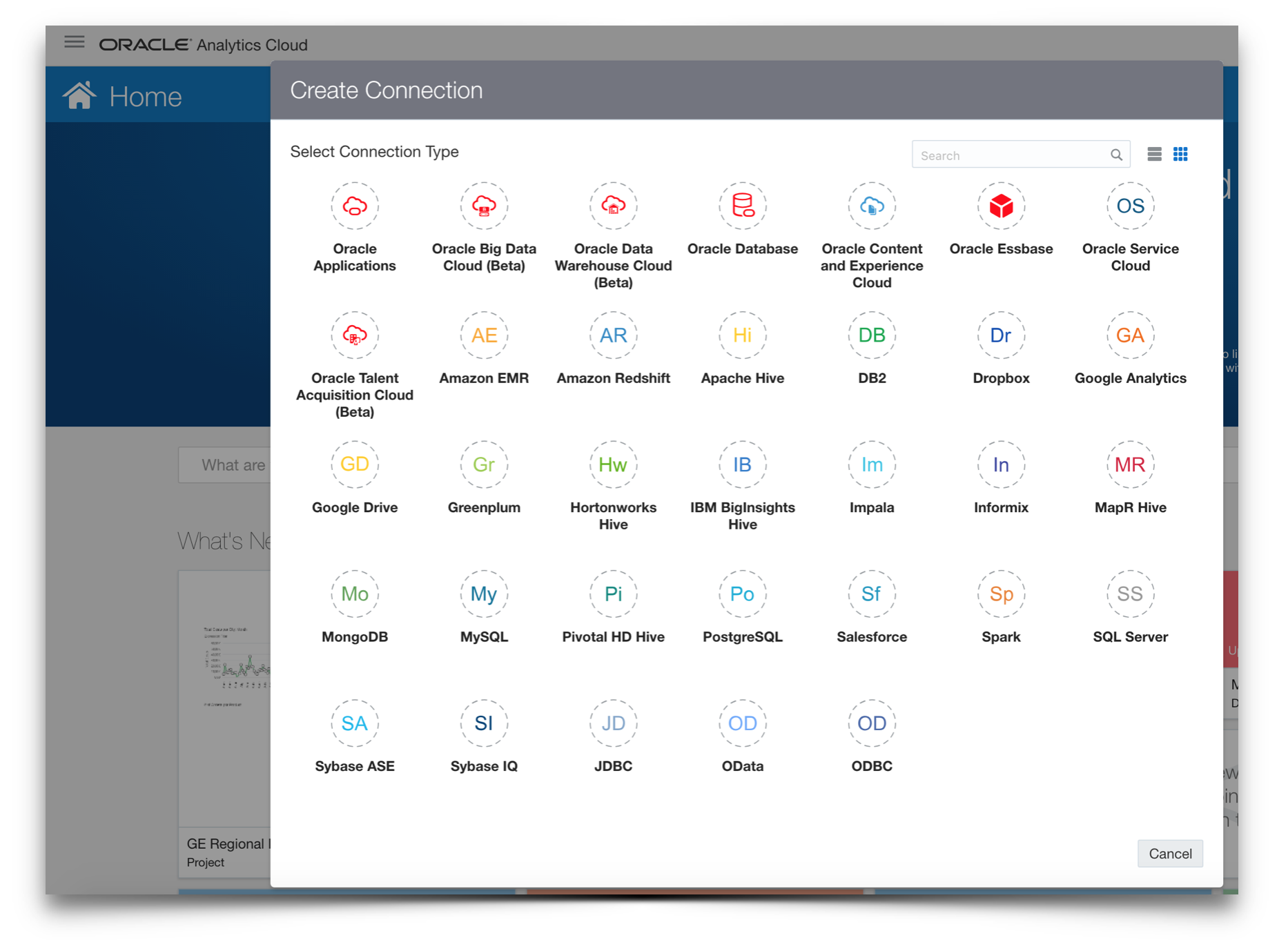
Unsurprisingly, with the breadth of options comes a spectrum of tooling that can be used for shifting your data around and it is important to note that depending on your approach, additional cloud services may or may not be required.
For accessing data directly at its source, the preferred route seems to be to use RDC (Remote Data Connector), although it is worth noting that support is limited to Oracle (including OLAP), SQL Server, Teredata or DB2 databases. Also, be aware that RDC operates within WebLogic Server and so this will be needed within the on-premise network.
Data replication is typically achieved using Data Sync (the reincarnation of the DAC, which OBIA implementers will already be familiar with), although it is worth mentioning that there are other routes that could be taken, such as APEX or SQL Developer, depending on the data volumes and latency you have to play with.
Classic ELT processing can be achieved via Oracle Data Integrator (either the Cloud Service, a traditional on-premise implementation or a hybrid-model).
Ultimately, due care and attention needs to be taken when deciding on your data architecture as this will have a fundamental effect on the simplicity with which data can be accessed and interpreted, the query performance achieved and the data latency built into your analytics.
A while back, I wrote a post titled Enabling a Modern Analytics Platform in which I attempted to describe ways that Mode 1 (departmental) and Mode 2 (enterprise) analytics could be built out to support each other, as opposed to undermining one another. One of the key messages I made was the importance of having an effective mechanism for transitioning your Mode 1 outputs back into Mode 2 as seamlessly as possible. (The same is true in reverse for making enterprise data available as an Mode 1 input.)
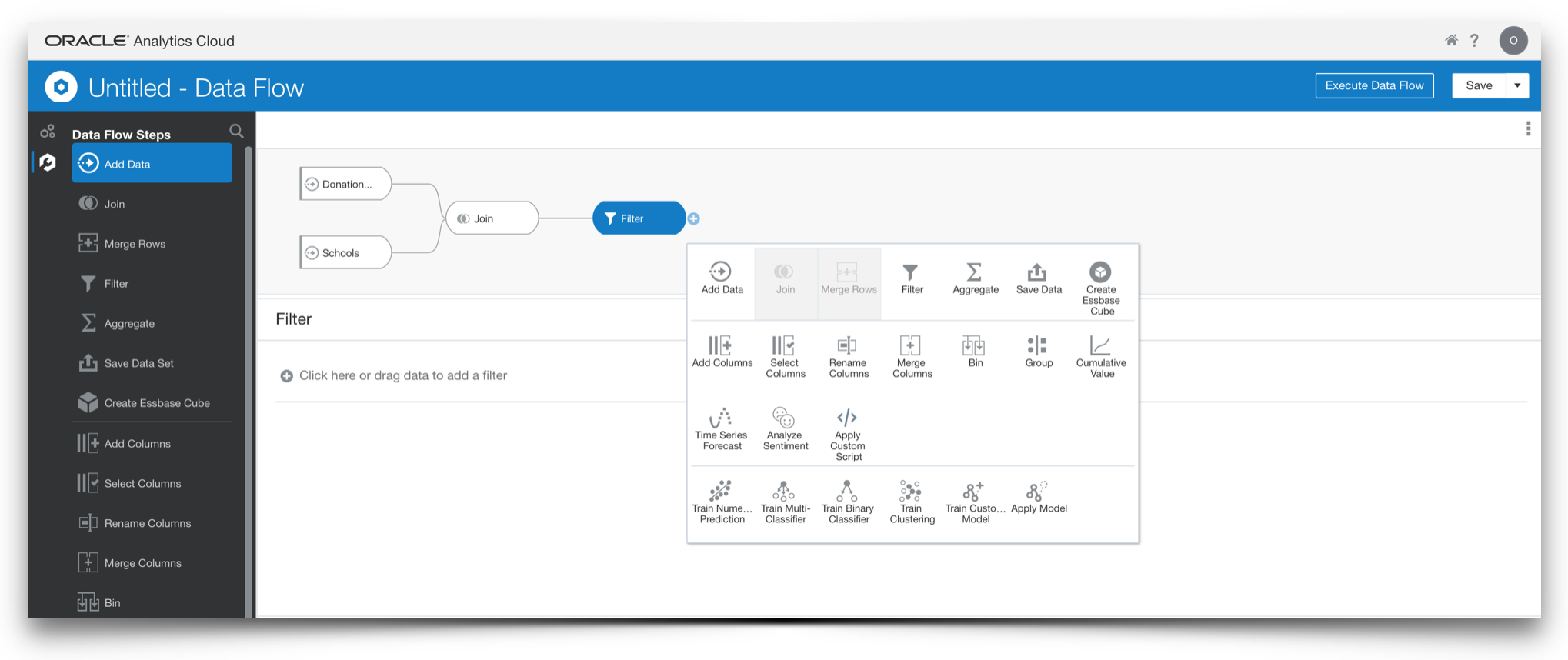
One of the great things about OAC is how it serves to simplify this transition. Users are able to create analytic content based on data sourced from a broad range of locations: at the simplest level, Data Sets can be built from flat files or via one of the available Data Connectors to relational, NoSQL, proprietary database or Essbase sources. Moreover, enterprise curated metadata (via RPD lift-and-shift from an on-premise implementation) or analyst developed Subject Areas can be exposed. These sources can be ‘mashed’ together directly in a DV project or, for more complex or repeatable actions, Data Flows can be created to build Data Sets. Data Flows are pretty powerful, not only allowing users to join disparate data but also perform some useful data preparation activities, ranging from basic filtering, aggregation and data manipulation actions to more complex sentiment analysis, forecasting and even some machine learning modelling features. Importantly, Data Flows can be set to output their results to disk, either written to a Data Set or even to a database table and they can be scheduled for repetitive refresh.
For me, one of the most important things about the Data Flows feature is that it provides a clear and understandable interface which shows the sequencing of each of the data preparation stages, providing valuable information for any subsequent reverse engineering of the processing back into the enterprise data architecture.
In summary, there are plenty of exciting and innovative things happening with Oracle Analytics in the cloud and as time marches on, the case for moving to the cloud in one shape or form will probably get more and more compelling. However, beyond a strategic decision to ‘Go Cloud’, there are many options and complexities that need to be addressed in order to make a successful start to your journey - some technical, some procedural and some organisational. Whilst a level of planning and research will undoubtedly smooth the path, the great thing about the cloud services is that they are comparatively cheap and easy to initiate, so getting on and building a prototype is always going to be a good, exploratory starting point.




