Category Archives: Rittman Mead
Using SQL to Query JSON Files with Apache Drill
I wrote recently about what Apache Drill is, and how to use it with OBIEE. In this post I wanted to demonstrate its great power in action for a requirement that came up recently. We wanted to analyse our blog traffic, broken down by blog author. Whilst we have Google Analytics to provide the traffic, it doesn't include the blog author. This is held within the blog platform, which is Ghost. The common field between the two datasets is the post "slug". From Ghost we could get a dump of the data in JSON format. We needed to find a quick way to analyse and extract from this JSON a list of post slugs and associated author.
One option would be to load the JSON into a RDBMS and process it from within there, running SQL queries to extract the data required. For a long-term large-scale solution, maybe this would be appropriate. But all we wanted to do here was query a single file, initially just as a one-off. Enter Apache Drill. Drill can run on a single laptop (or massively clustered, if you need it). It provides a SQL engine on top of various data sources, including text data on local or distributed file systems (such as HDFS).
You can use Drill to dive straight into the json:
0: jdbc:drill:zk=local> use dfs;
+-------+----------------------------------+
| ok | summary |
+-------+----------------------------------+
| true | Default schema changed to [dfs] |
+-------+----------------------------------+
1 row selected (0.076 seconds)
0: jdbc:drill:zk=local> select * from `/Users/rmoff/Downloads/rittman-mead.ghost.2016-11-01.json` limit 1;
+----+
| db |
+----+
| [{"meta":{"exported_on":1478002781679,"version":"009"},"data":{"permissions":[{"id":1,"uuid":"3b24011e-4ad5-42ed-8087-28688af7d362","name":"Export database","object_type":"db","action_type":"exportContent","created_at":"2016-05-23T11:24:47.000Z","created_by":1,"updated_at":"2016-05-23T11:24:47.000Z","updated_by":1},{"id":2,"uuid":"55b92b4a-9db5-4c7f-8fba-8065c1b4b7d8","name":"Import database","object_type":"db","action_type":"importContent","created_at":"2016-05-23T11:24:47.000Z","created_by":1,"updated_at":"2016-05-23T11:24:47.000Z","updated_by":1},{"id":3,"uuid":"df98f338-5d8c-4683-8ac7-fa94dd43d2f1","name":"Delete all content","object_type":"db","action_type":"deleteAllContent","created_at":"2016-05-23T11:24:47.000Z","created_by":1,"updated_at":"2016-05-23T11:24:47.000Z","updated_by":1},{"id":4,"uuid":"a3b8c5c7-7d78-442f-860b-1cea139e1dfc","name":"Send mail","object_type":"mail","action_
But from this we can see the JSON object is a single column db of array type. Let's take a brief detour into one of my favourite commandline tools - jq. This let's you format, filter, and extract values from JSON. Here we can use it to get an idea of how the data's structured. We can do this in Drill, but jq gives us a headstart:

We can see that under the db array are two elements; meta and data. Let's take meta as a simple example to expose through Drill, and then build from there into the user data that we're actually after.
Since the root data element (db) is an array, we need to FLATTEN it:
0: jdbc:drill:zk=local> select flatten(db) from `/Users/rmoff/Downloads/rittman-mead.ghost.2016-11-01.json` limit 1;
+--------+
| EXPR$0 |
+--------+
| {"meta":{"exported_on":1478002781679,"version":"009"},"data":{"permissions":[{"id":1,"uuid":"3b24011e-4ad5-42ed-8087-28688af7d362","name":"Export database","object_type":"db","action_type":"exportContent","created_at":"2016-05-23T11:24:47.000Z","created_by":1,"updated_at":"2016-05-23T11:24:47.000Z","updated_by":1},{"id":2,"uuid":"55b92b4a-9db5-4c7f-8fba-8065c1b4b7d8","name":"Import database","object_type":"db","action_type":"importContent","created_at":"2016-05-23T11:24:47.000Z","created_by":1,"updated_at":"2016-05-23T11:24:47.000Z","u
Now let's query the meta element itself:
0: jdbc:drill:zk=local> with db as (select flatten(db) from `/Users/rmoff/Downloads/rittman-mead.ghost.2016-11-01.json`) select db.meta from db limit 1;
Nov 01, 2016 2:18:31 PM org.apache.calcite.sql.validate.SqlValidatorException <init>
SEVERE: org.apache.calcite.sql.validate.SqlValidatorException: Column 'meta' not found in table 'db'
Nov 01, 2016 2:18:31 PM org.apache.calcite.runtime.CalciteException <init>
SEVERE: org.apache.calcite.runtime.CalciteContextException: From line 1, column 108 to line 1, column 111: Column 'meta' not found in table 'db'
Error: VALIDATION ERROR: From line 1, column 108 to line 1, column 111: Column 'meta' not found in table 'db'
SQL Query null
[Error Id: 9cb4aa98-d522-42bb-bd69-43bc3101b40e on 192.168.10.72:31010] (state=,code=0)
This didn't work, because if you look closely at the above FLATTEN, the resulting column is called EXPR$0, so we need to alias it in order to be able to reference it:
0: jdbc:drill:zk=local> select flatten(db) as db from `/Users/rmoff/Downloads/rittman-mead.ghost.2016-11-01.json`;
+----+
| db |
+----+
| {"meta":{"exported_on":1478002781679,"version":"009"},"data":{"permissions":[{"id":1,"uuid":"3b24011e-4ad5-42ed-8087-28688af7d362","name":"Export database","object_type":"db","action_type":"exportConten
Having done this, I'll put the FLATTEN query as a subquery using the WITH syntax, and from that SELECT just the meta elements:
0: jdbc:drill:zk=local> with ghost as (select flatten(db) as db from `/Users/rmoff/Downloads/rittman-mead.ghost.2016-11-01.json`) select ghost.db.meta from ghost limit 1;
+------------------------------------------------+
| EXPR$0 |
+------------------------------------------------+
| {"exported_on":1478002781679,"version":"009"} |
+------------------------------------------------+
1 row selected (0.317 seconds)
Note that the column is EXPR$0 because we've not defined a name for it. Let's fix that:
0: jdbc:drill:zk=local> with ghost as (select flatten(db) as db from `/Users/rmoff/Downloads/rittman-mead.ghost.2016-11-01.json`) select ghost.db.meta as meta from ghost limit 1;
+------------------------------------------------+
| meta |
+------------------------------------------------+
| {"exported_on":1478002781679,"version":"009"} |
+------------------------------------------------+
1 row selected (0.323 seconds)
0: jdbc:drill:zk=local>
Why's that matter? Because it means that we can continue to select elements from within it.
We could continue to nest the queries, but it gets messy to read, and complex to debug any issues. Let's take this meta element as a base one from which we want to query, and define it as a VIEW:
0: jdbc:drill:zk=local> create or replace view dfs.tmp.ghost_meta as with ghost as (select flatten(db) as db from `/Users/rmoff/Downloads/rittman-mead.ghost.2016-11-01.json`) select ghost.db.meta as meta from ghost;
+-------+-------------------------------------------------------------+
| ok | summary |
+-------+-------------------------------------------------------------+
| true | View 'ghost_meta' created successfully in 'dfs.tmp' schema |
+-------+-------------------------------------------------------------+
1 row selected (0.123 seconds)
Now we can select from the view:
0: jdbc:drill:zk=local> select m.meta.exported_on as exported_on, m.meta.version as version from dfs.tmp.ghost_meta m;
+----------------+----------+
| exported_on | version |
+----------------+----------+
| 1478002781679 | 009 |
+----------------+----------+
1 row selected (0.337 seconds)
Remember that when you're selected nested elements you must alias the object that you're selecting from. If you don't, then Drill assumes that the first element in the column name (for example, meta.exported_on) is the table name (meta), and you'll get an error:
Error: VALIDATION ERROR: From line 1, column 8 to line 1, column 11: Table 'meta' not found
So having understood how to isolate and query the meta element in the JSON, let's progress onto what we're actually after - the name of the author of each post, and associated 'slug'.
Using jq again we can see the structure of the JSON file, with the code taken from here:
> jq 'path(..)|[.[]|tostring]|join("/")' rittman-mead.ghost.2016-11-01.json |grep --color=never post|more
"db/0/data/posts"
"db/0/data/posts/0"
"db/0/data/posts/0/id"
"db/0/data/posts/0/uuid"
"db/0/data/posts/0/title"
[...]
So Posts data is under the data.posts element, and from manually poking around we can see that user data is under data.users element.
Back to Drill, we'll create views based on the same pattern as we used for meta above; flattening the array and naming the column:
use dfs.tmp;
create or replace view ghost_posts as select flatten(ghost.db.data.posts) post from ghost;
create or replace view ghost_users as select flatten(ghost.db.data.users) `user` from ghost;
The ghost view is the one created above, in the dfs.tmp schema. With these two views created, we can select values from each:
0: jdbc:drill:zk=local> select u.`user`.id,u.`user`.name from ghost_users u where u.`user`.name = 'Robin Moffatt';
+---------+----------------+
| EXPR$0 | EXPR$1 |
+---------+----------------+
| 15 | Robin Moffatt |
+---------+----------------+
1 row selected (0.37 seconds)
0: jdbc:drill:zk=local> select p.post.title,p.post.slug,p.post.author_id from ghost_posts p where p.post.title like '%Drill';
+----------------------------------+----------------------------------+---------+
| EXPR$0 | EXPR$1 | EXPR$2 |
+----------------------------------+----------------------------------+---------+
| An Introduction to Apache Drill | an-introduction-to-apache-drill | 15 |
+----------------------------------+----------------------------------+---------+
1 row selected (0.385 seconds)
and join them:
0: jdbc:drill:zk=local> select p.post.slug as post_slug,u.`user`.name as author from ghost_posts p inner join ghost_users u on p.post.author_id = u.`user`.id where u.`user`.name like 'Robin%' and p.post.status='published' order by p.post.created_at desc limit 5;
+------------------------------------------------------------------------------------+----------------+
| post_slug | author |
+------------------------------------------------------------------------------------+----------------+
| connecting-oracle-data-visualization-desktop-to-google-analytics-and-google-drive | Robin Moffatt |
| obiee-and-odi-security-updates-october-2016 | Robin Moffatt |
| otn-appreciation-day-obiees-bi-server | Robin Moffatt |
| poug | Robin Moffatt |
| all-you-ever-wanted-to-know-about-obiee-performance-but-were-too-afraid-to-ask | Robin Moffatt |
+------------------------------------------------------------------------------------+----------------+
5 rows selected (1.06 seconds)
This is pretty cool. From a 32MB single-row JSON file:

to being able to query it with standard SQL like this:

all with a single tool that can run on a laptop or desktop, and supports ODBC and JDBC for use with your favourite BI tools. For data exploration and understanding new datasets, Apache Drill really does rock!
Connecting Oracle Data Visualization Desktop to Google Analytics and Google Drive
To use Data Visualisation Desktop (DVD) with data from Google Analytics or Google Drive, you need to set up the necessary credentials on Google so that DVD can connect to it. You can see a YouTube of this process on this blog here.
Before starting, you need a piece of information from Oracle DVD that will be provided to Google during the setup. From DVD, create a new connection of type Google Analytics, and make a note of the the provided redirect URL:

Once you have this URL, you can go and set up the necessary configuration in Google. To do this, go to https://console.developers.google.com/ and sign in with the same Google credentials as have acces to Google Analytics.
Then go to https://console.developers.google.com/iam-admin/projects and click on Create Project

Having created the project, we now need to make available the necessary APIs to it, after which we will create the credentials. Go to https://console.developers.google.com/apis/ and click on Analytics API

On the next screen, click Enable, which adds this API to the project.

If you want, at this point you can return to the API list and also add the Google Drive API by selecting and then Enabling it.
Now we will create the credentials required. Click on Credentials, and then on OAuth consent screen. Fill out the Product name field.

Click on Save, and then on the next page click on Create credentials and from the dropdown list OAuth client ID

Set the Application type to Web Application, give it a name, and then copy the URL given in the DVD New Connection window into the Authorised redirect URIs field.

Click Create, and then make a note of the provided client ID and client secret. Watch out for any spaces before or after the values (h/t @Nephentur). Keep these credentials safe as you would any password.

Go back to DVD and paste these credentials into the Create Connection screen, and click Authorise. When prompted, sign in to your Google Account.
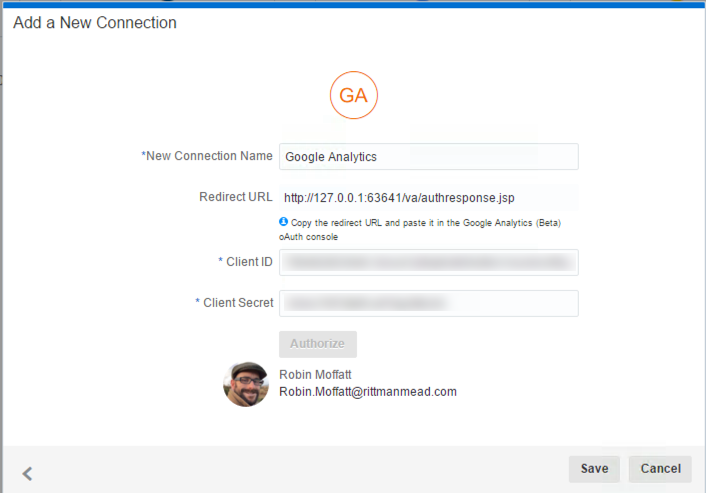
Click on Save, and your connection is now created successfully!
With a connection to Google Analytics created, you can now analyse the data available from within it. You'll need to set the measure columns appropriately, as by default they're all taken by DVD to be dimensions.

Whatever next? The battle to keep up with changes in technology
I’ve been managing Rittman Mead’s Training services in the UK & Europe for over a year now, working closely with my colleagues in the US to ensure we continue to coherently deliver expert instructor led educational courses to the very highest standards.
One thing I’ve noticed is that while a great deal of value is gained by attending instructor led training, particularly if you’re upgrading or installing a new product to your data platform, you can find that two or three months down the line a new version is released which comes with new features and functions that weren’t previously taught.
Take OBIEE 12c for example, it first hit the shelves back in October 2015 and we are now on the 3rd release. In the last year, we’ve seen additions such as Data Visualization Desktop (see my friend Francesco’s recent blog post) and the ability to incorporate even more data sources to your OBIEE system (see my friend Matt’s new features guide!)
At Rittman Mead, we’ve been working on a service which we believe will complement our customer’s initial investment in instructor led training sessions. While we always wish to retain an open line of communication with everyone we have trained in the past, we realise that offering contemporary content that’s more attuned to end-users everyday roles is beneficial and necessary.
Our on-demand training service will offer top-up courses as well as our current catalog of training. It's designed to fit around users’ busy schedules with self paced learning to help people get the best out of their investment in new technology.
For more information including sneak peeks & early bird offers for our on-demand training services, please register your details here.
Performing a 12c Upgrade with a New Install
Software updates often include new features, and while useful, these new features are often the only driving factors in upgrading software. There's no harm in wanting to play around with the shiny new toy but many software updates also include much more significant changes, such as resolving bugs or security vulnurabilities.
In fact, bug fixes and security patches are usually released on a more frequent schedule than new feature sets. These changes are necessary to maintain a healthy environment. For this reason, Rittman Mead usually suggests environments are always as up to date as possible with the current releases available.
OBIEE 12.2.1.1 was released this past summer, and it seems to have resolved many issues that plagued early 12C adopters. Recently, OBIEE 12.2.1.2 was also released, resolving even more issues with the early 12C versions. With all of the improvements and fixes available in these versions, an upgrade plan should be a priority to anyone currently on one of the earlier releases of 12c (especially 12.2.1.0).
Okay, so how do I upgrade?
Spencer McGhin has already posted a fantastic blog going over how to perform an in-place upgrade for the 12.2.1.1 release. Even though it was for the previous release, the process is very similar. For those interested in reading a step by step guide, or looking to see what would go into the process, I would suggest reading his post here.
However, with OBIEE 12C's new BAR files, we could take another approach to performing an upgrade. Instead of the traditional "in-place" upgrades, we could perform an upgrade using a different process. We could simply perform a brand new install of this OBIEE version and migrate the existing content using a variety of tools Oracle provides us.
If you choose to "upgrade" your environment by performing a fresh install, implementing the upgrade process will comprise of exporting the required files from OBIEE, removing the old version of OBIEE (if you are using the same machine), installing the new version of OBIEE, and then deploying the previously exported content. This process resembles that of a migration, and can be thought of that way, but migrating between 12C environments seems to be much simpler than migrating to a 12C environment from an older environment.
So an upgrade process could instead look like a brand new installation of the new OBIEE version, and then the execution of a handful of commands provided by Oracle to return the environment to its previous state.
But what would we gain from following this process, rather than a traditional in-place upgrade?
It's worth noting that either approach requires careful planning and testing. Performing a brand new install does not remove the necessity of planning an upgrade process, gathering requirements, identifying all content that must be migrated, testing the installation, testing the migration, and user acceptance and validation testing. The proper process should never be ignored, regardless of the implementation method.
Is there any advantage to a fresh install?
For starters, you won't need to pollute your system with old or deprecated scripts/directories. In Spencer's aforementioned blog, he found that after his upgrade process he had to maintain a second middleware home directory. If you upgrade your environment throughout the years, you may end up with hundreds of unused/deprecated scripts and files. Who enjoys the thought that their environment is full of old and useless junk? A fresh install would cull most of these superfluous and defunct files on a regular basis.
Additionally, there is the occasional bug that seems to reappear in upgraded environments. These bugs usually appear to be from environments that were patched, and then upgraded to a new version, which causes the previously fixed bug to reappear. While these bugs are fixed in future patches, fresh installs are usually free from these kind of issues.
Finally, I would argue a fresh installation can occasionally be simpler than performing the upgrade process. By saving response files used in an installation, the same installation can be performed again extremely easily. You could perform an install in as little as three lines, if not fewer:
/home/oracle/files/bi_platform-12.2.1.2.0_linux64.bin -silent -responseFile /home/oracle/files/obiee.rsp
/home/oracle/Oracle/Middleware/Oracle_Home/oracle_common/bin/rcu -silent -createRepository -databaseType ORACLE -connectString localhost:1521/ORCL -dbUser sys -dbRole sysdba -schemaPrefix DEV -component BIPLATFORM -component MDS -component WLS -component STB -component OPSS -component IAU -component IAU_APPEND -component IAU_VIEWER -f < /home/oracle/files/db_passwords.txt
/home/oracle/Oracle/Middleware/Oracle_Home/bi/bin/config.sh -silent -responseFile /home/oracle/files/configure_obiee.rsp
If this is the case, you can just save the response files set up during the first installation, and reuse them to install each new OBIEE version. Of course the required response file structure could change between versions, but I doubt any changes would be significant.
How do I migrate everything over?
So you've chosen to do a fresh install, you've saved the response files for future use, and you have a brand new OBIEE 12.2.1.2 environment up and running. Now, how do we get this environment back to a state where it can be used?
Before performing the upgrade or uninstall, we need to gather a few things from the current environment. The big things we need to make sure we get is the catalog, RPD, and the security model. We may need additional content (like a custom style/skin or deployments on the Weblogic Server, configurations, etc.) but I will ignore those for brevity. To move some these, I expect you would be required to use the WLST.
Catalog, RPD, and Security Model
Lucky for us, the Catalog, RPD, and Security Model are all included in the BAR export we can create using the exportServiceInstance() function in the WLST. You can then import these to a 12C environment using the importServiceInstance() function. Easy enough, right?
Users
If your users are maintained in the embedded Weblogic LDAP, you must export them and then re-import them. This process can be done manually or through the WLST using the Current Management Object.
If users are maintained through an external Active Directory source, then the configurations will be pulled in with the Security Model in the BAR file.
Testing the migration
The final step is, of course, to make sure everything works! And what better way than to use Oracle's new Baseline Validation Tool. This tool is included in OBIEE 12C, and is perfect for testing migrations between environments.
For those unfamiliar, the basic process is this:
- Configure and run the Baseline Validation Tool against your content.
- Perform the upgrade (be sure to preserve the previously gathered test results)!
- Run the Baseline Validation Tool again to gather the new output, and display the compared results.
The output should be an HTML file that, when opened in a browser, will let you know what has changed since the last time it was run. If everything was migrated properly, then there should be no major discrepancies.
Final Thoughts
Is it better to do an in-place upgrade, or a fresh install and migrate current content? The answer, as always, depends on the business. One method adds complexity but allows for more customization possibilities, while the other is likely faster and a more standard approach. Use whichever works for your specific requirements.
It's an interesting idea to install a new version of OBIEE every so often, rather than perform an upgrade, but maybe for some organizations it will simplify the process and alleviate common upgrade issues. If you or your organization are often stuck on older versions of OBIEE because you are uncomfortable or unfamiliar with the typical upgrade process, maybe you can provision an additional environment and attempt this alternative method.
As previously stated, it is imperative for environments to be as up to date as possible, and this method is simply another, albeit unconventional, avenue to make that happen.
Oracle OpenWorld 2016 – Data Integration Recap
I know it's been about a month since Oracle OpenWorld 2016 concluded, but I wanted to give a brief recap on a few things that I thought were interesting in the data integration space. During the week prior to OpenWorld, I had the privilege to attend the Oracle ACE Director Briefing. Over 2 days, ACE Directors were provided an early preview of what's to come down the Oracle product pipeline. The importance of the event is easy to note as Thomas Kurian himself spends an hour plus providing the initial product overview and answering questions. The caveat, the entire session is under NDA (as you might imagine). But, the good thing is that several of the early preview products were announced the following week at Oracle OpenWorld. Here's what I saw that might impact the Oracle Data Integration product area most.
Data Flow ML
Take an ETL tool, add the cloud, and mix in the latest Big Data technologies and methodologies and you have Data Flow ML. This cloud-based tool is built for stream or batch processing, or both, following the Lambda architecture. Data is ingested into Kafka topics, transformed using Spark Streaming, and loaded into a final target, which may be created automatically by DFML. Along the way, Spark ML is used to profile the data and make suggestions for how to enrich the data with internal or external sources. The technology is still in its early stages but keep an eye out on the Rittman Mead blog for more information over the next few months.
Data Integration in the Cloud
Oracle Data Integrator Cloud Service is coming soon and with it, new licensing options. ODI can be deployed in the cloud on Java Cloud Service or Big Data Cloud Service, or it can be deployed on-premises for more of a hybrid environment. From a licensing perspective, ODICS can be a monthly subscription or you can BYOL (bring your own license) and run ODI from any compute resource. This flexibility allows you to pushdown the transformation execution to the location of the data, rather than moving the data to the transformation engine - a standard for Oracle Data Integrator.
Oracle Data Integrator 12.2.1.2
Coming soon, the next patchset release for Oracle Data Integrator 12c. Features discussed at Oracle OpenWorld were:
- Git Integration and Smart Merge:
This release will introduce a new integration for lifecycle management, Git, adding to the current integration option of Subversion. Not only that, but ODI will finally provide "smart" merge functionality to allow an automated merge of a branch into the trunk. - Kafka and Spark Streaming:
With ODI for Big Data, streaming integration is coming. Use of Apache Kafka as a source or target and Spark Streaming integration for transformations will allow for more real-time processing of data. The introduction of Cassandra as a data source is another enhancement for the Big Data release. - RESTful Connectivity:
Another long awaited feature is REST web service integration. A new technology, similar to the SOAP web service integration, will be available and able to connect to any RESTful service. Along with that, BICS and Storage Cloud Service integration will be introduced.
There are definitely many other interesting looking products and product updates coming (or already here), including GoldenGate Service Architecture, updates to the GoldenGate Cloud Service, Big Data Cloud Service, Big Data Compute and several others. It’s an interesting time as the Oracle shift to the cloud continues - and data integration won’t be left behind.

