Category Archives: Rittman Mead
Financial Reports – which tool to use? Part 1
One of the treats of working in the Business Intelligence world is that we are asked to analyze different aspects of a business. In fact, we are asked to analyze many different types of businesses, too. Most of us using BI tools have come from some previous background. Be it Marketing, Finance, Supply Chain or any other, we most likely had work experience before we got here. Maybe one of our jobs even led to Business Intelligence. The fact is, we are not experts in all areas. It would take several lives to make such a claim, because each area can be very complex and take years to master. The truth, for most of us, is that we have our favorite areas. They are often related to what we are most familiar with.

Over time, I came to really appreciate how simple numbers can be, and developed this - hard to understand - favoritism towards financial reports. While some business areas can be artistic and even vague, numbers are never vague. I have a great appreciation for that. Working with numbers is always precise. In the end, they have to match. No matter how great your report looks, if the numbers don’t add up the report is always wrong. Plus, financial layouts are generally very defined going in, so there is little room for error.
Financials in OBIEE
So, the endeavor begins when you are a BI consultant and everything is supposed to add up properly and look very nice. OBIEE is an extremely powerful tool, and this gives users the impression that it can solve all problems. While it can solve most problems, it falls short on some key features needed for easy financial reporting. That is not to say that Financials can’t be handled in OBIEE - but it is definitely to say that it is not easy.
So, if financial reports are not easy to create in OBIEE, than we are left with two very simple options:
Struggle through it and make it happen
Choose another tool
I have made the mistake of choosing option 1 some times, but quickly realized that option 2 couldn’t be as bad. Countless times, I have been asked to create financial reports in OBIEE. Of course, they needed to tie up and match a specific format: they needed to have blank lines inserted between one section and another, and the alignment of the categories was very important. They often required very detailed variance calculations, so that a company could see where they stood as far as change overtime. Variance percentages are key on these types of reports, and if you have dealt with them in OBIEE, you know that different types of variances and their grand totals can often pose challenges for report writers.
So, in order to accomplish the formatting needed, you end up adding extra code here and there, in essence trying to make OBIEE do something that it’s not supposed to do. Soon, you are experiencing performance issues and a new array of considerations are in place. You start removing your “special code”, then you loose your formatting. The numbers on your financial statement are still correct, but your report looks something like this:
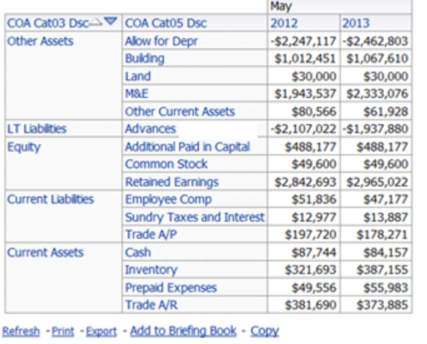
While, in reality, you were trying to get here:

** The Balance Sheet above was created using HFR for illustration of formatting only.
Looking at a different OBIEE financial report (below), you will see that a lot of formatting can be done in these reports, but they will always look like OBIEE reports, if you know what I mean.
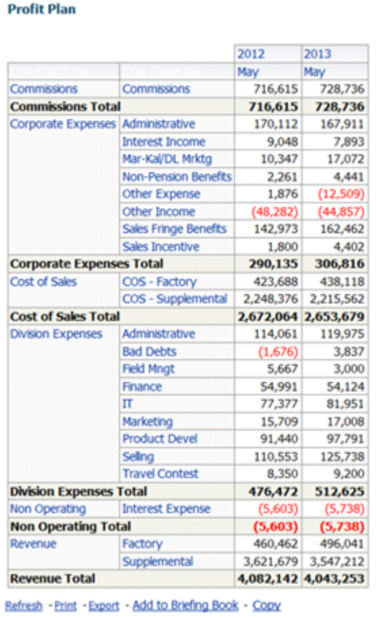
In this example, the first column is out of order - as far as Income Statements go. This was left alone on purpose to display one of the issues with creating these statements in OBIEE. The tool does not easily allow you to choose which items will go in each row. So, in the criteria tab, in Answers, you choose the order of the columns, but if you need the rows in order, you will need to either:
Use a hidden column created just for sorting purposes
Leverage selection steps, or
Create a measure column for each row that you will need, use a pivot table, and add the Measure Labels as rows on your pivot
I will illustrate the third option, as it is my preferred way of ordering rows. Suppose that you have a very simple criteria tab such as this:
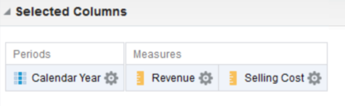
Naturally, your results would default like this on a table:
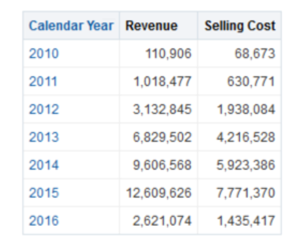
If you use a Pivot table instead, you can drag your Measure Labels onto the Rows:
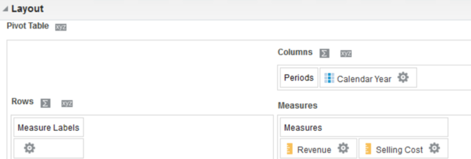
And now, you will be able to see your measures as rows. You can easily reorder them as needed by just moving the order of the columns in the Measures section of your Layout editor.
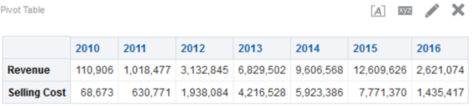
This seems like a simple solution if you know precisely what all your rows should be, and even better, if you don’t have a huge amount of measures on the report. In real life, this type of row ordering is high maintenance:
You must label each measure to match the account category name for each row
You must filter each measure by its account category (or account number)
If the account category name changes in your DB, you must manually rename your columns to match the new naming convention
- If you add or delete account categories, you must manually add and delete columns from your report
OBIEE 12c offers a great improvement in this area: the ability to “save columns” is described very well by Jason Baer on this blog: https://www.rittmanmead.com/blog/2016/01/my-favorite-obiee-12c-feature-that-almost-no-one-is-talking-about/
With the new release of the product you can save as many financial columns as you would like in the web catalog, which allows you to reuse them. As a consequence, you will streamline report maintenance by updating the columns’ format and formula directly from the catalog (instead of inside every report). In fact, if you are spending too much time maintaining your existing reports out of OBIEE 11g, you will automatically benefit from an upgrade to 12c just based on this single feature. Check here for more info: https://www.rittmanmead.com/obiee-12c-upgrade/
This is a great improvement, but you will still need to deal with an overall lack of flexibility for dynamically adding and deleting columns, setting orders, adding blank space, indenting and calculating variances along with proper grand totals.
After spending more time than you should in order to create a simple report, you really start considering other tools. If you are already working in the Oracle stack, the obvious choices will be BI Publisher and Hyperion Financial Reporting (HFR).
Financials in Essbase/HFR
Hyperion Financial Reporting (HFR) brings a powerful solution to financial statements, because it allows you to create pixel perfect reports that are pre-aggregated in an Essbase cube. Just with that, two big problems were just solved: formatting and performance.
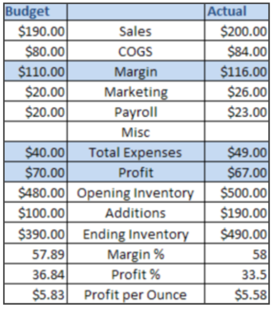
In the example below, you see that HFR allows you to place metrics on both sides of the Account Category (butterfly layout - difficult to accomplish in OBIEE):
In addition to formatting and performance, there are some definite pros to consider when choosing HFR:
The calculations in HFR dynamically reference cells, as in excel. So, if a cell changes, the cells that are referencing the original cell will automatically be updated
HFR has the ability to create financial books and batches, and also has a powerful bursting feature
HFR is a great solution for Income Statements, Balance Sheets and other reports that come from Essbase cubes. In a simplistic way, an Essbase cube is a combination of tables that have been joined and pre-aggregated. Since most tables coming out of a financial module in a system can often be joined, you should be able to create Essbase cubes to use as a source for your HFR reports. You will rarely have a requirement that cannot be handled by HFR and Essbase, but some situations may be problematic, for example, if your report requires a measure to be entered at run-time, if results from multiple cubes need to be added, or if your layout is very complex. This is why :
In an HFR report, you start by inserting a grid onto your report and then you associate that grid with a specific Essbase cube. If you need data from two cubes on the report, you can insert another grid and associate that with the second cube. You can also create a report that leverages calculations between existing grids (for the purpose of doing math with two or more separate cubes):
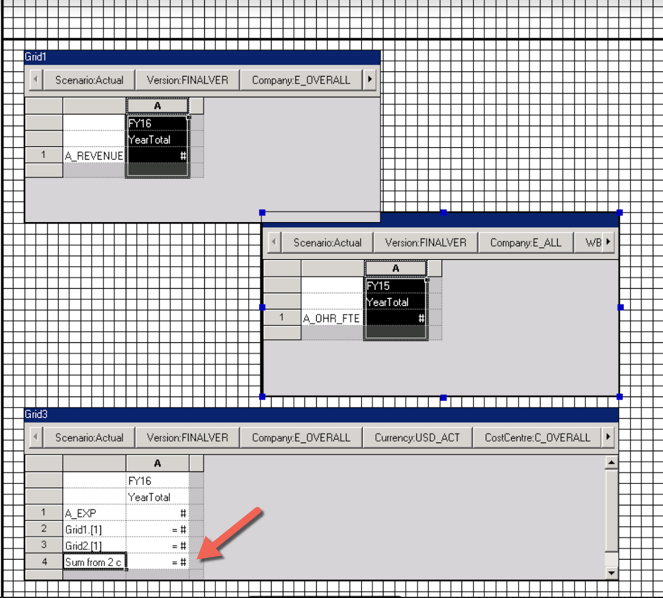
Many thanks to my collegue, Mark Cann https://www.rittmanmead.com/blog/author/mark-cann/, for working through this solution with me
The challenge here is that you may end up with multiple layout grids on your HFR report, which will complicate the report creation and maintenance going forward. It is important to know that if your requirements call for strange off-setting of cells and multiple different looking blocks, then HFR may not be the best tool for the job. If you choose HFR for this purpose, you will spend too much time trying to make things right.
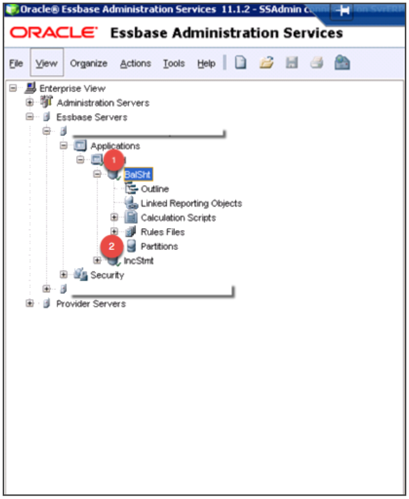
*This is a simple Essbase implementation with 2 cubes (or databases): a Balance Sheet and an Income Statement cube.
The fact is, some financial reports are very tricky and do not come solely from a Financial module. For example, if your company is evaluated monthly for a line of credit, your bank may require to look at several components of your business in order to determine the amount that you can borrow. They will base their decision not only on your monthly revenue, but also your liabilities, such as accounts payables, and some of your assets, such as inventory. What they ask for really depends on their internal lending requirements, and also on the type of business that you have. These are, therefore, highly customized reports that never come out-of-the box anywhere. For this reason, most companies spend a lot of man hours creating these reports as a huge excel report, after the employees have managed to pull information from many different modules together.
These excel “monsters” do the job. They are accepted by the banks, and will get you that loan. On the downside, they need to be redone every month and will drag resource hours out of profitable projects. The flat excel files are also prone to mistakes, as the values are manually keyed in each time. If you make a mistake favorable to the company, your bank will look at it as a very negative issue. If you make an unfavorable mistake, you will not be able to borrow as much as you qualify for. This is a no win situation, so the reports must be accurate every time.
 To check for accuracy, there is nothing like testing overtime. But, since you must rework the report each month, you don’t have that opportunity.
To check for accuracy, there is nothing like testing overtime. But, since you must rework the report each month, you don’t have that opportunity.
The solution is to create a template that will pull from all of these different modules, calculate the numbers, add the results automatically to a pixel perfect formatted report. Over the development cycle, these mappings and calculations will be thoroughly tested, and then they will only be reused going forward.
While you may spend some time pulling this logic together, you will only have to click a few buttons after you are done, for months or years to come. In fact, I have clients that have been running reports such as this one for years. They have been saving a couple of weeks in report creation every month.
Let’s look at an example of what I am talking about:
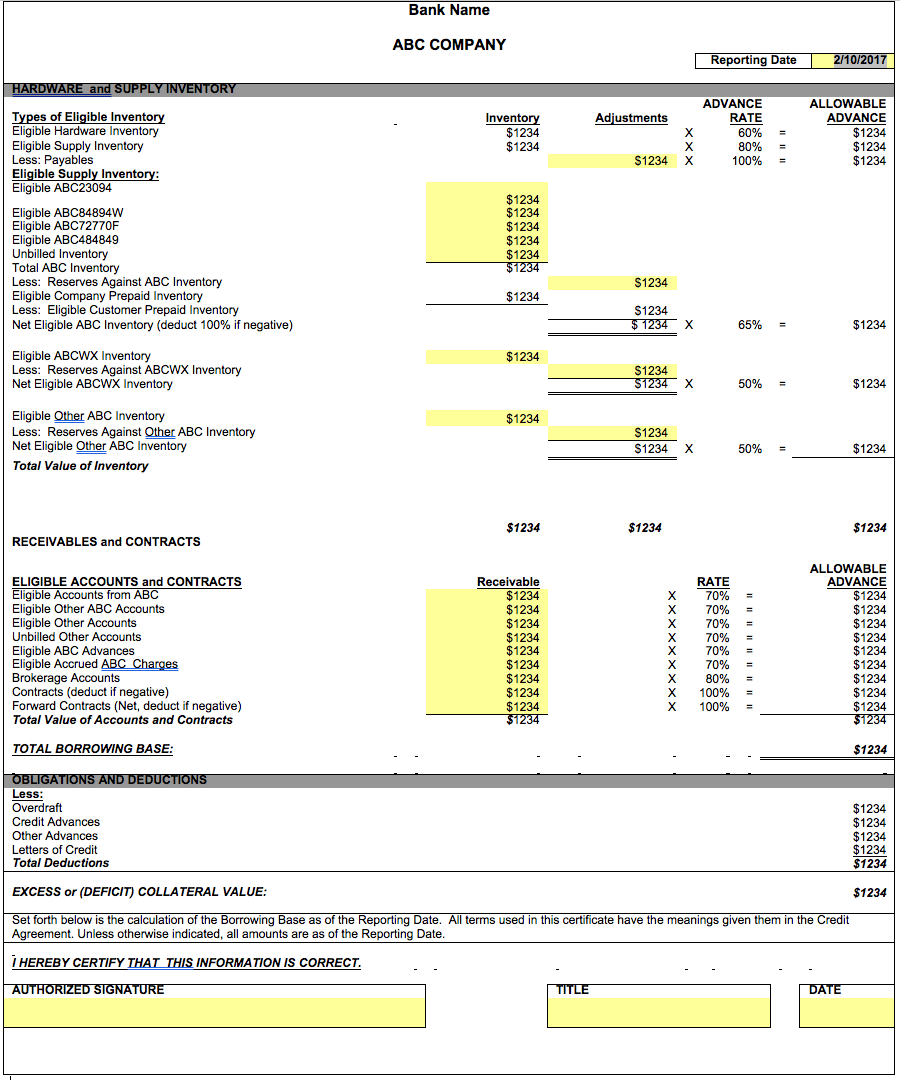
On this report, each number (disguised as $1234) has been mapped to a calculation that will be pulled dynamically, according to the date entered on the prompt. The inventory amounts are adjusted according to banking requirements, and a rate is allocated depending on the row. This amount is later added/subtracted from receivables and existing contracts. Most of these numbers were created as separate OBIEE analyses. Some amounts could even be tied into web services to get the daily futures prices to estimate the value of contracts when the report runs. All lines are considered in the final equation before the total borrowing amount can be calculated. Per this bank’s requirement, this form needed to be printed and signed, then submitted monthly.
Lending/financing reports may be the most tricky, and the most time consuming for companies to generate every month. The reports may be required by the bank, or by a company that is leasing or financing valuable equipment to your company. These reports need to show your prospective lender everything about your business. They will often need to be done in a format that is specified by your lender. These formats are not negotiable, in fact, some lenders still use old forms that used to be read by a machine.
Here is another small snippet of a financing report that I had to create recently. Now, which tool would you use for 10 different pages of something like this, which required some of the amounts to be entered in the prompt? *Note: the report had to look “exactly” like this:
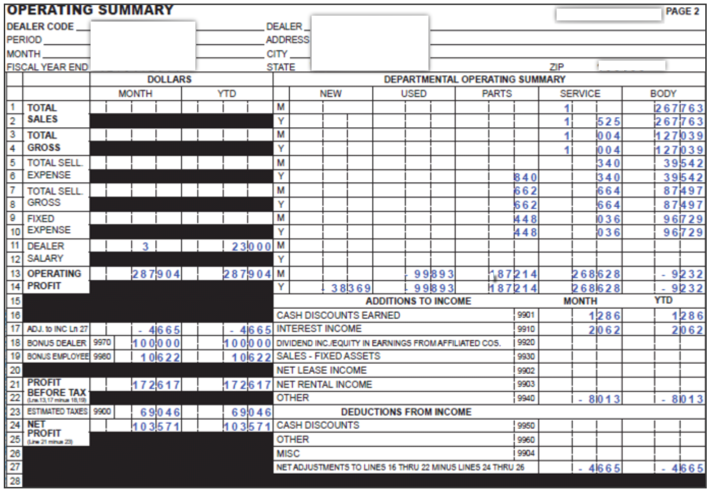
Well, as I mentioned in the beginning of this article, OBIEE would not be your partner in this type of endeavor. I can guarantee that this relationship would fail: strange formatting with black boxes, line numbers, need for Headers (footers too, not shown here), indenting, etc.
You may consider Essbase/HFR combo, for formatting and performance, but you will soon realize that:
Performance does not tend to be an issue with these reports, as they are generally submitted to lenders on a monthly basis, and therefore can be scheduled to run automatically in the middle of the night.
As mentioned earlier, HFR requires a layout grid to be inserted before the report can be designed. Here, you would end up with multiple grids to handle the calculation of different cells from multiple cubes - which can be cumbersome to create and maintain.
The measures in an HFR report should come from the pre-aggregated cube. In this example, some of the measures were entered as part of the prompt and are calculated at run time. At this point, you must scratch the Essbase/HFR option for this one!
So, now you are still stuck with your monster excel spreadsheet, then retyping the numbers onto the required form.
Before you marry this solution, let me present you with the tool that can do everything: BI Publisher.
Stay tuned for the second part of this blog, when I will share why I believe that BIP can solve the most challenging reporting requirements out there!
Enabling Concurrent OBIEE RPD Development – for free
One of the most common and long standing problems with developing in OBIEE is the problem of multiple developers working on the RPD at the same time. This blog explains the problem and explores the solution that we’ve developed and have been successfully using at clients over the last couple of years. We’re pleased to announce the immediate availability of the supporting tools, as part of the Rittman Mead Open Source Project.
Before we get into the detail, I'll first explain a bit about the background to the requirement and the options that ship with OBIEE.
Why Concurrent Development
The benefits of concurrent development are obvious: scalability and flexibility of development. It enables you to scale your development team to meet the delivery demands of the business. The challenge is to manage all of the concurrent work and enable releases in a flexible manner - which is where source control comes in.
We couldn't possibly attempt to manage concurrent development on something as complex as the RPD without good version control in place. Source control (A.K.A. version control/revision control) systems like Git and Apache Subversion (SVN) are designed to track and retain all of the changes made to a code base so that you can easily backtrack to points in time where the code was behaving as expected. It tracks what people changed, who changed it, when they changed it and even why they made that change (via commit messages). They also possess merge algorithms that can automatically combine changes made to text files, as long as there are no direct conflicts on the same lines. Then there's added benefits with code branching and tagging for releases. All of this leads to quicker and more reliable development cycles, no matter what the project, so good in fact that I rely on it even when working as one developer. To (mis)quote StackOverflow, "A civilised tool for a civilised age".
All of these techniques are about reducing the risk during the development process, and saving time. Time spent developing, time spent fixing bugs, spent communicating, testing, migrating, deploying and just about every IT activity under the sun. Time that could be better spent elsewhere.
Out of the Box
Oracle provide two ways to tackle this problem in the software:
- Online Check in/out
- Multi-User Development (MUD)
However I believe that neither of these are sufficient for high standards of reliable development and releases - the reasons for which I explore below (and have been described previously). Additionally it is not possible to natively and fully integrate with version control for the RPD, which again presents a significant problem for reliable development cycles.
Firstly the online check-in and check-out system does, by design, force all development to be conducted online. This in itself is not an issue for a single developer, and is in fact a practice that we advocate for ‘sandbox’ development in isolation. However, as soon as there is more than one developer on the same server it reduces development flexibility. Two developers cannot develop their solutions in isolation and can be made to wait for assets they want to modify to be unlocked by other developers. This may be workable for a small amount of developers but does not scale well. Furthermore, the risk of losing work is much higher when working online; we've all seen the infamous "Transaction Update Failed" message when saving online. This is usually because of an inconsistency in the RPD but can be caused by less obvious reasons and usually leads to repeating some redundant work. Lastly, very large RPDs like those from BI Apps or very mature enterprise deployments pose a problem when working online. They cause the Admin Tool to work very slowly because of the calls it has to make to the server, which can be frustrating for developers. To be clear, I am certainly not advocating developing without testing your code, but given the speed of uploading an RPD to the server and the fact that it can be automated, in my experience it is far more efficient to develop offline and upload frequently for testing.
The MUD system is much better and is quite close in methodology to what we recommend in this guide. The premise works on having a production quality master RPD and then having many other individual developers with their own RPDs. The check-in and check-out system will automatically handle three-way merges to and from the master RPD when development changes are made. This is good in theory but has been maligned for years when used in practice. The version control system in MUDE is not as robust as Git or SVN for example and the conflict resolution relies on developers managing their own issues, without the ability for a source master to intervene. Ultimately there is little flexibility in this method, which makes it difficult to use in the real world.
Source Controlling the RPD
Source control is another problem as the RPD is a binary file which cannot be merged or analysed by text-based comparison tools like SVN or Git. A potential solution at one point seemed to be MDS XML, a structured, textual representation of the RPD. However, this also seemed to have some drawbacks when put into practice. Whilst some use MDS XML with great success and there are tools on the market that rely on this system, here at Rittman Mead we’ve found that there are significant risks and issues with it. We’ve come up with what we believe is a robust, scalable, and flexible approach, based around the binary RPD.
The Rittman Mead Solution to Concurrent OBIEE RPD Development
Successful development lifecycles comes down to implementation of the correct process and ensuring it is as quick and reliable as possible. Tools, like the ones described in this blog, can be used to help in both of those areas but are not a substitute for detailed knowledge of the processes and the product. A key feature of this approach is the Source Master who owns and is responsible for the overall development process. They will have a detailed understanding of the method and tools, as well as the specifics of the current and future work being done on the RPD. Things will go wrong, it is as inevitable as death and taxes - the key is to minimise the impact and frequency of these events.
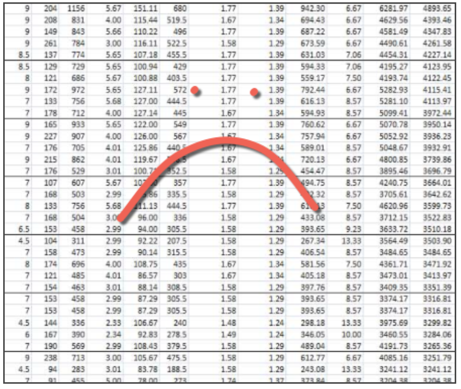
The solution is based on the Gitflow method, which is one of the most established development models. The model is based on a few major concepts:
- Features - Specific items of development, these are begun from the development branch and then merged back into development when complete.
- Develop/Master Branches - Two branches of code, one representing the development stream, the other the production code.
- Releases - A branch taken from development that is then eventually merged into production. This is the mechanism for getting the development stream into production.
I highly recommend reading that blog and this cheatsheet as they explains the method excellently and what we've done here is support that model using binary RPDs and the 3-way merge facility in OBIEE. Also of relevance is this Rittman Mead blog which describes some of the techniques we're explaining here. We've open sourced some command line tools (written in Python) to ease and automate the process. You can download the code from the GitHub repository and need only an install of Python 2.7 and the OBIEE client to get started. The tooling works with both git and Subversion (SVN). We recommend the use of git, but realise that SVN is often embedded at organisations and so support that too.
Scenario
This section shows a simple example of how you might use this methodology for multiple developers to work on the RPD in a reliable way. Many of the screenshots below show SourceTree, a GUI for Git which I'm a fan for both its UI and GitFlow support.
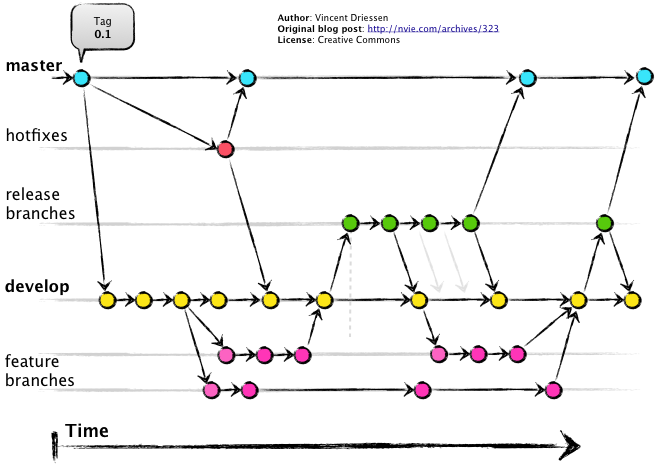
We have two developers in our team, Basil and Manuel, who both want to work on the RPD and add in their own changes. They already have an RPD they've made and are using with OBIEE, named base.rpd. First they initialise a Git repository, committing a copy of their RPD (base.rpd).
The production branch is called master and the development branch develop, following the standard naming convention for GitFlow.
Before we get started, let's a take a look at the RPD we're working with:
Simple Concurrent Development
Now Basil and Manuel both independently start features F01 and F02 respectively:
python obi-merge-git.py startFeature F01
Each developer is going to add a measure column for Gross Domestic Product (GDP) to the logical fact table, but in different currencies. Basil adds "GDP (GBP)" as a logical column and commits it to his development branch, F01. Manuel does the same on his, adding "GDP (USD)" as a logical column and committing it to F02.
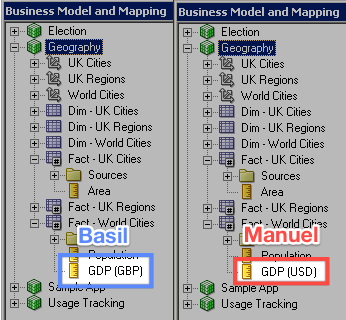
Now Basil finishes his feature, which merges his work back into the develop branch.
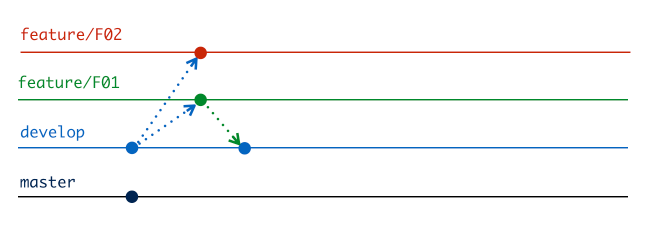
This doesn't require any work, as it's the first change to development to occur.
python obi-merge-git.py finishFeature F01
Checking out develop...
Already on 'develop'
Merging feature/F01 into develop...
Successfully merged feature/F01 to the develop branch.
When Manuel does the same, there is some extra work to do. To explain what's happening we need to look at the 3 merge candidates in play, using the terminology of OBIEE’s 3-way merge functionality:
- Original: This is the state of the development repository from when the feature was created.
- Modified: This is your repository at the time of finishing the feature.
- Current: This is the state of the development repository at the time of finishing the feature.
When Basil completed F01, the original and current RPDs were the same, so it could just be overridden with the new RPD. However now, the Original and Current RPDs are different, so we need to resolve the changes. Our RPDs are binary files and so we need to use the 3-way merge from the Admin Tool. The python script wrapped around this process uses Git’s metadata to determine the appropriate merge candidates for invoking the OBIEE 3-way merge.
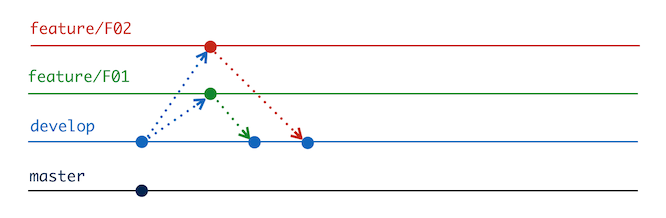
Since our changes do not conflict so this can happen automatically without user intervention. This is one of the critical differences from doing the same process in MDS XML, which would have thrown a git merge conflict (two changes to the same Logical Table, and thus same MDS XML file) requiring user intervention.
python obi-merge-git.py finishFeature F02
Checking out develop...
Already on 'develop'
Merging feature/F02 into develop...
warning: Cannot merge binary files: base.rpd (HEAD vs. feature/F02)
Creating patch...
Patch created successfully.
Patching RPD...
RPD patched successfully.
RPD Merge complete.
Successfully merged feature/F02 to the develop branch.
In the background the script uses the comparerpd and patchrpd OBIEE commands.
Release
Now our development branch has both features in, which we can see using the Admin Tool:
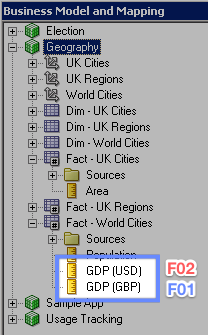
To get this into production we can start a release process:
python obi-merge-git.py startRelease v1.00
This creates a new branch from develop that we can use to apply bug fixes if we need to. Any changes made to the release now will be applied back into development when the release is complete as well as being merged into the production branch. The developers realise they have forgotten to put the new columns in the presentation layer, so they do it now in the release branch as a bugfix. In GitFlow, bugfixes are last minute changes that need to be made for a release but do not interfere with the next development cycle, which may have already begun (in the develop branch) by the time the bug was spotted. The changes are merged back to develop as well as master so the fix isn't lost in the next cycle.
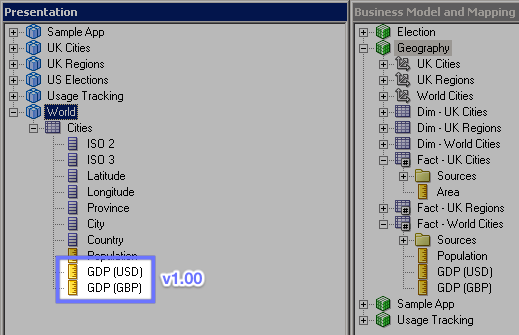
This is committed to the repo and then the release is finished:
python obi-merge-git.py finishRelease v1.00
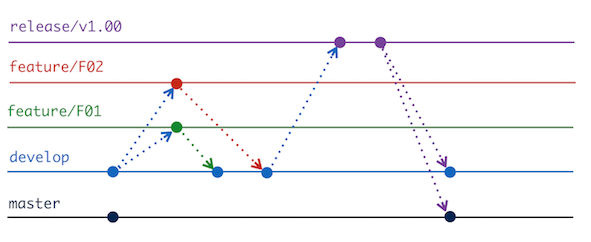
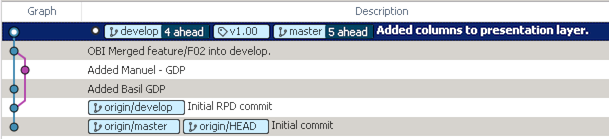
After the release we can see that the master and develop branches are at the same commit point, with a tag of the release name added in too. Additionally we can switch to the develop and master branches and see all of the changes including the columns in the presentation layer. The full commit history of course remains if we want to roll back to other RPDs.
Conflicted Development
Basil and Manuel start their new features, F03 and F04 respectively. This time they’re working on the same existing column - something that a “Source Master” should have helped avoid, but missed this time. Basil edits the column formula of the "Area" column and renames it to "Area (sqm)"" and Manuel does the same, naming his column "Area (sqFt)".
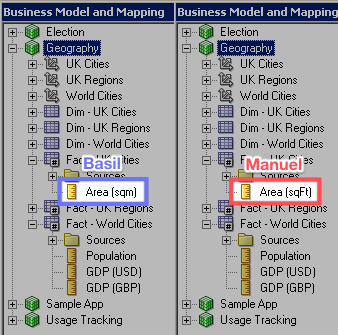
They both commit the changes to their own feature branches and Manuel merges his back to development with no problem.
python obi-merge-git.py finishFeature F04
However when Basil tries to finish his feature the obvious conflict occurs, as the automatic merge cannot resolve without some human intervention since it is the same object in the RPD affected by both changes. At this point, the script will open up the current RPD in the Admin Tool and tell Basil to merge his changes manually in the tool, going through the usual conflict resolution process. The script provides 3 RPDs to make the RPD choosing step unambiguous:
original.rpdmodified.rpdcurrent.rpd(Opened)
python obi-merge-git.py finishFeature F03
Checking out develop...
Already on 'develop'
Merging feature/F03 into develop...
warning: Cannot merge binary files: base.rpd (HEAD vs. feature/F03)
Creating patch...
Patch created successfully.
Patching RPD...
Failed to patch RPD. See C:\Users\Administrator\Documents\obi-concurrent-develop\patch_rpd.log for details.
Conflicts detected. Can resolve manually using the Admin Tool.
Original RPD: C:\\Users\\Administrator\\Documents\\rpd-test\a.rpd (original.rpd)
Current RPD: C:\\Users\\Administrator\\Documents\\rpd-test\c.rpd (Opened)
Modified RPD: C:\\Users\\Administrator\\Documents\\rpd-test\b.rpd (modified.rpd)
Perform a full repository merge using the Admin Tool and keep the output name as the default or C:\\Users\\Administrator\\Documents\\rpd-test\base.rpd
Will open RPD using the Admin Tool.
Press Enter key to continue.
You must close the AdminTool after completing the merge manually in order for this script to continue.
When Basil hits a key, the Admin Tool opens up, and from here he needs to manually initiate the merge and specify the merge candidates. This is made easy by the script which automatically names them appropriately:
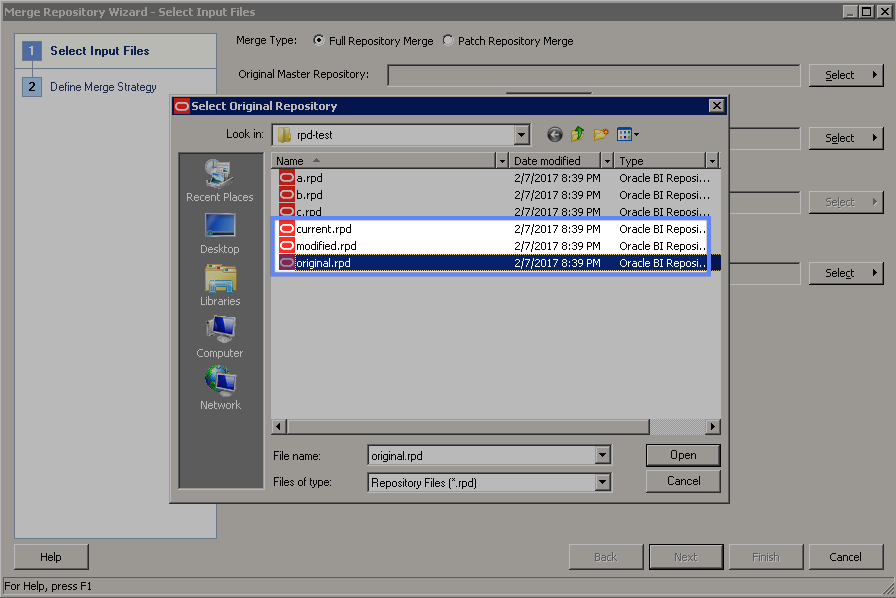
Note that the a, b and c RPDs are part of the merge logic with Git and can be ignored here.
Basil assigns the original and modified RPDs to the correct parts of the wizard and then resolves the conflict (choosing his change) in the next step of the wizard.
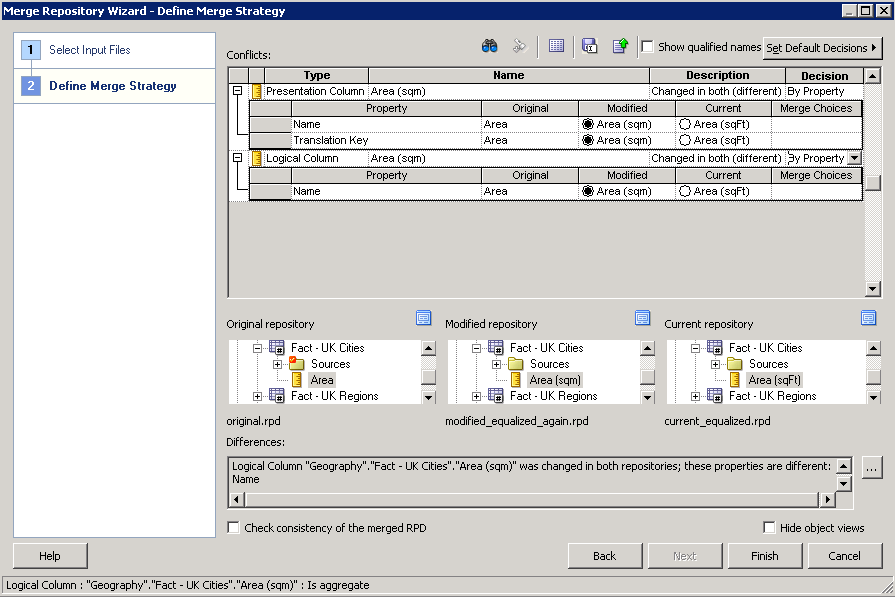
Upon closing the Admin Tool, the Git merge to the develop branch is automatically completed.
Now when they look in the development RPD they can see the column named as "Area (sqm)", having accepted Basil's change. Of course this is a trivial example, but because the method relies on using the Admin Tool, it will be just as reliable as a manual 3-way merge you would perform in OBIEE.
In my experience, most of the problems with 3-way merging is that developers get confused as to which candidates to choose or they lose track of a true original point from when both developers started working. Using this method eliminates both of the those problems, with the added benefit of tight integration into source control. Even with an easier interface to the 3-way merge process, developers and/or the Source Master should be aware of some of the ‘features’ of OBIEE’s 3-way merge. For example, if a change has occurred on the physical layer which does not have any representations at all in the business or presentation layers, it may be lost during a 3-way merge. Another is that the merge rules are not guaranteed to stay the same between OBIEE versions, which means that we cannot be certain our development lifecycle is stable after patching or upgrading OBIEE.
So given this, and as a general core tenet of good software development practice, you should be automatically testing your RPDs after the merge and before release.
Testing the RPD
There are still issues with OBIEE RPD merging that aren't rectified by the 3-way merge and so must be handled manually if and when they occur. One such example is that if a change has occurred on the physical layer which does not have any representations at all in the business or presentation layers, it may be lost during a 3-way merge. Another problem is that the merge rules are not guaranteed to stay the same between OBIEE versions, which means that we cannot be certain our development lifecycle is stable after patching or upgrading OBIEE. Another thing I don't really like is the inherent bias the merge process has toward the modified RPD, instead of treating the modified and current RPDs equally. The merge candidates in the tool have been selected in such a way as to mitigate this problem but I am wary it may have unforeseen consequences for some as yet untested scenarios. There are may be other inconsistencies, but it is difficult to pin down all of the scenarios precisely and that's one of the main stumbling blocks when managing a file as complex as the RPD. Even if we didn't receive any conflicts, it is vital that RPDs are checked and tested (preferably automatically) before release.
The first step to testing is to create a representative test suite, which will encompass as much of the functionality of your system in as few reports as possible. The reason for this is that it is often impractical and sometimes invalid to check the entire catalogue at once. Furthermore, the faster the testing phase occurs, the quicker the overall release process will be. The purpose of a test suite is so that we can take a baseline of the data of each report from which we can validate consistency after making changes. This means your test suite should contain reports that are expected not to change after making changes to RPD. Furthermore you need to be careful that the underlying data of the report does not change between the baseline capture and the regression validation phases, otherwise you will invalidate your test.
In terms of tooling, Oracle provide BVT which can be used outside of upgrades to perform automated regression tests. This is good as it provides both data checks as well as visual validation. Furthermore, it can be run on a specific Web/Presentation Catalog folder directly, as opposed to the whole system.
As well as Oracle’s BVT, we also have an in-house Regression Testing tool that was written prior to BVT’s availability, and is still used to satisfy specific test scenarios. Built in Python, it is part of a larger toolset that we use with clients for automating the full development lifecycle for OBIEE, including migrating RPDs and catalogue artefacts between environments.
This brings us onto the last piece in the DevOps puzzle is continuous integration (CI). This is the concept of automatically testing and deploying code to a higher environment as soon as the work is complete. This is something not explicitly covered by the tools in this blog, however would work nicely used with the testing and migration scripts described above. This could all be made seamless by invoking the processes via script calls or better using Git hooks.
Summary
The success of an OBIEE concurrent development approach comes down to two things: the tooling, and the rigorous implementation of the process - and it is the latter that is key. In this article I’ve demonstrated the tooling that we’ve developed, along with the process required for a successful development method. Here at Rittman Mead we have detailed understanding and experience in the process and framework necessary to implement it at any client, adapting and advising to ensure the integration into existing in-house development and release requirements. The real world is messy and developers don't all work in the same way. A single tool in isolation is not going to succeed in making OBIEE - designed from the outset as a single-developer tool - scale to multiple developers. Instead of insisting that you change to accommodate our tool, we instead bring our tool and process and adapt to suit you.
You can find the code used in this blog up on GitHub and if you would like to discuss how Rittman Mead can help implement concurrent OBIEE RPD development successfully at your organisation, please get in touch.
Working with OBIEE Data in Excel using ODBC
Look at this picture. I'm sure you've recognised the most favourite data analysis tool of all times - Excel.

But what you can't see in this picture is the data source for the table and charts. And this source is OBIEE's BI Server. Direct. Without exports or plugins!
Querying OBIEE Directly from Excel? With No Plugins? What Is Going On!

The OBIEE BI Server (nqsserver / OBIS) exposes an ODBC interface (look here if you live in a world full of Java and JDBC) which is used by Presentation Services and Administration tool. But a lesser-known benefit of this is that we can utilise this ODBC interface for own needs. But there is a little problem with the OBIEE 12c client installation - its size. Full (and the only possible actually) client OBIEE installation is more than 2 gigabytes and consists of more than 31 thousand files. Not a huge problem considering HDD sizes and prices but something not so good if you have an average-sized SSD.
And the second point to consider. We don’t want to give a full set of developer tools to an end-user. Even if our security won’t let them break anything, why would we stuff his head with unnecessary things? Let's keep things simple.
So what I had in mind with this research was to make a set of OBIEE ODBC libraries as small as possible. And the second aim was avoiding a full installation with cutting out redundant pieces. I need a small "thing" I can easily copy to any computer and then use it.
Disclaimer. Everything below is a result of our investigation. It’s not a supported functionality or Oracle’s recommendation.
I will not describe in full details the process of the investigation as it is not too challenging. It's less a detective thriller and more a tedious story. But anyways the main points will be highlighted.
Examine Working Copy
The first thing I needed to know what changes Oracle's installer does during an installation. Does it copy something to the Windows folder or everything stays in its installation folder? Does it make any registry changes (apparently it does but what exactly)?
For this task, I took a fresh Windows, created a dump of the registry and folders structure of the Windows folder, then installed OBIEE client using normal installation process, made the same dumps and compared them once again.
There were no surprises. OBIEE installer doesn't copy a single byte to the Windows folder (and it's a good news I think) but it creates a few registry keys (what was expected). Anyone who has ever tried to play around Windows ODBC won't be surprised with it at all.


I deleted some keys in order to make this screenshots more clear and readable.
So now I know names of the DLLs and their places. A good point to start. A small free utility Dependency walker helped me to find out a set of DLLs I need. This tool is very easy to use and very useful for finding a missing DLL. Just give it a DLL to explore and it will show all DLLs used by it and mark all missing.
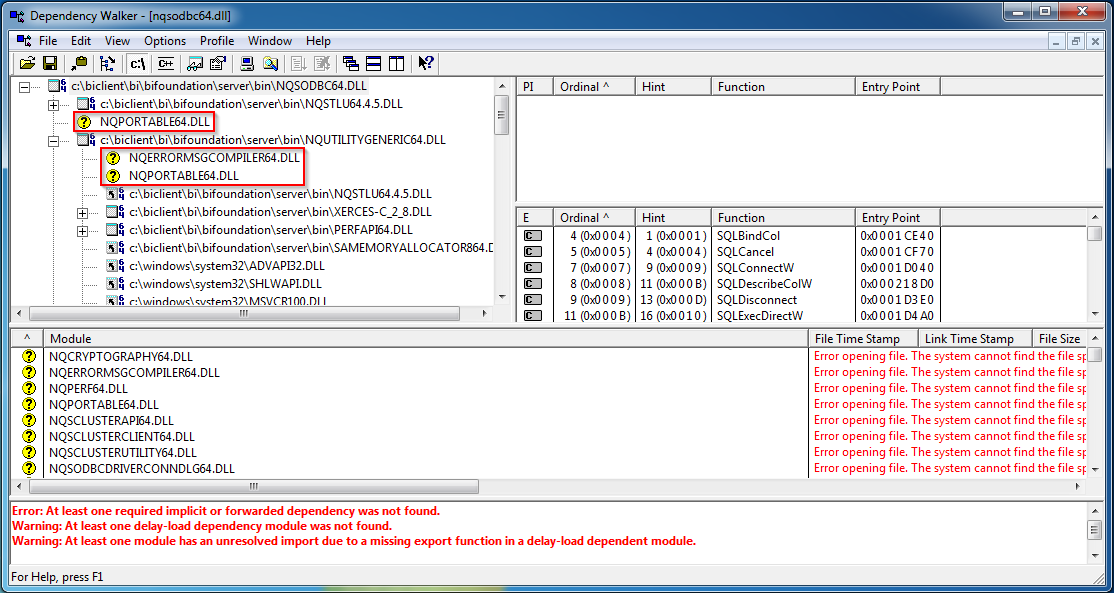
And a bit of educated guess helped to find one more folder called locale which stores all language files.
So, as a result, we got a tiny ODBC-related OBIEE client. It's very small. With only English locale it has a size about 20 megabytes and consists of 75 files. Compare it to 31 thousand files of the full client.
So that was a short story of looking and finding things. Now goes some practical result.
Folders Structure.
It seems that some paths are hard-coded. So we can't put DLLs to any folder we like. It should be something\bi\bifoundation\server. C:\BI-client\bi\bifoundation\server for example.
The List of DLLs
I tried to find the minimum viable set of the libraries. The list has only 25 libraries but it takes too much place on the screen so I put them into a collapsible list in order to keep this post not too long. These libraries should go under bin folder. C:\BI-client\bi\bifoundation\server\bin for example.
The list of ODBC DLLs
BiEndPointManagerCIntf64.dllmfc100u.dllmsvcp100.dllmsvcr100.dllnqcryptography64.dllnqerrormsgcompiler64.dllnqmasutility64.dllnqperf64.dllnqportable64.dllnqsclusterapi64.dllnqsclusterclient64.dllnqsclusterutility64.dllnqsodbc64.dllnqsodbcdriverconndlg64.dllnqssetup.dllNqsSetupENU.dllnqstcpclusterclient64.dllNQSTLU64.4.5.dllnqutilityclient64.dllnqutilitycomm64.dllnqutilitygeneric64.dllnqutilitysslall64.dllperfapi64.dllsamemoryallocator864.dllxerces-c_2_8.dll
Or you may take the full bin folder. Its size is about 240 megabytes. You won't win the smallest ODBC client contest but will save a few minutes of your time.
Locale
The second folder you need is locale, it is located near bin. C:\BI-client\bi\bifoundation\server\locale, for example. Again if you agree with not the smallest client in the world, you may take the whole locale. But there are 29 locales and I think most of the time you will need only one or two of them. Every locale is about 1.5 megabytes and has 48 files. A good place for some optimisation in my opinion.
Registry Key
And the last part is registry keys. I need to tell my Windows what is my driver name and what is its path and so on. If it was a usual part of the registry I'd created a file anything.reg, put a code like this into it and imported it into the registry.
Windows Registry Editor Version 5.00
[HKEY_LOCAL_MACHINE\SOFTWARE\ODBC\ODBCINST.INI\ODBC Drivers]
"Oracle BI Server 12.2.1.2"="Installed"
[HKEY_LOCAL_MACHINE\SOFTWARE\ODBC\ODBCINST.INI\Oracle BI Server 12.2.1.2]
"ConnectFunctions"="YYN"
"Driver"="C:\\BI-client\\bi\\bifoundation\\server\\bin\\NQSODBC64.dll"
"DriverODBCVer"="03.52"
"FileUsage"="0"
"Setup"="C:\\BI-client\\bi\\bifoundation\\server\\bin\\nqssetup.dll"
"SQLLevel"="2"
"UsageCount"="dword:00000001"
"APILevel"="3"
"Regional"="Yes"
"PrimaryCCS"=""
"PrimaryCCSPort"=""
"SecondaryCCS"=""
"SecondaryCCSPort"=""
"Port"=""
But luckily there is a small console utility which makes the task easier and more elegant - scripted. Microsoft provides us a tool called odbcconf.exe located in C:\Windows\System32 folder. And its syntax is not very obvious but not too hard also. Generally the syntax is the following: odbcconf.exe /a {action "parameters"}. In this case the call is odbcconf.exe {installdriver "Oracle BI Server 12.2.1.2|Driver=C:\BI-client\bi\bifoundation\server\bin\nqsodbc64.dll|Setup=C:\BI-client\bi\bifoundation\server\bin\nqssetup.dll|APILevel=2|SQLLevel=2|ConnectionFunctions=YYN|DriverODBCVer=03.52|Regional=Yes"}. Here installdriver is the action and the long string is the set of parameters divided by |. It may look a bit complicated but in my opinion it leaves less space for manual work and therefore less space for error. Just one note: don't forget to start a cmd windows as administrator.

Visual C++ Redistributable
If your computer is fresh and clean, you need to install a Visual C++ 2010 redistributable package. It's included in Oracle's client and placed in 'Oracle_Home\bi' folder. The file name is vcredist_x64.exe.
Result
And as a result I got an ODBC driver I can use as I want. And not obvious but pleasant bonus is that I can give it any name I like. OBIEE version, path, whatever I want.
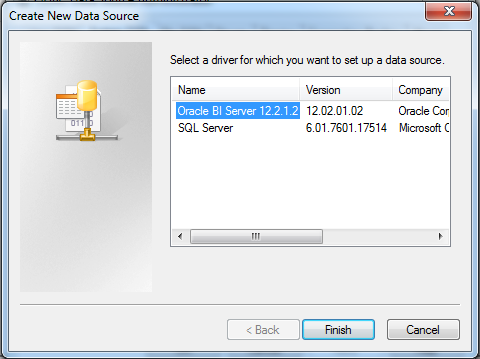
And I can create an ODBC DSN in a normal way using ODBC Data source Administrator. Just like always. No matter this is a hand-made driver. It was properly registered and it is absolutely legitimate.
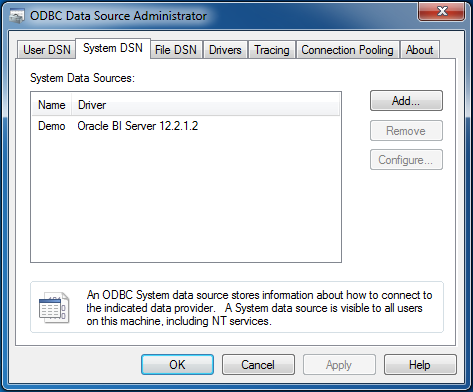
So just a brief intermediate summary. We can take a full 2+ gigabytes OBIEE client. Or we can spend some time to:
1. Create a folder and put into it some files from the Oracle OBIEE client;
2. Create a few registry keys;
3. Install a Visual C++ 2010 redistributable
And we will get a working OBIEE ODBC driver which size is slightly above 20 megabytes.
Demo
So now we have a working ODBC connection, what can it give us?
Meet the most beloved by end users all around the world tool - Excel.

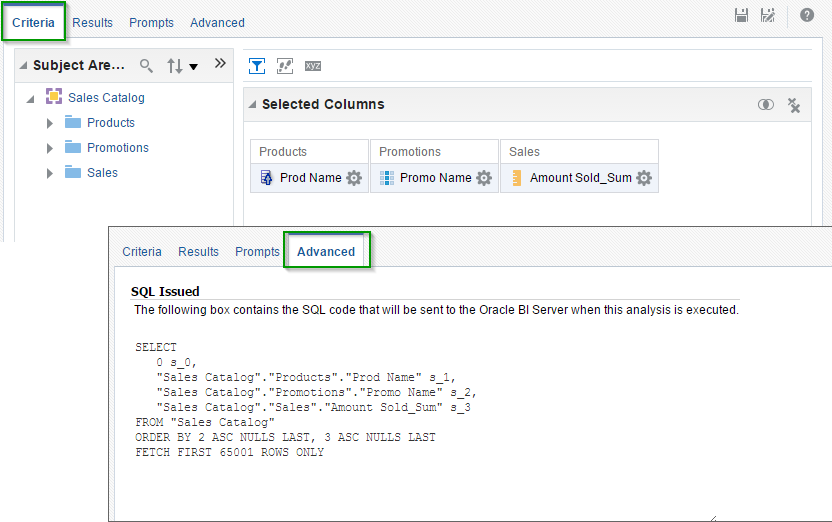
At this point of the story, some may tell me "Hey, stop right there! Where have you got that SQL? And why is it so strange? That's not an ANSI SQL". The evil part of me wants to simply give you a link to the official documentation: Logical SQL Reference and run away. But the kind one insists that even while documentation has done no harm to anyone, that's not enough.
In a nutshell, this is an SQL that Presentation services send to BI Server. When anyone builds an analysis or runs a dashboard, Presentation services create and send logical queries to BI Server. And we can use it for our own needs. Create an analysis as usual (or open an existing one), navigate to the Advanced tab, and then copy and paste analysis' Logical SQL. You may want to refine it, maybe remove some columns, or change aliases, or add a clause or two from the evil part's documentation, but for the first step just take it and use it. That simple.
And of course, we can query our BI server using any ODBC query tool.

And all these queries go directly to the BI Server. This method doesn't use Presentation Services, OBIEE won't build a complex HTML which we have to parse later. We use a fast and efficient way instead.
Join Rittman Mead at the 2017 BIWA Summit!

We invite you to come join us at the annual 2017 BIWA Summit.

This year we are proud to announce that Robin Moffatt, Head of Research and Development, will be presenting on:
Analysing the Panama Papers with Oracle Big Data Spatial and Graph
January 31, 2017 | 3:45 pm – 4:15 pm | Room 103
Oracle Big Data Spatial and Graph enables the analysis of datasets beyond that of standard relational analytics commonly used. Through Graph technology relationships can be identified that may not otherwise have been. This has practical uses including in product recommendations, social network analysis, and fraud detection. In this presentation we will see a practical demonstration of Oracle Big Data Spatial and Graph to load and analyse the “Panama Papers” dataset. Graph algorithms will be utilised to identify key actors and organisations within the data, and patterns of relationships shown. This practical example of using the tool will give attendees a clear idea of the functionality of the tool and how it could be used within their own organisation. If Oracle Database 12cR2 on-premise is available by the time of this presentation, then its new property graph capabilities will also be covered here. The presentation will be based on a paper published on OTN: https://community.oracle.com/docs/DOC-1006400
Kafka’s Role in Implementing Oracle’s Big Data Reference Architecture on the Big Data Appliance
February 1, 2017 | 2:20 pm – 3:10 pm | Room 102
Big Data … Big Mess? Everyone wants Big Data, but without a good platform design up front there is the risk of a mess of point-to-point feeds. The solution to this is Apache Kafka, which enables stream or batch consumption of the data by multiple consumers. Implemented as part of Oracle’s Big Data Architecture on the Big Data Appliance, it acts as a data bus for the enterprise to both the data reservoir and discovery lab. This presentation will introduce the basics of Kafka, and explain how it fits within the Big Data Architecture. We’ll then see it used with Oracle GoldenGate to stream data into the data reservoir, as well as ad hoc population of discovery lab environments and microservices such as Flume, HBase, and Elasticsearch.
(Still) No Silver Bullets: OBIEE 12c Performance in the Real World
February 2, 2017 | 1:30 pm – 2:20 pm | Room 203
Are you involved in the design and development of OBIEE systems and want to know the best way to go about ensuring good performance? Maybe you’ve an existing OBIEE system with performance “challenges” that you need to diagnose? This presentation looks at the practical elements of diagnosing the causes of performance issues in OBIEE, and discusses good practices to observe when developing new systems. It includes discussion of OBIEE 12c and with additional emphasis on analysis of Usage Tracking data for the accurate profiling and diagnosis of issues. Why this would appeal to the audience: – Method-R time profiling technique applied to the OBIEE nqquery.log – Large number of the community use OBIEE, many will have their own performance horror stories; fewer will have done a deep dive into analysing the time profile of long-running requests – Performance “right practices” will help those less familiar with performant OBIEE designs, and may prompt debate from those more experienced. As presented previously at OOW, OUGF, UKOUG, OUG Scotland, and POUG. Newly updated for OBIEE 12c. * Video: http://ritt.md/silver-bullets-video* Slides: http://ritt.md/silver-bullets-slides
What’s new in Training in 2017?
2016 - Thank you for a great year!
Rittman Mead would like to thank everyone that attended or showed an interest in our Training courses in 2016. Since we started back in 2007, Training has been a mainstay of our service offerings.
My personal opinion is that Q3 & Q4 saw the emergence of OBIEE 12c being properly adopted within the marketplace. It made sense for companies to wait for some of the bugs from earlier releases to be ironed out as well as waiting for clarity around the release of things such as Data Visualization Desktop.
It meant that we started to really see numbers pick up in our OBIEE 12c bootcamp. For the first time we’ve really tried to stress the fact that different parts of the course can be suitable for different people based on their everyday use of the product. This has led to more business focused end-users of OBIEE attending our training.
We love travelling and 2016 yet again took us to some amazing places to deliver courses to a variety of different clients. Locations we visited included South Africa, India, Sweden, Jamaica, Bulgaria and Ireland to name a few.
Finally we were really proud to release our new On Demand Training platform in December 2016 with our first online course, OBIEE 12c Front End Development & Data Visualization.

What’s new in 2017
We’re looking forward to another busy year in 2017 and it’s certainly already underway!!
Our public training schedule has been published with a number of courses available in OBIEE & ODI.
Here you can find the course dates for UK & Europe
And here you can find the courses available in the US
2017 will also see the release of some new courses including:
Advanced Analytics and Oracle R
We are seeing more and more investment in Predictive Analytics projects from companies looking to make as much value out of their data as possible.
Our 3 day course will teach you about the tools available & the techniques required to start or continue your Predictive Analytics journey.
From acquiring to tidying and transforming data, moving into the types of Predictive Models and how to the deploy them, our course will strengthen your knowledge and teach you valuable techniques.
The Advanced Analytics & Oracle R course will be available from March 2017, please get in touch for more details.
2017 will also see the refresh of our ODI 12c Bootcamp. There are some very handy new features in the latest version such as the Big Data Integration and also Lifecycle Management. We'll also be including some lessons on advanced techniques such as Groovy Scripting in ODI.
We’re looking forward to teaching these extra modules soon.
The new course will be released in Q2 2017.
On Demand Training
We will be adding more courses to our On Demand Training platform throughout 2017. We recognise the value of classroom instructor led training however we also understand that people have busy lives and that sometimes flexibility to learn at your own pace is important.
Our On Demand Training platform provides this opportunity whether you’re trying to reaffirm your learning post-classroom training or looking to learn a new skill for the first time.
Courses that will be added online in 2017 include OBIEE 12c RPD Modeling, OBIEE 12c Systems Management & Performance, OBIEE 11g Front End Development, ODI 12c Bootcamp, ODI 11g for BI Apps and many more….
For more information and updates, please head to our webpage

