Author Archives: Rittmanmead
First Steps with Oracle Analytics Cloud
Preface
Not long ago Oracle added a new offer to their Cloud - an OBIEE in a Cloud with full access. Francesco Tisiot made an overview of it and now it's time to go a bit deeper and see how you can poke it with a sharp stick by yourself. In this blog, I'll show how to get your own OAC instance as fast and easy as possible.
Before you start
The very first step is to register a cloud account. Oracle gives a trial which allows testing of all features. I won't show it here as it is more or less a standard registration process. I just want highlight a few things:
- You will need to verify your phone number by receiving an SMS. It seems that this mechanism may be a bit overloaded and I had to make more than one attempts. I press the Request code button but nothing happens. I wait and press it again, and again. And eventually, I got the code. I can't say for sure and possible it was just my bad luck but if you face the same problem just keep pushing (but not too much, requesting a code every second won't help you).
- Even for trial you'll be asked for a credit card details. I haven't found a good diagnostics on how much was already spent and the documentation is not really helpful here.
Architecture
OAC instances are not self-containing and require some additional services. The absolute minimum configuration is the following:
- Oracle Cloud Storage (OCS) - is used for backups, log files, etc.
- Oracle Cloud Database Instance (DBC) - is used for RCU schemas.
- Oracle Analytics Cloud Instance (OAC) - is our ultimate target.
From the Cloud services point of view, architecture is the following. This picture doesn't show virtual disks mounted to instances. These disks consume Cloud Storage quota but they aren't created separately as services.
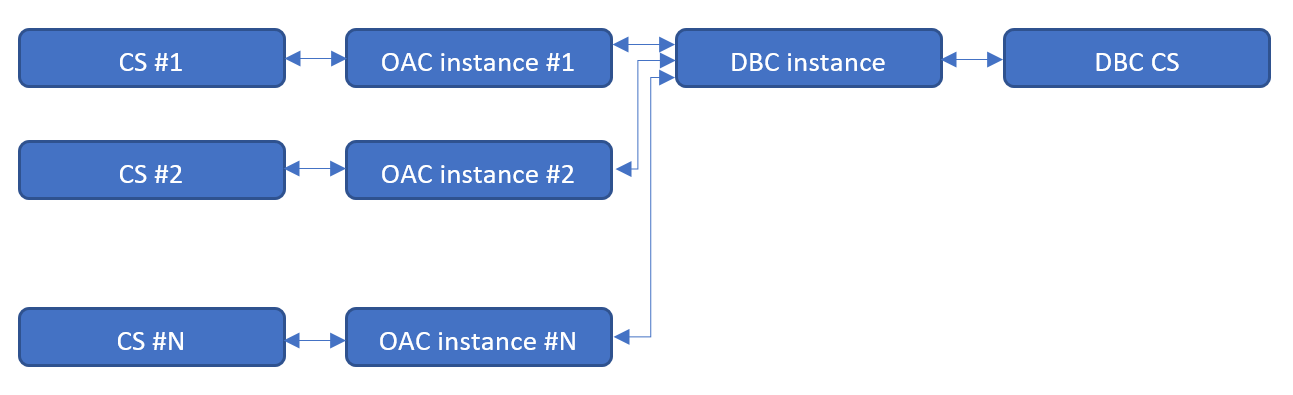
We need at least one Oracle Database Cloud instance to store RCU schemas. This database may or may not have a separate Cloud Storage area for backups. Every OAC instance requires Cloud storage area for logs. Multiple OAC instances may share one Cloud storage area but I can't find any advantage of this approach over a separate area for every instance.
Create Resources
We create these resource in the order they are listed earlier. Start with Storage, then DB and the last one is OAC. Actually, we don't have to create Cloud Storage containers separately as they may be created automatically. But I show it here to make things more clear without too much "it works by itself" magic.
Create Cloud Storage
The easiest part of all is the Oracle Cloud Storage container. We don't need to specify its size or lots of parameters. All parameters are just a name, storage class (Standard/Archive) and encryption.
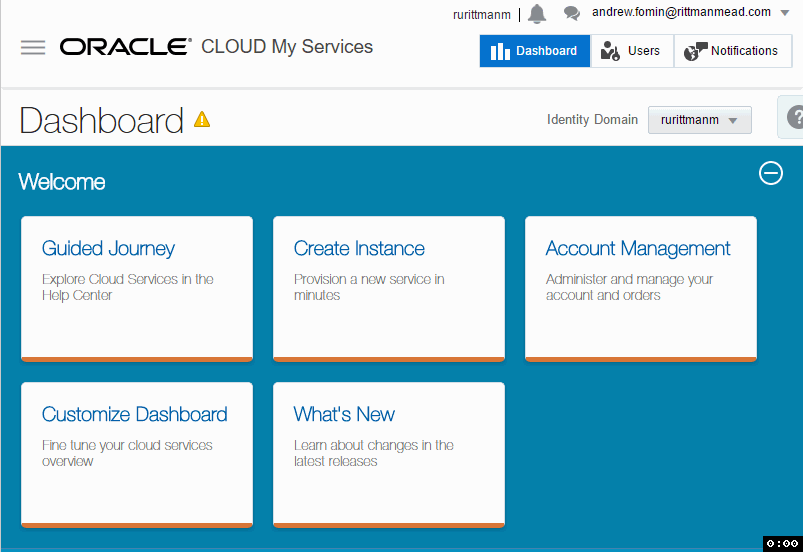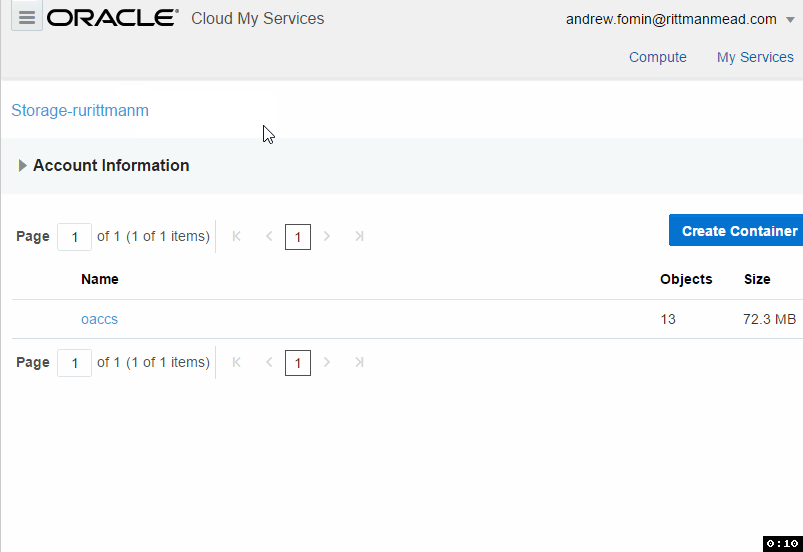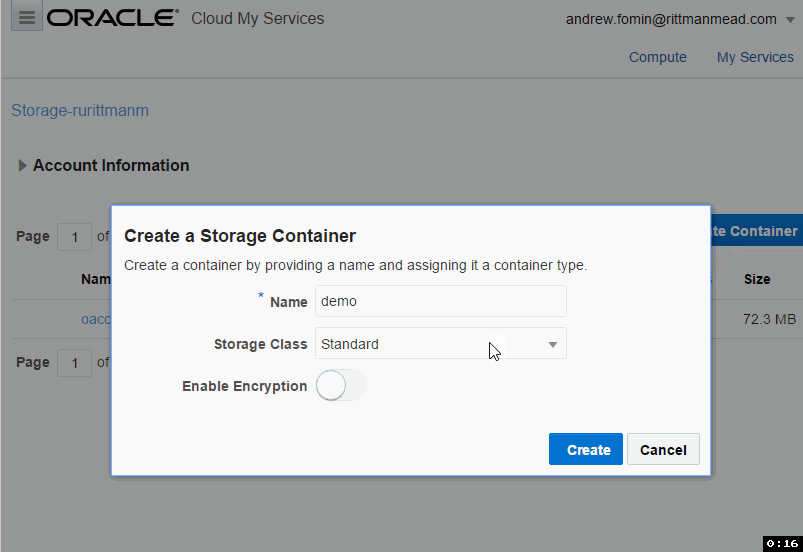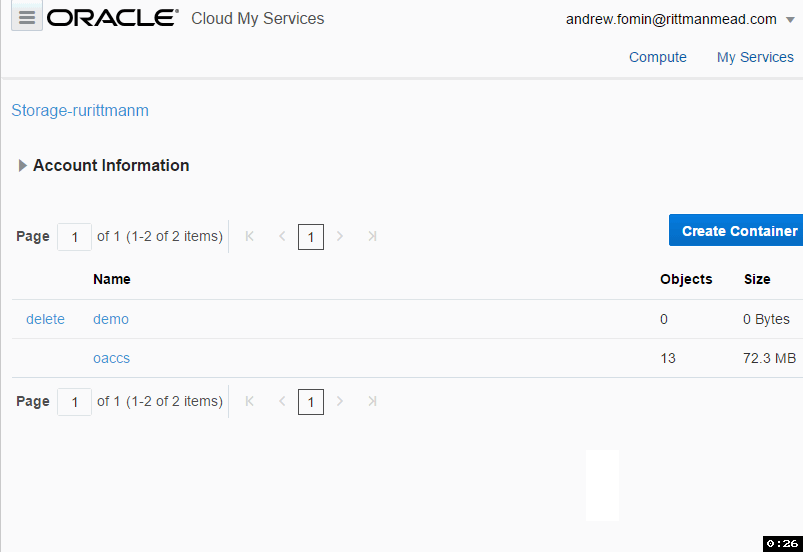
I spent some time here trying to figure out how to reference this storage later. There is a hint saying that "Use the format: <storage service>-<identity domain>/<container>. For example: mystorage1-myid999/mybackupcontainer." And if identity domain and container are pretty obvious, storage service puzzled me for some time. The answer is "storage service=Storage". You can see this in the top of the page.
It seems that Storage is a fixed keyword, rurittmanm is the domain name created during the registration process and demo is the actual container name. So in this sample when I need to reference my demo OCS I should write Storage-rurittmanm/demo.
Create Cloud DB
Now when we are somewhat experienced in Oracle Cloud we may move to a more complicated task and create a Cloud DB Instance. It is harder than Cloud Storage container but not too much. If you ever created an on-premise database service using DBCA, cloud DB should be a piece of cake to you.
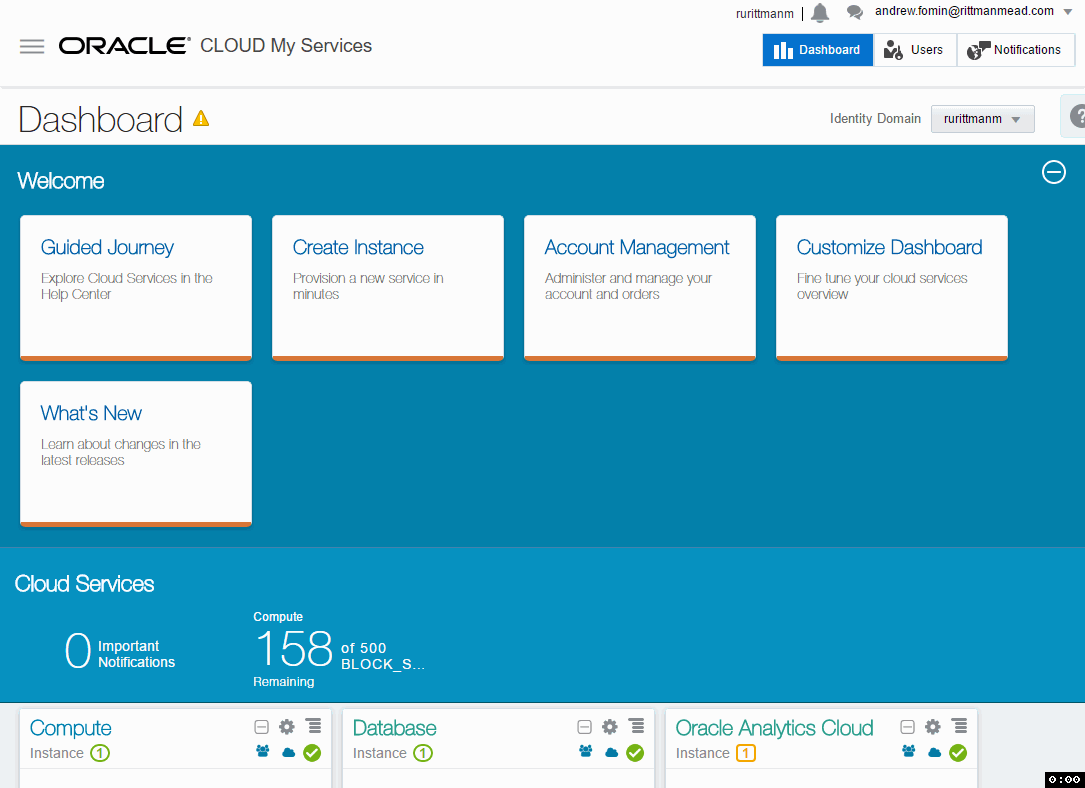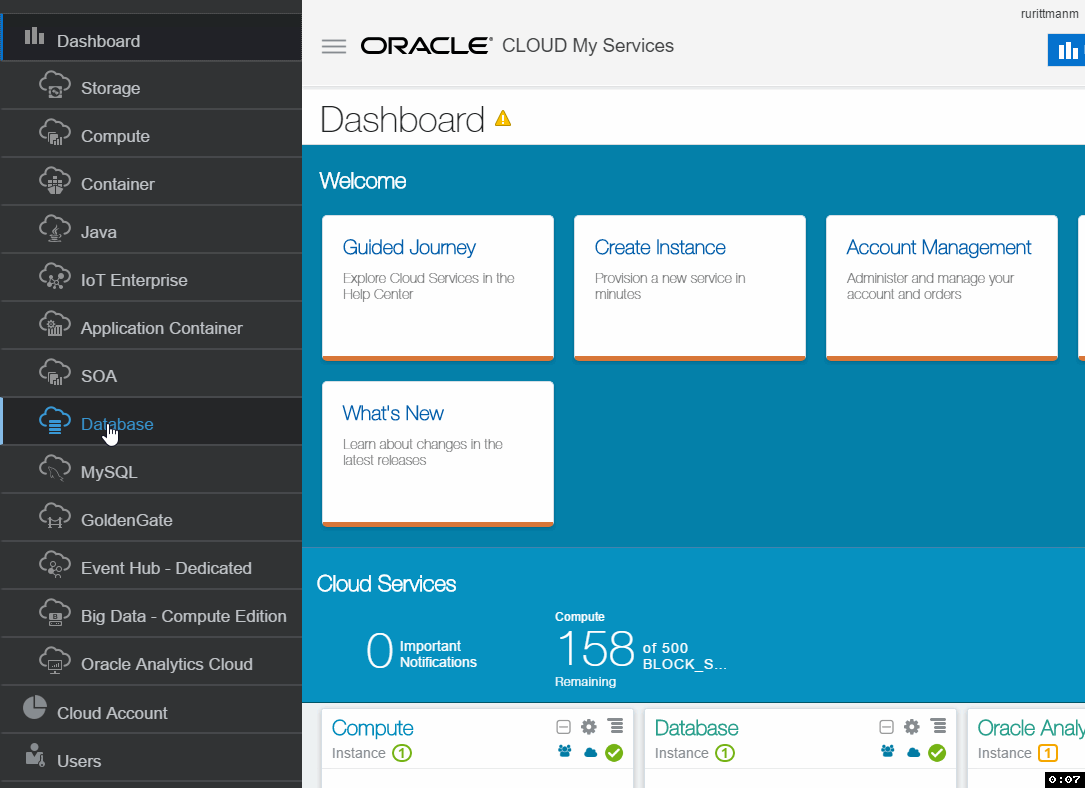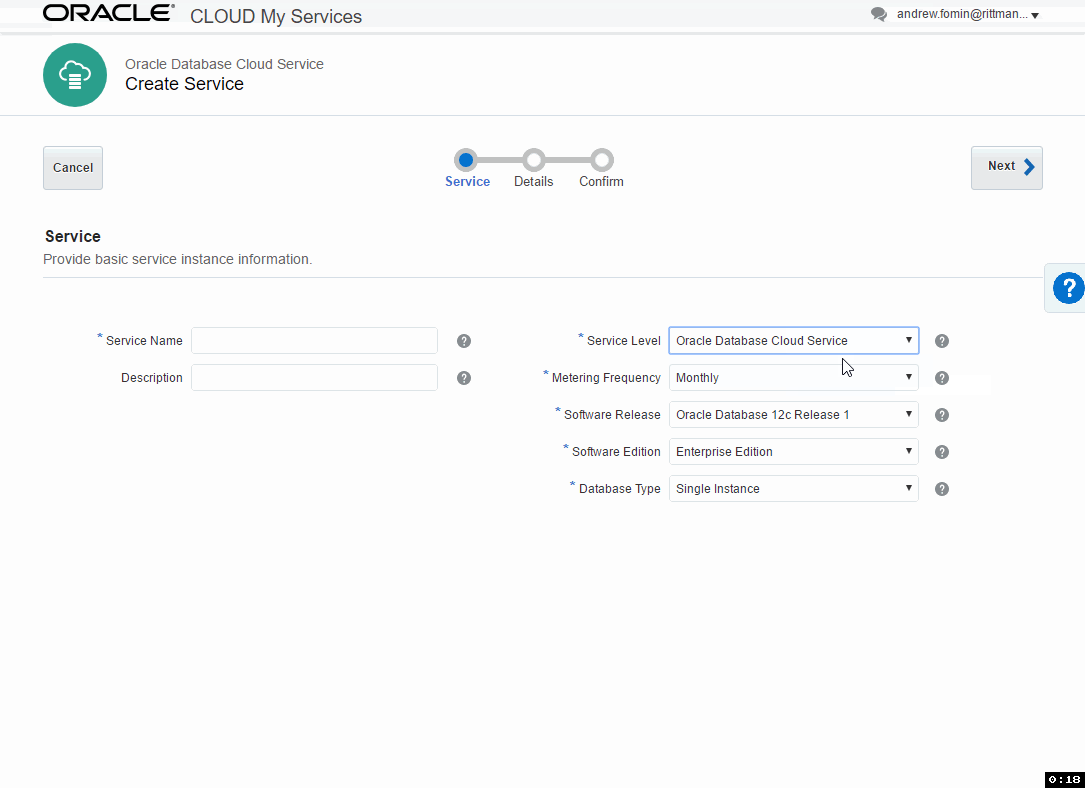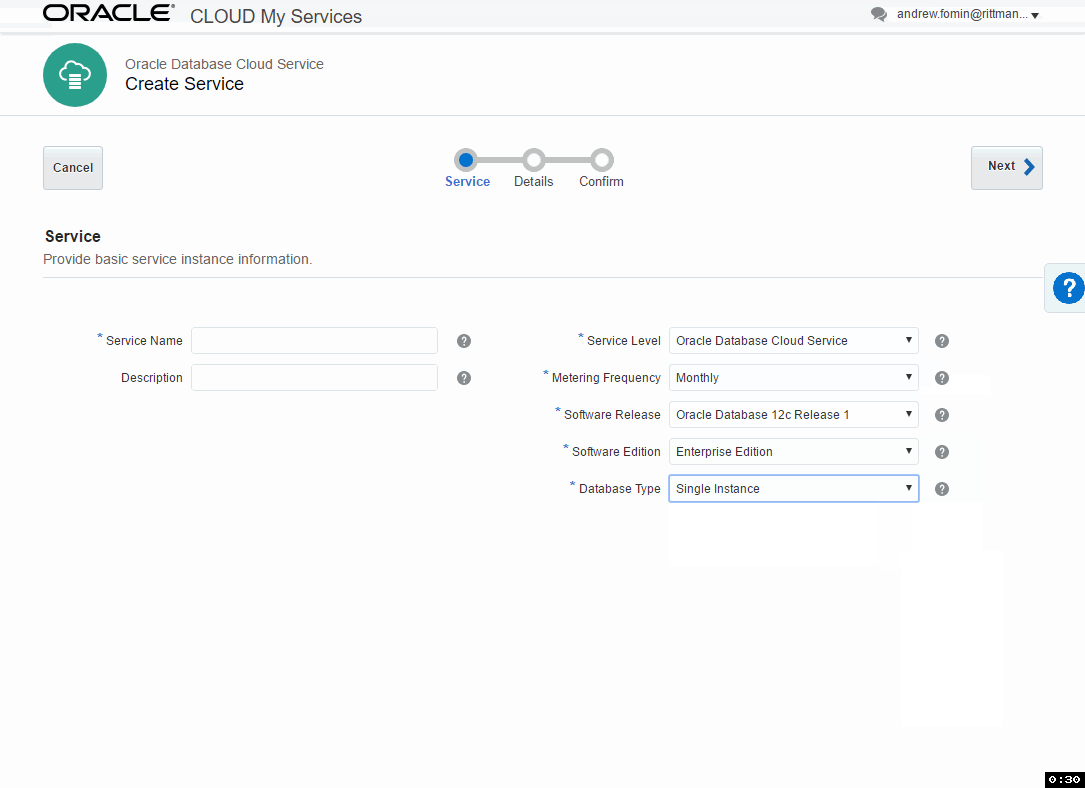
At the first step, we set the name of the instance and select the most general options. These options are:
Service Level. Specifies how this instance will be managed. Options are:
- Oracle Database Cloud Service: Oracle Database software pre-installed on Oracle Cloud Virtual Machine. Database instances are created for you using configuration options provided in this wizard. Additional cloud tooling is available for backup, recovery and patching.
- Oracle Database Cloud Service - Virtual Image: Oracle Database software pre-installed on an Oracle Cloud Virtual Machine. Database instances are created by you manually or using DBCA. No additional cloud tooling is available.
Metering Frequency - defines how this instance will be paid: by months or by hours.
Software Release - if the Service Level is Oracle Database Cloud Service, we may choose 11.2, 12.1 and 12.2, for Virtual Image only 11.2 and 12.1 are available. Note that even cloud does no magic and with DB 12.2 you may expect the same problems as on-premise.
Software Edition - Values are:
- Standard Edition
- Enterprise Edition
- Enterprise Edition - High Performance
- Enterprise Edition - Extreme Performance
Database Type - defines High Availability and Disaster Recovery options:
- Single Instance
- Database Clustering with RAC
- Single Instance with Data Guard Standby
- Database Clustering with RAC and Data Gard Standby
Database Clustering with RAC and Database Clustering with RAC and Data Gard Standby types are available only for Enterprise Edition - Extreme Performance edition.
The second step is also quite intuitive. It has a lot of options but they should be pretty simple and well-known for anyone working with Oracle Database.
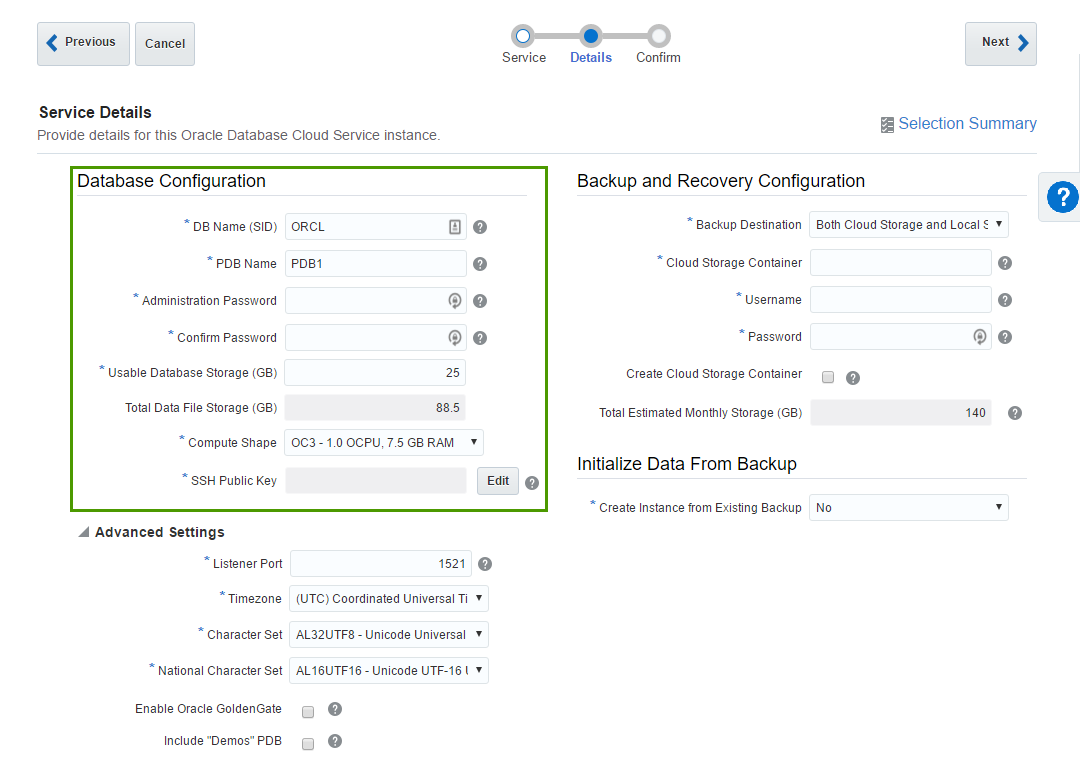
The first block of parameters is about basic database configuration. Parameters like DB name (sid) or Administration Password are obvious.
Usable DataFile Storage (GB) is less obvious. Actually, in the beginning, it puzzled me completely. In this sample, I ask for 25 Gb of space. But this doesn't mean that my instance will take 25 Gb of my disk quota. In fact, this particular instance took 150 Gb of disk space. Here we specify only a guaranteed user disk space, but an instance needs some space for OS, and DB software, and temp, and swap, and so on.
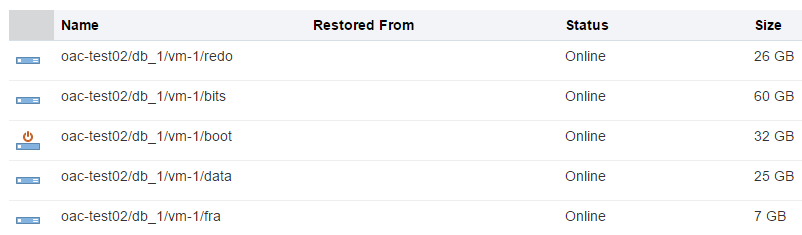
A trial account is limited with 500 Gb quota and that means that we can create only 3 Oracle DB Cloud instances at max. Every instance will use around 125 Gb of let's say "technical" disk space we can't reduce. From the practical point of view, it means that it may be preferable to have one "big" instance (in terms of the disk space) rather than multiple "small".
- Compute shape specifies how powerful our VM should be. Options are the following:
- OC3 - 1.0 OCPU, 7.5 GB RAM
- OC4 - 2.0 OCPU, 15.0 GB RAM
- OC5 - 4.0 OCPU, 30.0 GB RAM
- OC6 - 8.0 OCPU, 60.0 GB RAM
- OC7 - 16.0 OCPU, 120.0 GB RAM
- OC1m - 1.0 OCPU, 15.0 GB RAM
- OC2m - 2.0 OCPU, 30.0 GB RAM
- OC3m - 4.0 OCPU, 60.0 GB RAM
- OC4m - 8.0 OCPU, 120.0 GB RAM
- OC5m - 16.0 OCPU, 240.0 GB RAM
We may increase or decrease this value later.
- SSH Public Key - Oracle gives us an ability to connect directly to the instance and authentication is made by
user+private keypair. Here we specify a public key which will be added to the instance. Obviously, we should have a private key for this public one. Possible options are either we provide a key we generated by ourselves or let Oracle create keys for us. The most non-obvious thing here is what is the username for the SSH. You can't change it and it isn't shown anywhere in the interface (at least I haven't found it). But you can find it in the documentation and it isopc.
The second block of parameters is about backup and restore. The meaning of these options is obvious, but exact values aren't (at least in the beginning).
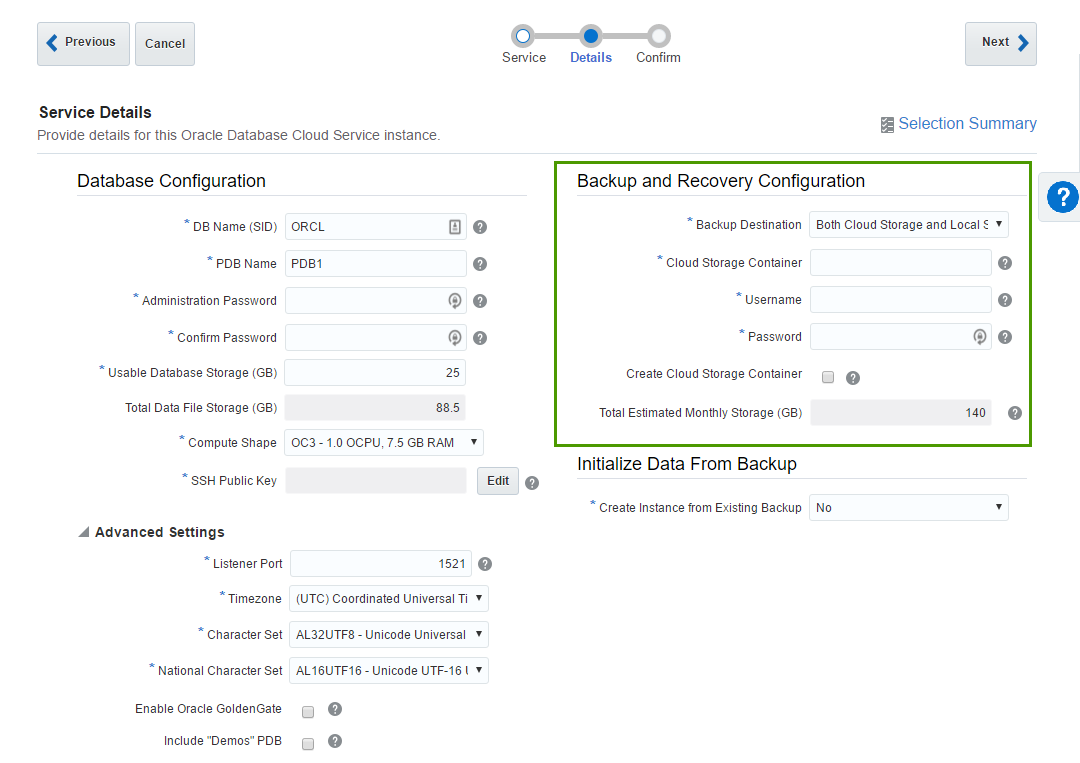
Cloud Storage Container - that's the Cloud Storage container I described earlier. Value for this field will be something like
Storage-rurittmanm/demo. In fact, I may do not create this Container in advance. It's possible to specify any inexistent container here (but still in the form ofStorage-<domain>/<name>) and tickCreate Cloud Storage Containercheck-box. This will create a new container for us.Username and Password are credentials of a user who can access this container.
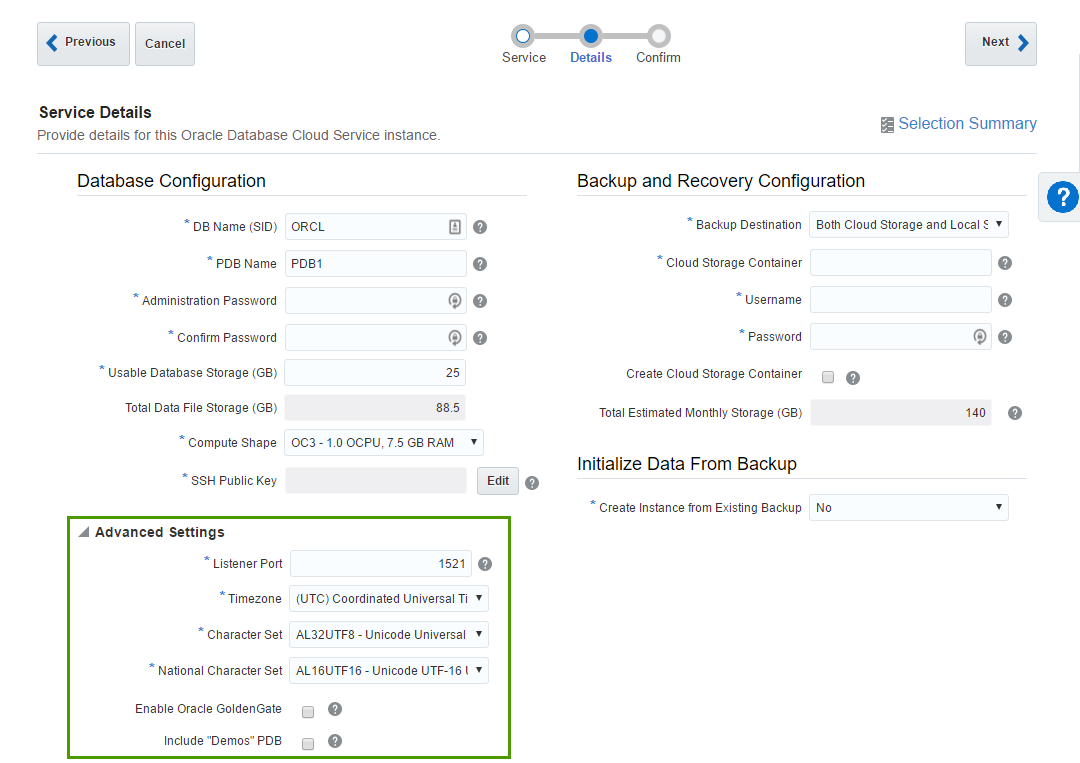
The last block is Advanced settings and I believe it's quite simple and obvious. Most of the time we don't need to change anything in this block.
When we fill all parameters and press the Next button we get a Summary screen and the actual process starts. It takes about 25-30 minutes to finish.
When I just started my experiments I was constantly getting a message saying that no sites available and my request may not be completed.

It is possible that it was again the same "luck" as with the phone number verification but the problem solved by itself a few hours later.
Create OAC Instance
At last, we have all we need for our very first OAC instance. The process of an OAC instance setup is almost the same as for an Oracle DB Cloud Instance. We start the process, define some parameters and wait for the result.
At the first step, we give a name to our instance, provide an SSH public key, and select an edition of our instance. We have two options here Enterprise Edition or Standard Edition and later we will select more additional options. Standard edition will allow us to specify either Data Visualisation or Essbase instances and Enterprise Edition adds to this list a classical Business Intelligence feature. The rest of the parameters here are exactly the same as for Database Instance.
At the second step, we have four blocks of parameters.
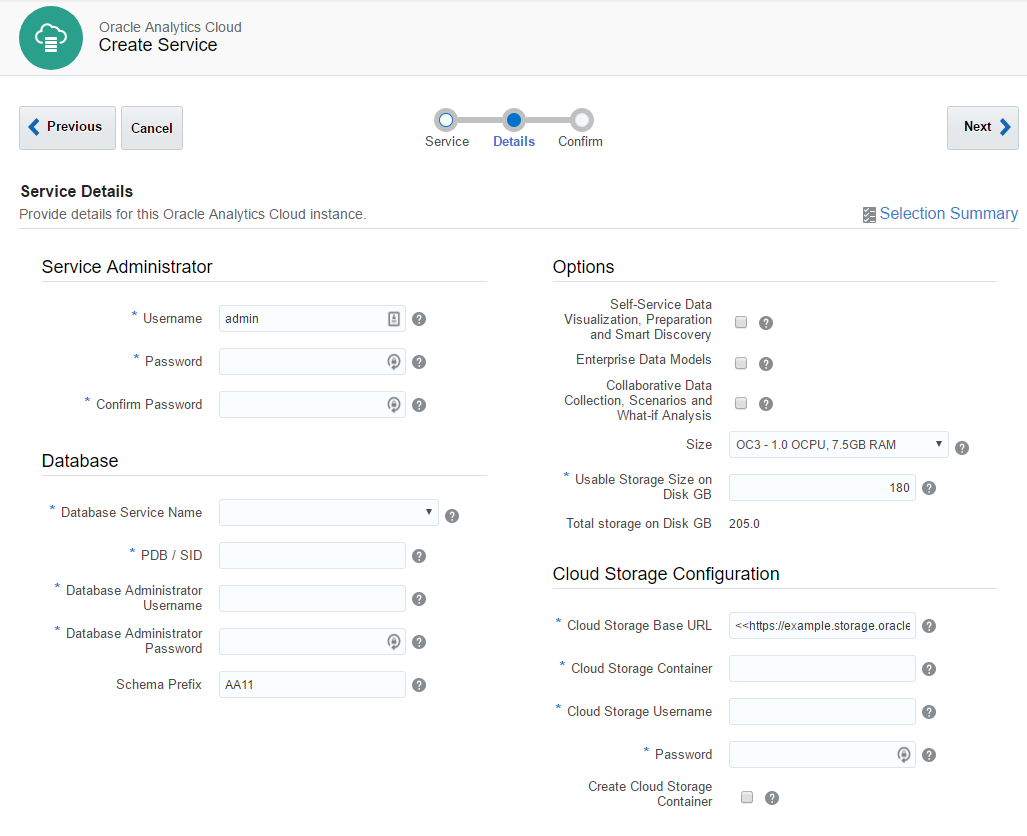
Service Administrator - the most obvious one. Here we specify an administrator user. This user will be a system administrator.
Database - select a database for RCU schemas. That's why we needed a database.
Options - specify which options our instance will have.
- Self-Service Data Visualisation, Preparation and Smart Discovery - this option means Oracle Data Visualisation and it is available for both Standard and Enterprise Editions.
- Enterprise Data Models - this option gives us classical BI and available only for Enterprise Edition. Also, this option may be combined with the first one giving us both classical BI and modern Data discovery on one instance.
- Collaborative Data Collection, Scenarios and What-if Analysis - this one stands for Essbase and available for Standard and Enterprise Editions. It can't be combined with other options.
- Size is the same thing that is called Compute Shape for the Database. Options are exactly the same.
- Usable Storage Size on Disk GB also has the same meaning as for the DB. The minimum size we may specify here is 25 Gb what gives us total 170 Gb of used disk space.
Here is a picture showing all possible combinations of services:

And here virtual disks configuration. data disk is the one we specify.
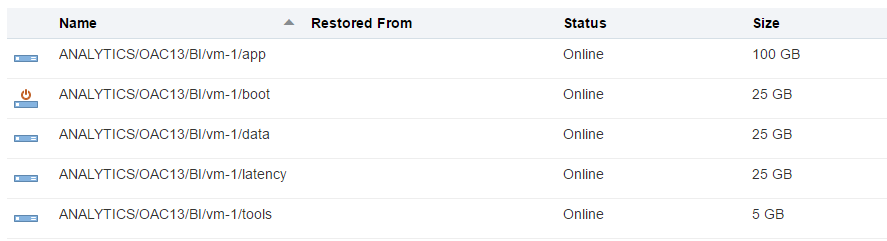
The last block - Cloud Storage Configuration was the hardest one. Especially the first field - Cloud Storage Base URL. The documentation says "Use the format: https://example.storage.oraclecloud.com/v1" and nothing more. When you know the answer it may be easy, but when I saw it for the first time it was hard. Should I place here any unique URL just like an identifier? Should it end with v1? And what is the value for the second instance? V2? Maybe I should place here the URL of my current datacenter (https://dbcs.emea.oraclecloud.com). The answer is https://<domain>.storage.oraclecloud.com/v1 in my case it is https://rurittmanm.storage.oraclecloud.com/v1. It stays the same for all instances.
All other parameters are the same as they were for DBCS instance. We either specify an existing Cloud Storage container or create it here.
The rest of the process is obvious. We get a Summary and then wait. It takes about 40 minutes to create a new instance.
Note: diagnostics here is a bit poor and when it says that the instance start process is completed it may not be true. Sometimes it makes sense to wait some time before starting to panic.
Now we may access our instance as a usual. The only difference is that the port is 80 not 9502 (or 443 for SSL). For Data Visualisation the link is http(s)://<ip address>/va, for BIEE - http(s)://<ip address>/analytics and for Essbase http(s)://<ip address>/essbase. Enterprise Manager and Weblogic Server Console are availabale at port 7001 which is blocked by default.
What is bad that https uses a self-signed certificate. Depending on browser settings it may give an error or even prevent access to https.
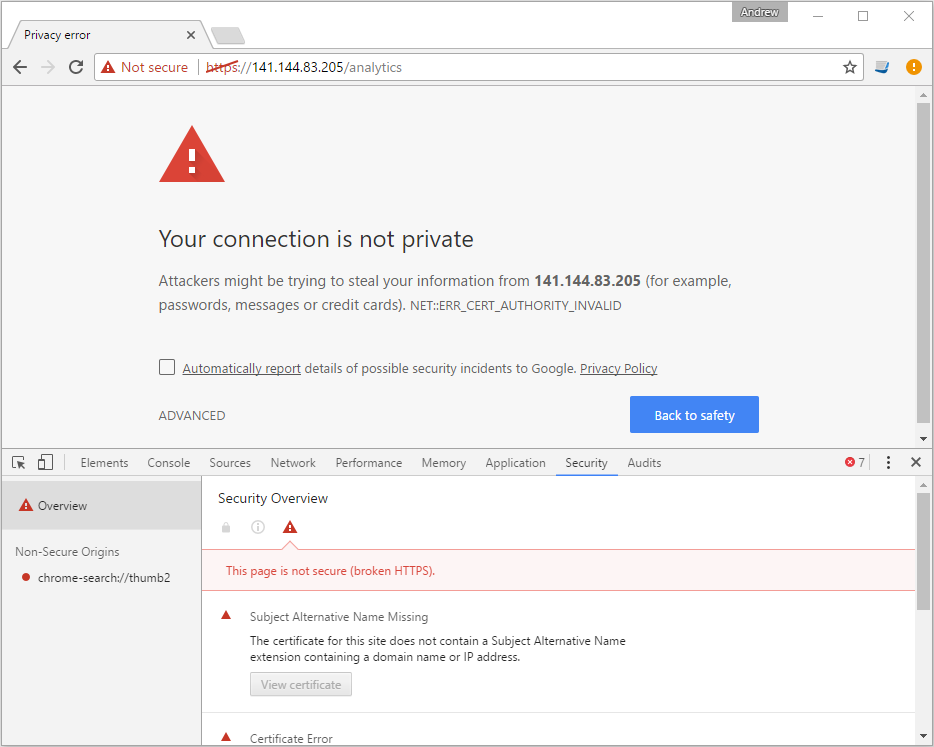
Options here either use HTTP rather than HTTPS or add this certificate to your local computer. But these aren't the options for a production server. Luckily Oracle provides a way to use own SSL certificates.
Typical Management Tasks
SSH to Instances
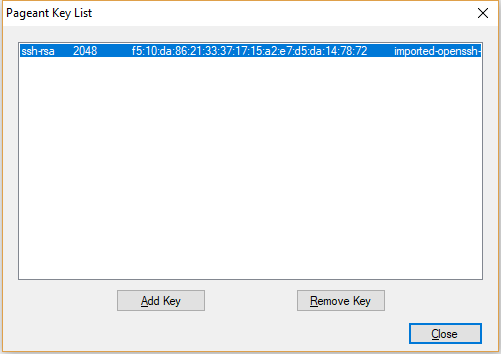
During the setup process, we provide Oracle with a public key which is used to get an SSH access to instances. Cloud does nothing special to this. In the case of Windows, we may use Putty. Just add the private key to Pageant and connect to the instance using user opc.
Opening Ports
By default only the absolute minimum of the ports is open and we can't connect to the OAC instance using BI Admin tool or to the DB with SQLDeveloper. In order to do this, we should create an access rule which allows access to this particular ports.
In order to get to the Access Rules interface, we must use instance menu and select the Access Rules option.
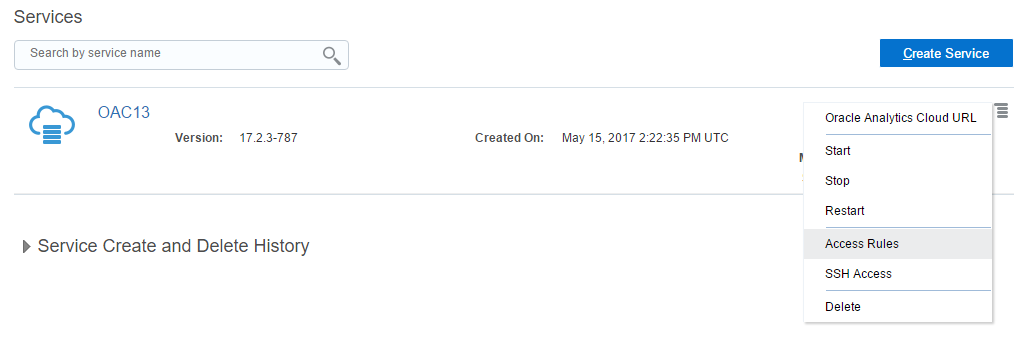
This will open the Access Rules list. What I don't like about it is that it opens the full list of all rules but we can create only a rule for this particular instance.
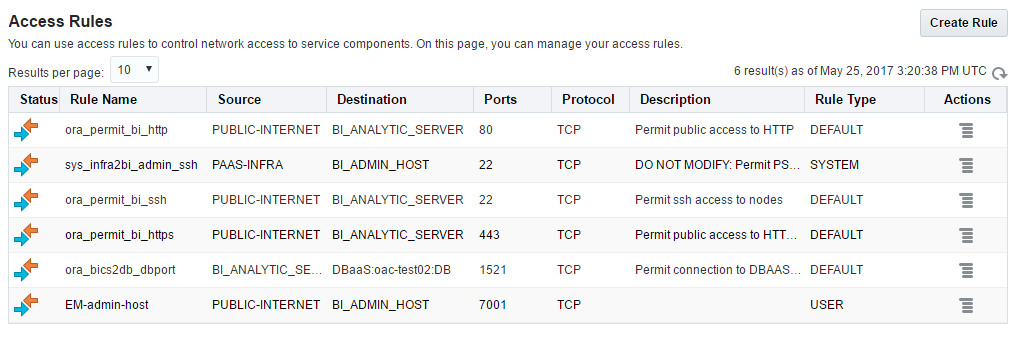
New rule creation form is simple and should cause no issues. But be careful here and not open too much for a wild Internet.
Add More Users
The user who registered a Cloud Account becomes its administrator and can invite more users and manage privileges.

Here we can add and modify users.
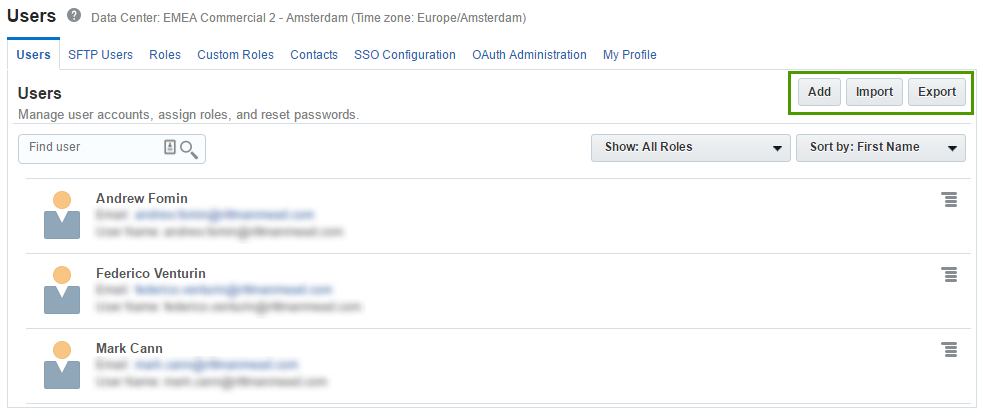
When we add a user we specify a name, email and login. Also here we set roles for the user. The user will get an email with these details, and link to register.
Obviously, the user won't be asked about a credit card. He just starts working and that's all.
Summary
My first steps with Oracle Analytics Cloud were not very easy, but I think it was worth it. Now I can create a new OBIEE instance just in a few minutes and one hour later it will be up and running. And I think that's pretty fast compared to a normal process of creating a new server in a typical organisation. We don't need to think about OS installation, or licenses, or whatever else. Just try it.
OBIEE upgrades and Windows vulnerabilities


These two topics may seem unrelated; however, the ransomware attacks over the last few days provide us with a reminder of what people can do with known vulnerabilities in an operating system.
Organisations consider upgrades a necessary evil; they cost money, take up time and often have little tangible benefit or return on investment (ROI). In the case of upgrades between major version of software, for example, moving from OBIEE 10g to 12c there are significant architecture, security, functional and user interface changes that may justify the upgrade alone, but they are unlikely to significantly change the way an organisation operates and may introduce new components and management processes which produce an additional overhead.
There is another reason to perform upgrades: to keep your operating systems compliant with corporate security standards. OBIEE, and most other enterprise software products, come with certification matrices that detail the supported operating system for each product. The older the version of OBIEE, the older the supported operating systems are, and this is where the problem starts.
If we take an example of an organisation running OBIEE 10g, the most recent certified version of Windows it can run is Windows 2008 R2, which will fall outside of your company's security policy. You will be less likely to be patching the operating system on the server as it will either have fallen off the radar or Microsoft may have stopped releasing patches for that version of the operating system.
The result leaves a system that has access to critical enterprise data vulnerable to known attacks.
The only answer is to upgrade, but how do we justify ROI and obtain budget? I think we need to recognise that there is a cost of ownership associated with maintaining systems, the benefit of which is the mitigation of the risk of an instance like the ransomware attacks. It is highly unlikely that anyone could have predicted those attacks, so you could never have used it as a reason to justify an upgrade. However, these things do happen, and a significant amount of cyber attacks probably go on undetected. The best protection you have is to make sure your systems are up to date.
A focus on Higher Education, HEDW 2017
First, before I get into a great week of Higher Education Data Warehousing and analytics discussions, I want to thank the HEDW board and their membership. They embraced us with open arms in our first year of conference sponsorship. Our longtime friend and HEDW board member, Phyllis Wykoff, from Miami University of Ohio even spent some time with us behind the booth!
 HEDW was in the lovely desert scape of Tucson, AZ at the University of Arizona. Sunday was a fantastic day of training, followed by three days of outstanding presentations from member institutions and sponsors. Rittman Mead wanted to show how important the higher education community is to us, so along with me, we had our CEO-Jon Mead, our CTO-Jordan Meyer, and our US Managing Director-Charles Elliott. If our AirBnB had ears, it would have heard several solutions to the problems of the world as well as discussions of the fleeting athleticism of days gone past. But alas, that will have to wait.
HEDW was in the lovely desert scape of Tucson, AZ at the University of Arizona. Sunday was a fantastic day of training, followed by three days of outstanding presentations from member institutions and sponsors. Rittman Mead wanted to show how important the higher education community is to us, so along with me, we had our CEO-Jon Mead, our CTO-Jordan Meyer, and our US Managing Director-Charles Elliott. If our AirBnB had ears, it would have heard several solutions to the problems of the world as well as discussions of the fleeting athleticism of days gone past. But alas, that will have to wait.
While at the conference, we had a multitude of great conversations with member institutions and there were a few themes that stuck out to us with regard to common issues and questions from our higher education friends. I will talk a little bit about each one below with some context on how Rittman Mead is the right fit to be partners in addressing some big questions out there.
Legacy Investment vs BI tool Diversification (or both)
One theme that was evident from hour one was the influx of Tableau in the higher education community. Rittman Mead is known for being the leader in the Oracle Business Intelligence thought and consulting space and we very much love the OBIEE community. With that said, we have, like all BI practitioners, seen the rapid rise of Tableau within departments and lately as an enterprise solution. It would be silly for the OBIEE community to close their eyes and pretend that it isn’t happening. There are great capabilities coming out of Oracle with Data Visualization but the fact is, people have been buying Tableau for a few years and Tableau footprints exist within organizations. This is a challenge that isn't going away.
Analytics Modernization Approaches
We had a ton of conversations about how to include newer technologies in institutions’ business intelligence and data warehousing footprints. There is clearly a desire to see how big data technologies like Hadoop, data science topics like the R statistical modeling language, and messaging services like Kafka could positively impact higher education organizations. Understanding how you may eliminate batch loads, predict student success, know if potential financial aid is not being used, know more about your students with analysis of student transactions with machine learning, and store more data with distributed architectures like Hadoop are all situations that are readily solvable. Rittman Mead can help you prioritize what will make the biggest value impact with a Modernization Assessment. We work with organizations to make good plans for implementation of modern technology at the right place and at the right time. If you want more info, please let us know.
Sometimes we need a little help from our friends
Members of HEDW need a different view or another set of eyes sometimes and the feedback we heard is that consulting services like ours can seem out of reach with budgets tighter than ever. That is why we recently announced the Rittman Mead Expert Service Desk. Each month, there are hours available to spend however you would like with Rittman Mead’s experts. Do you have a mini project that never seems to get done? Do you need help with a value proposition for a project or upgrade? Did production just go down and you can’t seem to figure it out? With Expert Service desk, you have the full Rittman Mead support model at your fingertips. Let us know if you might want a little help from your friends at Rittman Mead.
To wrap up
Things are a changing and sometimes it is tough to keep up with all of the moving parts. Rittman Mead is proud to be a champion of sharing new approaches and technologies to our communities. Spending time this week with our higher education friends is proof more that our time spent sharing is well worth it. There are great possibilities out there and we look forward to sharing them throughout the year and at HEDW 2018 in Oregon!
The Case for ETL in the Cloud – CAPEX vs OPEX
Recently Oracle announced a new cloud service for Oracle Data Integrator. Because I was helping our sales team by doing some estimates and statements of work, I was already thinking of costs, ROI, use cases, and the questions behind making a decision to move to the cloud. I want to explore what is the business case for using or switching to ODICS?
Oracle Data Integration Cloud Services
First, let me briefly talk about what is Oracle Data Integration Cloud Services? ODICS is ODI version 12.2.1.2 available on Oracle’s Java Cloud Service known as JCS. Several posts cover the implementation, migration, and technical aspects of using ODI in the cloud. Instead of covering the ‘how’, I want to talk about the ‘when’ and ‘why’.
Use Cases
What use cases are there for ODICS?
1. You have or soon plan to have your data warehouse in Oracle’s Cloud. In this situation, you can now have your ODI J2EE agent in the same cloud network, removing network hops and improving performance.
2. If you currently have an ODI license on-premises, you are allowed to install that license on Oracle’s JCS at the JCS prices. See here for more information about installing on JCS. These use cases are described in a webinar posted in the PM Webcast Archive.
When and Why?
So when would it make sense to move towards using ODICS? These are the scenarios I imagine being the most likely:
1. A new customer or project. If a business doesn’t already have ODI, this allows them to decide between an all on-premises solution or a complete solution in Oracle’s cloud. With monthly and metered costs, the standard large start-up costs for hardware and licenses are avoided, making this solution available for more small to medium businesses.
2. An existing business with ODI already and considering moving their DW to the cloud. In this scenario, a possible solution would be to move the current license of ODI to JCS and begin using that to move data, all while tracking JCS costs. When the time comes to review licensing obligations for ODI, compare the calculation for a license to the calculation of expected usage for ODICS and see which one makes the most sense (cents?). For a more detailed explanation of this point, let’s talk CAPEX and OPEX!
CAPEX vs. OPEX
CAPEX and OPEX are short for Capital Expense and Operational Expense, respectively. In a finance and budgeting perspective, these two show up very differently on financial reports. This often has tax considerations for businesses. Traditionally in the past, a data warehouse project was a very large initial capital expenditure, with hardware, licenses, and project costs. This would land it very solidly as CAPEX. Over the last several years, sponsorship for these projects has shifted from CIOs and IT Directors to CFOs and Business Directors. With this shift, several businesses would rather budget and see these expenses monthly as an operating expense as opposed to every few years having large capital expenses, putting these projects into OPEX instead.
Conclusion
Having monthly and metered service costs in the cloud that are fixed or predictable are appealing. As a bonus, this style of service is highly flexible and can scale up (or down) as demand changes. If you are or will soon be in the process of planning for your future business analytics needs, we provide expert services, assessments, accelerators, and executive consultations for assisting with these kinds of decisions. When it is time to talk about actual numbers, your Oracle Sales Representative will have the best prices. Please get in touch for more information.
SQL-on-Hadoop: Impala vs Drill
I recently wrote a blog post about Oracle's Analytic Views and how those can be used in order to provide a simple SQL interface to end users with data stored in a relational database. In today's post I'm expanding a little bit on my horizons by looking at how to effectively query data in Hadoop using SQL. The SQL-on-Hadoop interface is key for many organizations - it allows querying the Big Data world using existing tools (like OBIEE,Tableau, DVD) and skills (SQL).
Analytic Views, together with Oracle's Big Data SQL provide what we are looking for and have the benefit of unifying the data dictionary and the SQL dialect in use. It should be noted that Oracle Big Data SQL is licensed separately on top of the database and it's available for Exadata machines only.
Nowadays there is a multitude of open-source projects covering the SQL-on-Hadoop problem. In this post I'll look in detail at two of the most relevant: Cloudera Impala and Apache Drill. We'll see details of each technology, define the similarities, and spot the differences. Finally we'll show that Drill is most suited for exploration with tools like Oracle Data Visualization or Tableau while Impala fits in the explanation area with tools like OBIEE.
As we'll see later, both the tools are inspired by Dremel, a paper published by Google in 2010 that defines a scalable, interactive ad-hoc query system for the analysis of read-only nested data that is the base of Google's BigQuery. Dremel defines two aspects of big data analytics:
- A columnar storage format representation for nested data
- A query engine
The first point inspired Apache Parquet, the columnar storage format available in Hadoop. The second point provides the basis for both Impala and Drill.
Cloudera Impala
We started blogging about Impala a while ago, as soon as it was officially supported by OBIEE, testing it for reporting on top of big data Hadoop platforms. However, we never went into the details of the tool, which is the purpose of the current post.
Impala is an open source project inspired by Google's Dremel and one of the massively parallel processing (MPP) SQL engines running natively on Hadoop. And as per Cloudera definition is a tool that:
provides high-performance, low-latency SQL queries on data stored in popular Apache Hadoop file formats.
Two important bits to notice:
- High performance and low latency SQL queries: Impala was created to overcome the slowness of Hive, which relied on MapReduce jobs to execute the queries. Impala uses its own set of daemons running on each of the datanodes saving time by:
- Avoiding the MapReduce job startup latency
- Compiling the query code for optimal performance
- Streaming intermediate results in-memory while MapReduces always writing to disk
- Starting the aggregation as soon as the first fragment starts returning results
- Caching metadata definitions
- Gathering tables and columns statistics
- Data stored in popular Apache Hadoop file formats: Impala uses the Hive metastore database. Databases and tables are shared between both components. The list of supported file formats include Parquet, Avro, simple Text and SequenceFile amongst others. Choosing the right file format and the compression codec can have enormous impact on performance. Impala also supports, since CDH 5.8 / Impala 2.6, Amazon S3 filesystem for both writing and reading operations.
One of the performance improvements is related to "Streaming intermediate results": Impala works in memory as much as possible, writing on disk only if the data size is too big to fit in memory; as we'll see later this is called optimistic and pipelined query execution. This has immediate benefits compared to standard MapReduce jobs, which for reliability reasons always writes intermediate results to disk.
As per this Cloudera blog, the usage of Impala in combination with Parquet data format is able to achieve the performance benefits explained in the Dremel paper.
Impala Query Process
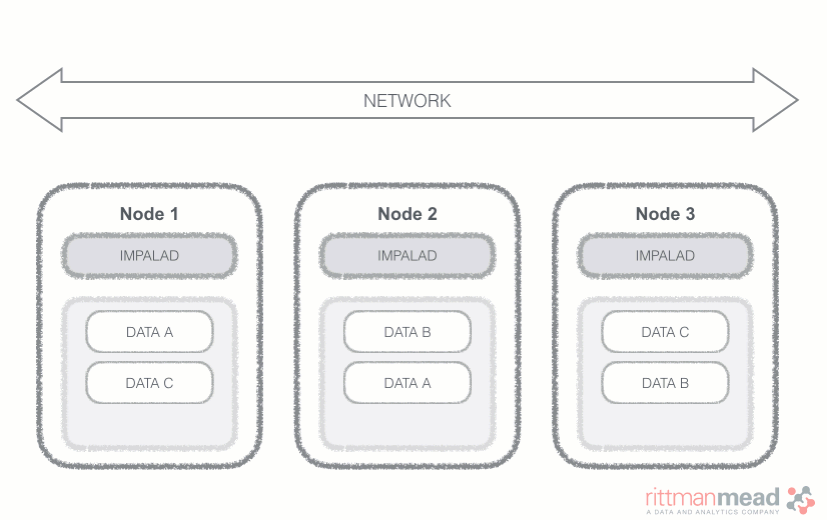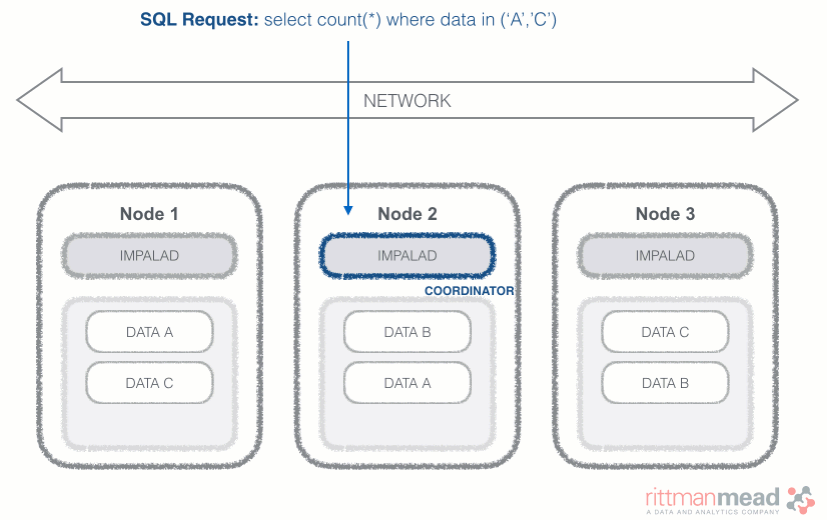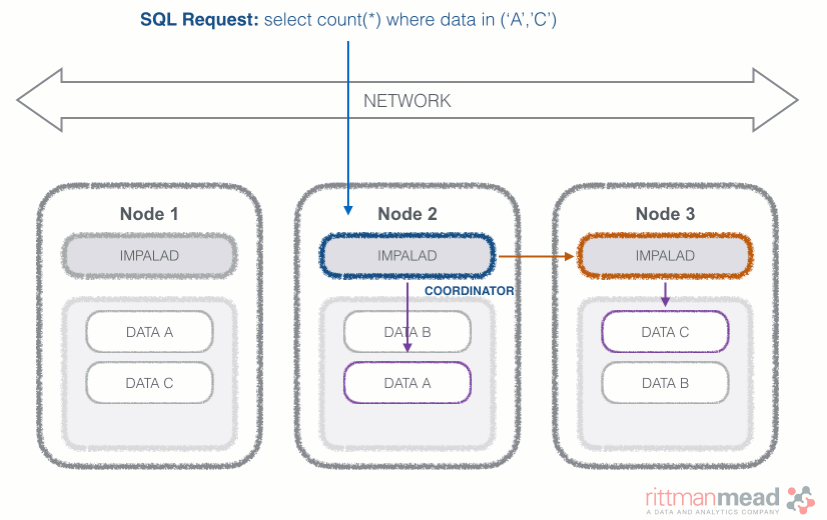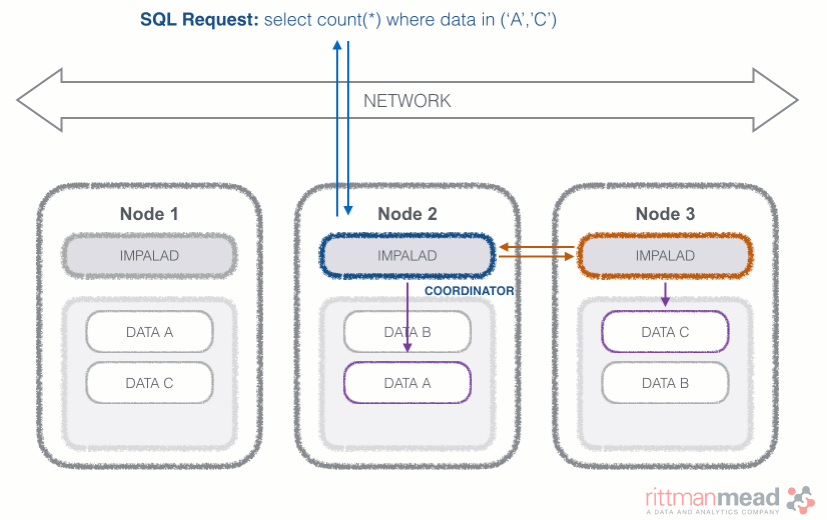
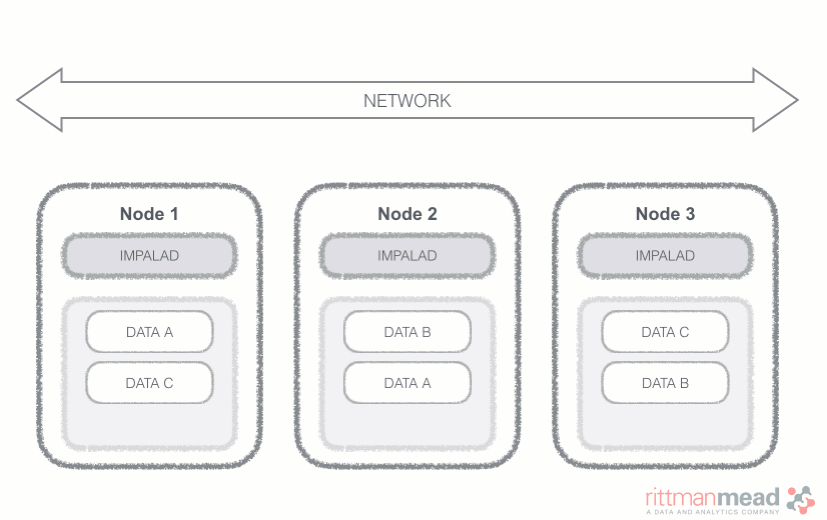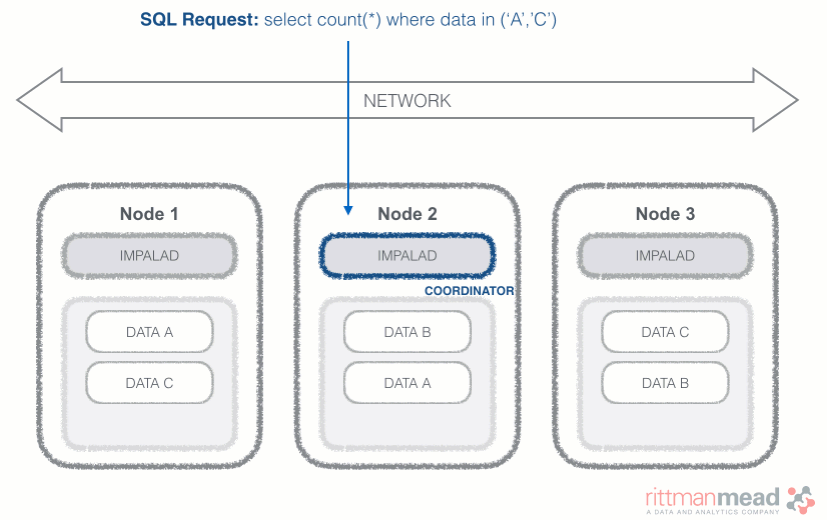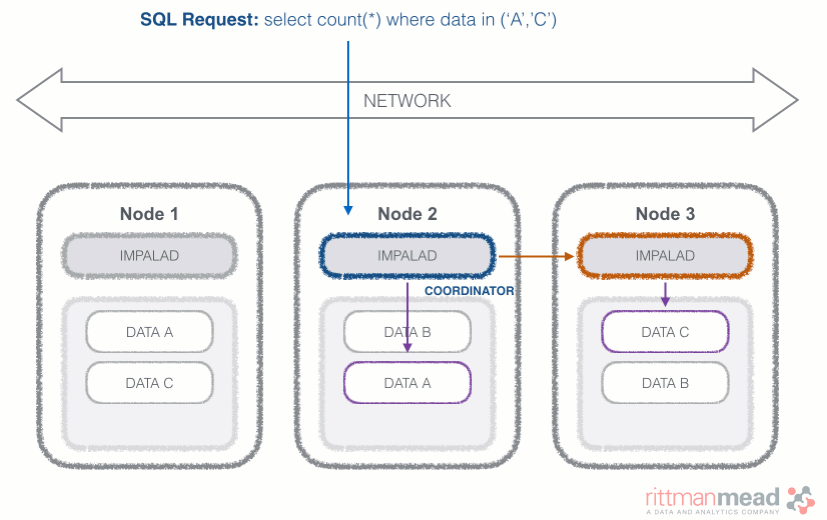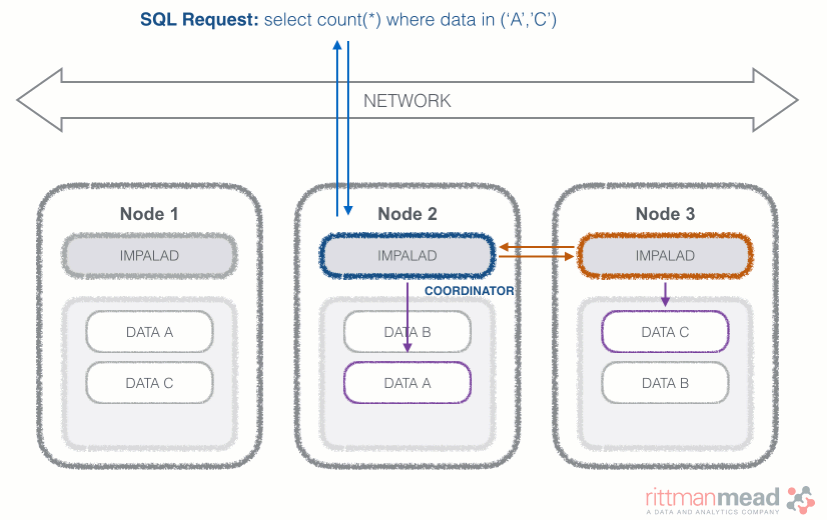
Impala runs a daemon, called impalad on each Datanode (a node storing data in the Hadoop cluster). The query can be submitted to any daemon in the cluster which will act as coordinator node for the query. Impala daemons are always connected to the statestore, which is a process keeping a central inventory of all available daemons and related health and pushes back the information to all daemons. A third component called catalog service checks for metadata changes driven by Impala SQL in order to invalidate related cache entries. Metadata are cached in Impala for performance reasons: accessing metadata from the cache is much faster than checking against the Hive metastore. The catalog service process is in charge of keeping Impala's metadata cache in sync with the Hive metastore.
Once the query is received, the coordinator verifies if the query is valid against the Hive metastore, then information about data location is retrieved from the Namenode (the node in charge of storing the list of blocks and related location in the datanodes), it fragments the query and distribute the fragments to other impalad daemons to execute the query. All the daemons read the needed data blocks, process the query, and stream partial result to the coordinator (avoiding the write to disk), which collects all the results and delivers it back to the requester. The result is returned as soon as it's available: certain SQL operations like aggregations or order by require all the input to be available before Impala can return the end result, while others, like a select of pre-existing columns without a order by can be returned with only partial results.
Apache Drill
Defining Apache Drill as SQL-on-Hadoop is limiting: also inspired by Google's Dremel is a distributed datasource agnostic query engine. The datasource agnostic part is very relevant: Drill is not closely coupled with Hadoop, in fact it can query a variety of sources like MongoDB, Azure Blob Storage, or Google Cloud Storage amongst others.
One of the most important features is that data can be queried schema-free: there is no need of defining the data structure or schema upfront - users can simply point the query to a file directory, MongoDB collection or Amazon S3 bucket and Drill will take care of the rest. For more details, check our overview of the tool. One of Apache Drill's objectives is cutting down the data modeling and transformation effort providing a zero-day analysis as explained in this MapR video.
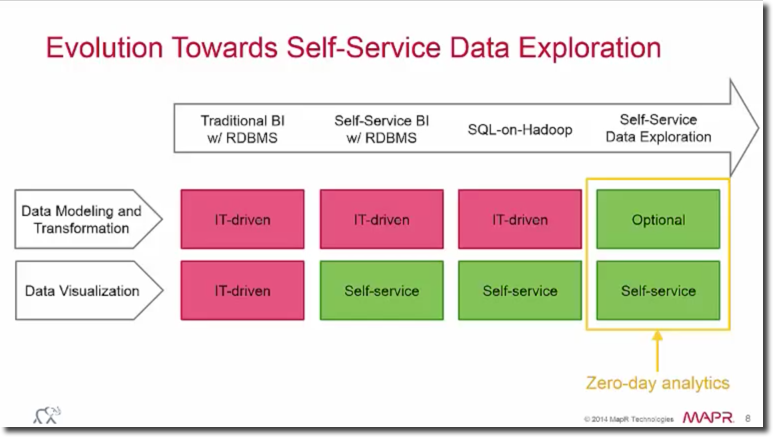
Drill is designed for high performance on large datasets, with the following core components:
- Distributed engine: Drill processes, called Drillbits, can be installed in many nodes and are the execution engine of the query. Nodes can be added/reduced manually to adjust the performances. Queries can be sent to any Drillbit in the cluster that will act as Foreman for the query.
- Columnar execution: Drill is optimized for columnar storage (e.g. Parquet) and execution using the hierarchical and columnar in-memory data model.
- Vectorization: Drill take advantage of the modern CPU's design - operating on record batches rather than iterating on single values.
- Runtime compilation: Compiled code is faster than interpreted code and is generated ad-hoc for each query.
- Optimistic and pipelined query execution: Drill assumes that none of the processes will fail and thus does all the pipeline operation in memory rather than writing to disk - writing on disk only when memory isn't sufficient.
Drill Query Process
Like Impala's impalad, Drill's main component is the Drillbit: a process running on each active Drill node that is capable of coordinating, planning, executing and distributing queries. Installing Drillbit on all of Hadoop's data nodes is not compulsory, however if done gives Drill the ability to achieve the data locality: execute the queries where the data resides without the need of moving it via network.
When a query is submitted against Drill, a client/application is sending a SQL statement to a Drillbit in the cluster (any Drillbit can be chosen), which will act as Foreman (coordinator in Impala terminology) that will parse the SQL and convert it into a logical plan composed by operators. The next step is the cost-based optimizer which, based on optimizations like rule/cost based, data locality and storage engine options, rearranges operations to generate the optimal physical plan. The Foreman then divides the physical plan in phases, called fragments, which are organised in a tree and executed in parallel against the data sources. The results are then sent back to the client/application. The following image taken from drill.apache.org explains the full process:

Similarities and Differences
As we saw above, Drill and Impala have a similar structure - both take advantage of always on daemons (faster compared to the start of a MapReduce job) and assume an optimistic query execution passing results in cache. The code compilation and the distributed engine are also common to both, which are optimized for columnar storage types like Parquet.
There are, however, several differences. Impala works only on top of the Hive metastore while Drill supports a larger variety of data sources and can link them together on the fly in the same query. For example, implicit schema-defined files like JSON and XML, which are not supported natively by Impala, can be read immediately by Drill.
Drill usually doesn't require a metadata definition done upfront, while for Impala, a view or external table has to be declared before querying. Following this point there is no concept of a central and persistent metastore, and there is no metadata repository to manage just for Drill. In OBIEE's world, both Impala and Drill are supported data sources. The same applies to Data Visualization Desktop.
The aim of this article isn't a performance-wise comparison since those depends on a huge amount of factors including data types, file format, configurations, and query types. A comparison dated back in 2015 can be found here. Please be aware that there are newer versions of the tools since this comparison, which bring a lot of changes and improvements for both projects in terms of performance.
Conclusion
Impala and Drill share a similar structure - both inspired by Google's Dremel - relying on always active daemons deployed on cluster nodes to provide the best query performances on top of Big Data data structures. So which one to choose and when?
As described, the capability of Apache Drill to query a raw data-source without requiring an upfront metadata definition makes the tool perfect for insights discovery on top of raw data. The capacity of joining data coming from one or more storage plugins in a unique query makes the mash-up of disparate data sources easy and immediate. Data science and prototyping before the design of a reporting schema are perfect use cases of Drill. However, as part of the discovery phase, a metadata definition layer is usually added on top of the data sources. This makes Impala a good candidate for reporting queries.
Summarizing, if all the data points are already modeled in the Hive metastore, then Impala is your perfect choice. If instead, you need a mashup with external sources, or need work directly with raw data formats (e.g. JSON), then Drill's auto-exploration and openness capabilities are what you're looking for.
Even though both tools are fully compatible with Oracle BIEE and Data Visualization (DV), due to Drill's data exploration nature, it could be considered more in line with DV use cases, while Impala is more suitable for standard reporting like OBIEE. The decision on tooling highly depends on the specific use case - source data types, file formats and configurations have deep impact on the agility of the business analytics process and query performance.
If you want to know more about Apache Drill, Impala and the use cases we have experienced, don't hesitate to contact us!

