Tag Archives: Oracle Database
Metadata Modeling in the Database with Analytic Views
12.2, the latest Oracle database release provides a whole set of new features enhancing various aspects of the product including JSON support, Auto-List Partitioning and APEX news among others. One of the biggest news in the Data Warehousing / Analytics area was the introduction of the Analytic Views, that as per Oracle's definition are
Metadata objects that enable the user to quickly and easily create complex hierarchical and dimensional queries on data in database tables and views
tl;dr
If you are on rush, here is an abstract of what you'll find in this looooong blog post:
Metadata modeling can now be done directly in the database using Analytic Views, providing to end users a way of querying database objects without needing a knowledge of joining conditions, aggregation functions or order by clauses.
This post will guide you through the creation of an analytic view that replicates a part of a OBIEE's Sampleapp business model. The latest part of the post is dedicated to understanding the usage of analytic views and the benefits for end users especially in cases when self-service BI tools are used.

If you are still around and interested in the topic please take a drink and sit comfortably, it will be a good journey.
Metadata Modeling
What are then the Analytics Views in detail? How are they going to improve end user's ability in querying data?
To answer above question I would take a step back. Many readers of this blog are familiar with OBIEE and its core: the Repository. The repository contains the metadata model from the physical sources till the presentation areas and includes the definition of:
- Joins between tables
- Hierarchies for dimensions
- Aggregation rules
- Security settings
- Data Filters
- Data Sources
This allows end users to just pick columns from a Subject Area and display them in the appropriate way without needing to worry about writing SQL or knowing how the data is stored. Moreover definitions are held centrally providing the famous unique source of truth across the entire enterprise.
The wave of self-service BI tools like Tableau or Oracle's Data Visualization Desktop provided products capable of querying almost any kind of data sources in a visual and intuitive way directly in the end user hands. An easy and direct access to data is a good thing for end user but, as stated above, requires knowledge of the data model, joins and aggregation methods.
The self-service tools can slightly simplify the process by providing some hints based on column names, types or values but the cruel reality is that the end-user has to build the necessary knowledge of the data source before providing correct results. This is why we've seen several times self-service BI tools being "attached" to OBIEE: get corporate official data from the unique source of truth and mash them up with information coming from external sources like personal Excel files or output of Big Data processes.
Analytics Views
Analytic Views (AV) take OBIEE's metadata modeling concept and move it at database level providing a way of organizing data in a dimensional model so it can be queried with simpler SQL statements.
The Analytical Views are standard views with the following extra options:
- Enable the definition of facts, dimensions and hierarchies that are included in system-generated columns
- Automatically aggregate the data based on pre-defined calculations
- Include presentation metadata
Analytics views are created with a CREATE ANALYTIC VIEW statement, some privileges need to be granted to the creating user, you can find the full list in Oracle's documentation.
Every analytical view is composed by the following metadata objects:
- Attribute dimensions: organising table/view columns into attributes and levels.
- Hierarchies: defining hierarchical relationships on top of an attribute dimension object.
- Analytic view objects: defining fact data referencing both fact tables and hierarchies.
With all the above high level concepts in mind it's now time to try how Analytical Views could be used in a reporting environment.
Database Provisioning
For the purpose blog post I used Oracle's 12.2.0.1 database Docker image, provided by Gerald Venzl, the quickest way of spinning up a local instance. You just need to:
- Install Docker
- Download database installer from Oracle's website
- Place the installer in the proper location mentioned in the documentation
- Build Oracle Database 12.1.0.2 Enterprise Edition Docker image by executing
./buildDockerImage.sh -v 12.1.0.2 -e
- Running the image by executing
docker run --name db12c -p 1521:1521 -p 5500:5500 -e ORACLE_SID=orcl -e ORACLE_PDB=pdborcl -e ORACLE_CHARACTERSET=AL32UTF8 oracle/database:12.2.0.1-ee
The detailed parameters definition can be found in the GitHub repository. You can then connect via sqlplus to your local instance by executing the standard
sqlplus sys/pwd@//localhost:1521/pdborcl as sysdba
The password is generated automatically during the first run of the image and can be found in the logs, look for the following string
ORACLE AUTO GENERATED PASSWORD FOR SYS, SYSTEM AND PDBAMIN: XXXXxxxxXXX
Once the database is created it's time to set the goal: I'll try to recreate a piece of the Oracle's Sampleapp RPD model in the database using Analytic Views.
Model description
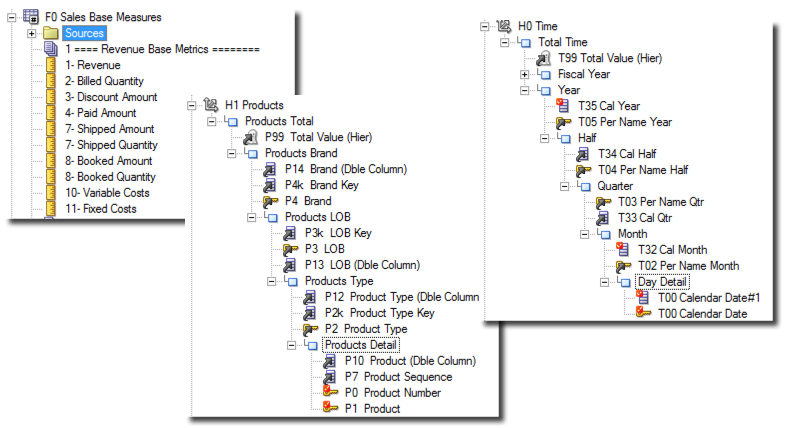
In this blog post I'll look in the 01 - Sample App business model and specifically I'll try to replicate the logic behind Time, Product and the F0 Sales Base Measures using Analytic Views.
Dim Product
The Sampleapp's D1 - Products (Level Based Hierarchy) is based on two logical table sources: SAMP_PRODUCTS_D providing product name, description, LOB and Brand and the SAMP_PROD_IMG_D containing product images. For the purpose of this test we'll keep our focus on SAMP_PRODUCTS_D only.
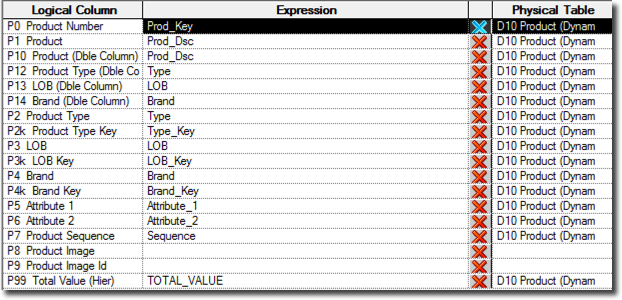
The physical mapping of Logical columns is shown in the image below.
Attribute Dimension
The first piece we're going to build is the attribute dimension, where we'll be defining attributes and levels. The mappings in above image can "easily" be translated into an attributes with the following SQL.
CREATE OR REPLACE ATTRIBUTE DIMENSION D1_DIM_PRODUCT
USING SAMP_PRODUCTS_D
ATTRIBUTES
(PROD_KEY as P0_Product_Number
CLASSIFICATION caption VALUE 'P0 Product Number',
PROD_DSC as P1_Product
CLASSIFICATION caption VALUE 'P1 Product',
TYPE as P2_Product_Type
CLASSIFICATION caption VALUE 'P2 Product Type',
TYPE_KEY as P2k_Product_Type
CLASSIFICATION caption VALUE 'P2k Product Type',
LOB as P3_LOB
CLASSIFICATION caption VALUE 'P3 LOB',
LOB_KEY as P3k_LOB
CLASSIFICATION caption VALUE 'P3k LOB',
BRAND as P4_Brand
CLASSIFICATION caption VALUE 'P4 Brand',
BRAND_KEY as P4k_Brand
CLASSIFICATION caption VALUE 'P4k Brand',
ATTRIBUTE_1 as P5_Attribute_1
CLASSIFICATION caption VALUE 'P5 Attribute 1',
ATTRIBUTE_2 as P6_Attribute_2
CLASSIFICATION caption VALUE 'P6 Attribute 2',
SEQUENCE as P7_Product_Sequence
CLASSIFICATION caption VALUE 'P7 Product Sequence',
TOTAL_VALUE as P99_Total_Value
CLASSIFICATION caption VALUE 'P99 Total Value')
Few pieces to note:
CREATE OR REPLACE ATTRIBUTE DIMENSION: we are currently defining a dimension, the attributes and levels.USING SAMP_PRODUCTS_D: defines the datasource, in our case the tableSAMP_PRODUCTS_D. Only one datasource is allowed per dimension.PROD_KEY as P0_Product_Number: using the standard notificationaswe can easily recaption columns namesCLASSIFICATION CAPTION ...several options can be added for each attribute like caption or description
The dimension definition is not complete with only attribute declaration, we also need to define the levels. Those can be taken from OBIEE's hierarchy
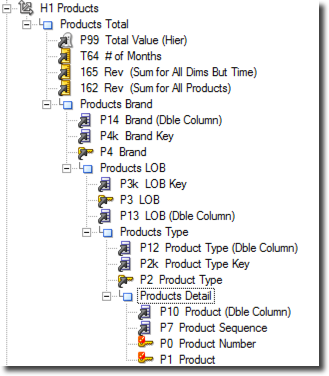
For each level we can define:
- The level name, caption and description
- The Key
- the Member Name and Caption
- the Order by Clause
Translating above OBIEE's hierarchy levels into Oracle SQL
LEVEL BRAND
CLASSIFICATION caption VALUE 'BRAND'
CLASSIFICATION description VALUE 'Brand'
KEY P4k_Brand
MEMBER NAME P4_Brand
MEMBER CAPTION P4_Brand
ORDER BY P4_Brand
LEVEL Product_LOB
CLASSIFICATION caption VALUE 'LOB'
CLASSIFICATION description VALUE 'Lob'
KEY P3k_LOB
MEMBER NAME P3_LOB
MEMBER CAPTION P3_LOB
ORDER BY P3_LOB
DETERMINES(P4k_Brand)
LEVEL Product_Type
CLASSIFICATION caption VALUE 'Type'
CLASSIFICATION description VALUE 'Type'
KEY P2k_Product_Type
MEMBER NAME P2_Product_Type
MEMBER CAPTION P2_Product_Type
ORDER BY P2_Product_Type
DETERMINES(P3k_LOB,P4k_Brand)
LEVEL Product_Details
CLASSIFICATION caption VALUE 'Detail'
CLASSIFICATION description VALUE 'Detail'
KEY P0_Product_Number
MEMBER NAME P1_Product
MEMBER CAPTION P1_Product
ORDER BY P1_Product
DETERMINES(P2k_Product_Type,P3k_LOB,P4k_Brand)
ALL MEMBER NAME 'ALL PRODUCTS';
There is an additional DETERMINES line in above sql for each level apart from Brand, this is how we can specify the relationship between level keys. If we take the Product_LOB example, the DETERMINES(P4k_Brand) defines that any LOB in our table automatically determines a Brand (in OBIEE terms that LOB is a child of Brand).
Hierarchy
Next step is defining a hierarchy on top of the attribute dimension D1_PRODUCTS defined above. We can create it just by specifying:
- the attribute dimension to use
- the list of levels and the relation between them
which in our case becomes
CREATE OR REPLACE HIERARCHY PRODUCT_HIER
CLASSIFICATION caption VALUE 'Products Hierarchy'
USING D1_DIM_PRODUCT
(Product_Details CHILD OF
Product_Type CHILD OF
Product_LOB CHILD OF
BRAND);
When looking into the hierarchy Product_hier we can see that it's creating an OLAP-style dimension with a row for each member at each level of the hierarchy and extra fields like DEPT, IS_LEAF and HIER_ORDER

The columns contained in Product_hier are:
- One for each Attribute defined in attribute dimension
D1_PRODUCTSlikeP0_PRODUCT_NUMBERorP2K_PRODUCT_TYPE - The member name, caption and description and unique name
- The level name in the hierarchy and related depth
- The relative order of the member in the hierarchy
- A field
IS_LEAFflagging hierarchy endpoints - References to the parent level
Member Unique Names
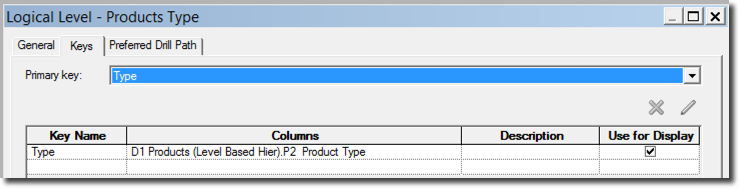
A particularity to notice is that the MEMBER_UNIQUE_NAME of Cell Phones is [PRODUCT_TYPE].&[101] which is the concatenation of the LEVEL and the P2K_PRODUCT_TYPE value.
One could expect the member unique name being represented as the concatenation of all the preceding hierarchy members, Brand and LOB, and the member key itself in a string like [PRODUCT_TYPE].&[10001]&[1001]&[101].
This is the default behaviour, however in our case is not happening since we set the DETERMINES(P3k_LOB,P4k_Brand) in the attribute dimension definition. We Specified that Brand ([10001]) and LOB ([1001]) can automatically be inferred by the Product Type so there is no need to store those values in the member key. We can find the same setting in OBIEE's Product Type logical level
Dim Date
The basic D0 Dim Date can be built starting from the table SAMP_TIME_DAY_D following the same process as above. Like in OBIEE, some additional settings are required when creating a time dimension:
DIMENSION TYPE TIME: the time dimension type need to be specifiedLEVEL TYPE <LEVEL_NAME>: each level in the time hierarchy needs to belong to a precise level type chosen from:- YEARS
- HALF_YEARS
- QUARTERS
- MONTHS
- WEEKS
- DAYS
- HOURS
- MINUTES
- SECONDS
Attribute Dimension
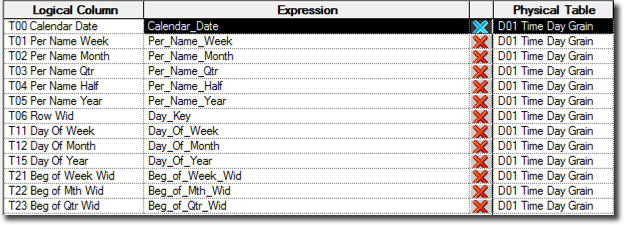
Taking into consideration the additional settings, the Dim Date column mappings in above image can be translated in the following attribute dimension SQL definition.
CREATE OR REPLACE ATTRIBUTE DIMENSION D0_DIM_DATE
DIMENSION TYPE TIME
USING SAMP_TIME_DAY_D
ATTRIBUTES
(CALENDAR_DATE AS TOO_CALENDAR_DATE,
PER_NAME_MONTH AS T02_PER_NAME_MONTH,
PER_NAME_QTR AS T03_PER_NAME_QTR,
PER_NAME_YEAR AS T04_PER_NAME_YEAR,
DAY_KEY AS T06_ROW_WID,
BEG_OF_MTH_WID AS T22_BEG_OF_MTH_WID,
BEG_OF_QTR_WID AS T23_BEG_OF_QTR_WID
)
LEVEL CAL_DAY
LEVEL TYPE DAYS
KEY TOO_CALENDAR_DATE
ORDER BY TOO_CALENDAR_DATE
DETERMINES(T22_BEG_OF_MTH_WID, T23_BEG_OF_QTR_WID,T04_PER_NAME_YEAR)
LEVEL CAL_MONTH
LEVEL TYPE MONTHS
KEY T22_BEG_OF_MTH_WID
MEMBER NAME T02_PER_NAME_MONTH
ORDER BY T22_BEG_OF_MTH_WID
DETERMINES(T23_BEG_OF_QTR_WID,T04_PER_NAME_YEAR)
LEVEL CAL_QUARTER
LEVEL TYPE QUARTERS
KEY T23_BEG_OF_QTR_WID
MEMBER NAME T03_PER_NAME_QTR
ORDER BY T23_BEG_OF_QTR_WID
DETERMINES(T04_PER_NAME_YEAR)
LEVEL CAL_YEAR
LEVEL TYPE YEARS
KEY T04_PER_NAME_YEAR
MEMBER NAME T04_PER_NAME_YEAR
ORDER BY T04_PER_NAME_YEAR
ALL MEMBER NAME 'ALL TIMES';
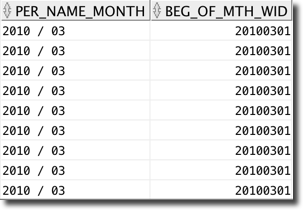
You may have noticed a different mapping of keys, member names and order by attributes. Let's take the CAL_MONTH as example. It's defined by two columns
BEG_OF_MTH_WID: used for joins and orderingPER_NAME_MONTH: used as "display label"
PER_NAME_MONTH in the YYYY / MM format could be also used for ordering, but most of the times end user requests months in the MM / YYYY format. Being able to set a ordering column different from the member name allows us to properly manage the hierarchy.
Hierarchy
Time hierarchy follows the same rules as the product one, no additional settings are required.
CREATE OR REPLACE HIERARCHY TIME_HIER
USING D0_DIM_DATE
(CAL_DAY CHILD OF
CAL_MONTH CHILD OF
CAL_QUARTER CHILD OF
CAL_YEAR);
Fact Sales
The last step in the journey is the definition of the analytic view of the fact table that as per Oracle's documentation
An analytic view specifies the source of its fact data and defines measures that describe calculations or other analytic operations to perform on the data. An analytic view also specifies the attribute dimensions and hierarchies that define the rows of the analytic view.
The analytic view definition contains the following specifications:
- The data source: the table or view that will be used for the calculation
- The columns: which columns from the source objects to use in the calculations
- The attribute dimensions and hierarchies: defining both the list of attributes and the levels of the analysis
- The measures: a set of aggregations based on the predefined columns from the data source.
Within analytical views definition a materialized view can be defined in order to store aggregated values. This is a similar to OBIEE's Logical Table Source setting for aggregates.
Analytic View Definition
For the purpose of the post I'll use SAMP_REVENUE_F which is one of the sources of F0 Sales Base Measures in Sampleapp. The following image shows the logical column mapping.

The above mappings can be translated in the following SQL
CREATE OR REPLACE ANALYTIC VIEW F0_SALES_BASE_MEASURES
USING SAMP_REVENUE_F
DIMENSION BY
(D0_DIM_DATE
KEY BILL_DAY_DT REFERENCES TOO_CALENDAR_DATE
HIERARCHIES (
TIME_HIER DEFAULT),
D1_DIM_PRODUCT
KEY PROD_KEY REFERENCES P0_Product_Number
HIERARCHIES (
PRODUCT_HIER DEFAULT)
)
MEASURES
(F1_REVENUE FACT REVENUE AGGREGATE BY SUM,
F10_VARIABLE_COST FACT COST_VARIABLE AGGREGATE BY SUM,
F11_FIXED_COST FACT COST_FIXED AGGREGATE BY SUM,
F2_BILLED_QTY FACT UNITS,
F3_DISCOUNT_AMOUNT FACT DISCNT_VALUE AGGREGATE BY SUM,
F4_AVG_REVENUE FACT REVENUE AGGREGATE BY AVG,
F21_REVENUE_AGO AS (LAG(F1_REVENUE) OVER (HIERARCHY TIME_HIER OFFSET 1))
)
DEFAULT MEASURE F1_REVENUE;
Some important parts need to be highlighted:
USING SAMP_REVENUE_F: defines the analytic view source, in our case the tableSAMP_REVENUE_FDIMENSION BY: this section provides the list of dimensions and related hierarchies to take into accountKEY BILL_DAY_DT REFERENCES TOO_CALENDAR_DATE: defines the join between the fact table and attribute dimensionHIERARCHIES (TIME_HIER DEFAULT): multiple hierarchies can be defined on top of an attribute dimension and used in an analytical view, however like in OBIEE only one will be used by defaultF1_REVENUE FACT REVENUE AGGREGATE BY SUM: defines the measure with alias, source column and aggregation methodF2_BILLED_QTY FACT UNITS: if aggregation method is not defined it replies on defaultSUMF21_REVENUE_AGO: new metrics can be calculated based on previously defined columns replicating OBIEE functions like time-series. The formula(LAG(F1_REVENUE) OVER (HIERARCHY TIME_HIER OFFSET 1))calculates the equivalent of the OBIEE'sAGOfunction for each level of the hierarchy.DEFAULT MEASURE F1_REVENUE: defines the default measure of the analytic view
Using Analytic Views
After the analytic view definition, it's time to analyse what benefits end users have when using them. We are going to take a simple example: a query to return the Revenue and Billed Qty per Month and Brand.
Using only the original tables we would have the following SQL
SELECT D.CAL_MONTH,
D.BEG_OF_MTH_WID,
P.BRAND,
SUM(F.REVENUE) AS F01_REVENUE,
SUM(F.UNITS) AS F02_BILLED_QTY
FROM SAMP_REVENUE_F F
JOIN SAMP_PRODUCTS_D P
ON (F.PROD_KEY = P.PROD_KEY)
JOIN SAMP_TIME_DAY_D D
ON (F.BILL_DAY_DT = D.CALENDAR_DATE)
GROUP BY D.CAL_MONTH,
D.BEG_OF_MTH_WID,
P.BRAND
ORDER BY D.BEG_OF_MTH_WID,
P.BRAND;
The above SQL requires the knowledge of:
- Aggregation methods
- Joins
- Group by
- Ordering
Even if this is an oversimplification of the analytic view usage you can already spot that some knowledge of the base data structure and SQL language is needed.
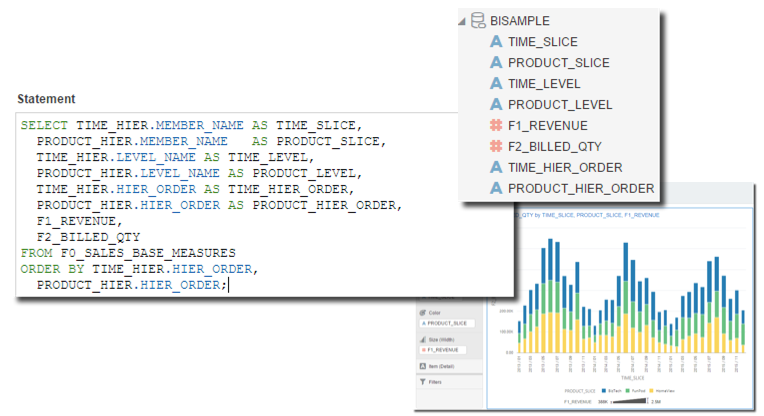
Using the analytic views defined above, the query can be written as
SELECT TIME_HIER.MEMBER_NAME AS TIME_SLICE,
PRODUCT_HIER.MEMBER_NAME AS PRODUCT_SLICE,
F1_REVENUE,
F2_BILLED_QTY
FROM F0_SALES_BASE_MEASURES
WHERE TIME_HIER.LEVEL_NAME IN ('CAL_MONTH')
AND PRODUCT_HIER.LEVEL_NAME IN ('BRAND')
ORDER BY TIME_HIER.HIER_ORDER,
PRODUCT_HIER.HIER_ORDER;
As you can see, there is a simplification of the SQL statement: no more aggregation, joining conditions and group by predicates are needed. All the end-user has to know is the analytical view name, and the related hierarchies that can be used.
The additional benefit is that if we want to change the level of granularity of the above query we just need to change the WHERE condition. E.g. to have the rollup per Year and LOB we just have to substitute
WHERE TIME_HIER.LEVEL_NAME IN ('CAL_MONTH')
AND PRODUCT_HIER.LEVEL_NAME IN ('BRAND')
with
WHERE TIME_HIER.LEVEL_NAME IN ('CAL_YEAR')
AND PRODUCT_HIER.LEVEL_NAME IN ('LOB')
without touching granularity, group by and order by statements.
Using Analytic Views in DVD
At the beginning of my blog post I wrote that Analytic Views could be useful when used in conjunction with self-service BI tools. Let's have a look at how the end user journey is simplified in the case of Oracle's Data Visualization Desktop.
Without AV the end-user had two options to source the data:
- Write the complex SQL statement with joining condition, group and order by clause in the SQL editor to retrieve data at the correct level with the related dimension
- Import the fact table and dimensions as separate datasources and join them together in DVD's project.
Both options require a SQL and joining conditions knowledge in order to being able to present correct data. Using Analytic Views the process is simplified. We just need to create a new source pointing to the database where the analytic views are sitting.
Next step is retrieve the necessary columns from the analytic view. Unfortunately analytic views are not visible from DVD object explorer (only standard table and views are shown)
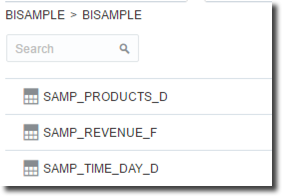
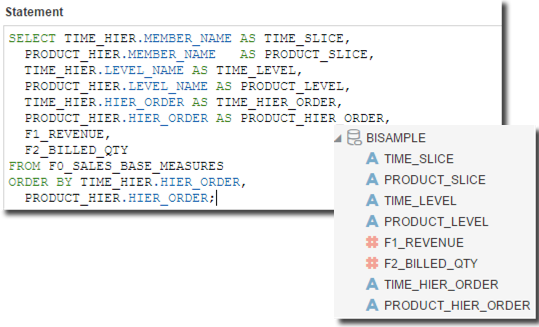
We can however specify with a simple SQL statement all the informations we need like Time and Member Slice, the related levels and the order in hierarchy.
SELECT TIME_HIER.MEMBER_NAME AS TIME_SLICE,
PRODUCT_HIER.MEMBER_NAME AS PRODUCT_SLICE,
TIME_HIER.LEVEL_NAME AS TIME_LEVEL,
PRODUCT_HIER.LEVEL_NAME AS PRODUCT_LEVEL,
TIME_HIER.HIER_ORDER AS TIME_HIER_ORDER,
PRODUCT_HIER.HIER_ORDER AS PRODUCT_HIER_ORDER,
F1_REVENUE,
F2_BILLED_QTY
FROM F0_SALES_BASE_MEASURES
ORDER BY TIME_HIER.HIER_ORDER,
PRODUCT_HIER.HIER_ORDER;
You may have noted that I'm not specifying any WHERE clause for level filtering: as end user I want to be able to retrieve all the necessary levels by just changing a filter in my DVD project. After including the above SQL in the datasource definition and amending the measure/attribute definition I can start playing with the analytic view data.
I can simply include the dimension's MEMBER_NAME in the graphs together with the measures and add the LEVEL_NAME in the filters. In this way I can change the graph granularity by simply selecting the appropriate LEVEL in the filter selector for all the dimensions available.
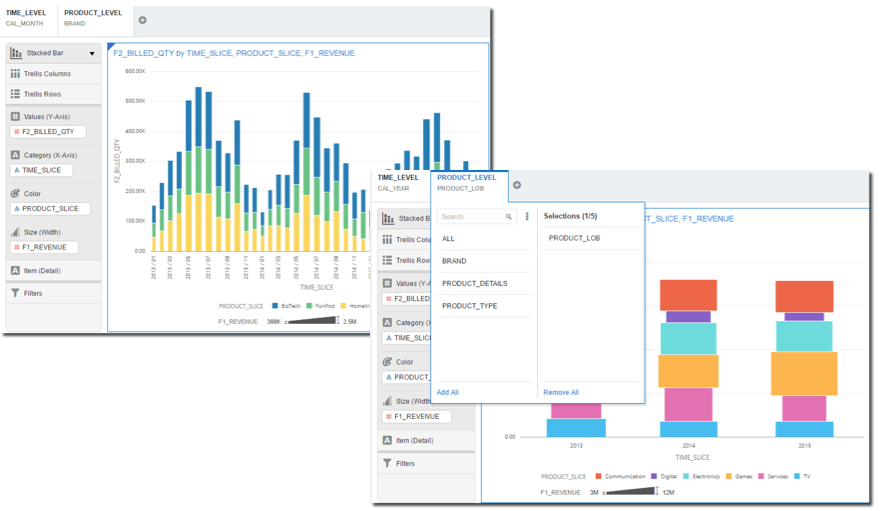
One particular to notice however is that all the data coming from various columns like date, month and year are "condensed" into a single VARCHAR column. In case of different datatypes (like date in the time dimension) this will prevent a correct usage of some DVD's capabilities like time series or trending functions. However if a particular type of graph is needed for a specific level, either an ad-hoc query or a casting operation can be used.
Conclusion
In this blog post we analysed the Analytic Views, a new component in Oracle Database 12.2 and how those can be used to "move" the metadata modeling at DB level to provide an easier query syntax to end-users.
Usually metadata modeling is done in reporting tools like OBIEE that offers additional set of features on top of the one included in analytic views. However centralized reporting tools like OBIEE are not present everywhere and, with the wave of self-service BI tools, analytic views represent a perfect method of enabling users not familiar with SQL to simply query their enterprise data.
If you are interested in understanding more about analytic views or metadata modeling, don't hesitate to contact us!
If you want to improve the SQL skills of your company workforce, check out our recently launched SQL for beginners training!
Rittman Mead BI Forum 2015 Call for Papers Now Open!
I’m very pleased to announce that the Call for Papers for the Rittman Mead BI Forum 2015 is now open, with abstract submissions open to January 18th 2015. As in previous years the BI Forum will run over consecutive weeks in Brighton, UK and Atlanta, GA, with the provisional dates and venues as below:
- Brighton, UK : Hotel Seattle, Brighton, UK : May 6th – 8th 2015
- Atlanta, GA : Renaissance Atlanta Midtown Hotel, Atlanta, USA : May 13th-15th 2015
Now on it’s seventh year, the Rittman Mead BI Forum is the only conference dedicated entirely to Oracle Business Intelligence, Oracle Business Analytics and the technologies and processes that support it – data warehousing, data analysis, data visualisation, big data and OLAP analysis. We’re looking for session around tips & techniques, project case-studies and success stories, and sessions where you’ve taken Oracle’s BI products and used them in new and innovative ways. Each year we select around eight-to-ten speakers for each event along with keynote speakers and a masterclass session, with speaker choices driven by attendee votes at the end of January, and editorial input from myself, Jon Mead and Charles Elliott and Jordan Meyer.

Last year we had a big focus on cloud, and a masterclass and several sessions on bringing Hadoop and big data to the world of OBIEE. This year we’re interested in project stories and experiences around cloud and Hadoop, and we’re keen to hear about any Oracle BI Apps 11g implementations or migrations from the earlier 7.9.x releases. Getting back to basics we’re always interested in sessions around OBIEE, Essbase and data warehouse data modelling, and we’d particularly like to encourage session abstracts on data visualization, BI project methodologies and the incorporation of unstructured, semi-structured and external (public) data sources into your BI dashboards. For an idea of the types of presentations that have been selected in the past, check out the BI Forum 2014, 2013 and 2012 homepages, or feel free to get in touch via email at mark.rittman@rittmanmead.com.
The Call for Papers entry form is here, and we’re looking for speakers for Brighton, Atlanta, or both venues if you can speak at both. All session this year will be 45 minutes long, all we’ll be publishing submissions and inviting potential attendees to vote on their favourite sessions towards the end of January. Other than that – have a think about abstract ideas now, and make sure you get them in by January 18th 2015.
Oracle 12.1.0.2 and Data Warehouses
If you follow Blogs and Tweets from the Oracle community you won’t have missed hearing about the recent release of the first patch-set for Oracle 12c. With this release there are some significant pieces of new functionality that will be of interest to Data Warehouse DBAs and architects. The headline feature that most Oracle followers will know of is the new in-memory option. In my opinion this is a game-changer for how we design reporting architectures; it gives us an effective way to build operational reporting over the reference data architecture described by Mark Rittman a few weeks ago. Of course, the database team here at Rittman Mead have been rolling up our sleeves and getting into in-memory technology for quite a while now, Mark even featured in the official launch presentation by Larry Ellison with the now famous “so easy it’s boring” quote. Last week Mark published the first of our Rittman Mead in-memory articles, with the promise of more in-memory articles to come including my article for the next edition of UKOUG’s “Oracle Scene”.
However, the in-memory option is not the only new feature that is going to be a benefit to us in the BI/DW world. One of the new features I am going to describe is Exadata only, but the first one I am going to mention is generally available in the 12.1.0.2 database.
Typically, data warehouse queries are different from those seen in the OLTP world – in DW we tend to access a large number of rows and probably aggregate things up to answer some business question. Often we are not using indexes and instead scanning tables or table partitions is the norm. Usually, the data we need to aggregate is widely scattered across the table or partition. Data Warehouse queries often look at records that share a set of common attributes; we look at the sales for the ‘ACME’ widget or the value of items shipped to Arizona. For us there can be great advantage if data we use together is stored together, and this is where Attribute Clustering can pay a part.
Attribute Clustering is usually configured on the table at at DDL time and in-effect controls the ordering of data inserted by DIRECT PATH operations, Oracle does not enforce this ordering for conventional inserts, this may not be an issue in data warehouses as bulk-batch operations typically use APPEND inserts, which are direct path inserts, or partition operations, it may be more of an issue with some of the real-time conventional path loading paradigms. In addition to Direct Path load operations Attribute Clustering can also occur when you do Alter table MOVE type operations (this also includes operations such as PARTITION SPLIT). On the surface, Attribute Clustering sounds little different to using an ORDER by on an append insert and hoping that Oracle actually stores the data where you expect it to. However, Attribute Clustering gives us two other possibilities in how we can order the data in the cluster.
Firstly, we can cluster on columns from JOINED dimension tables, for example in a SALES DW we may have a sales fact with a product key at the SKU level, but we often join to the product dimension and report at the Product Category level. In this case we can cluster our sales fact table so that each product category appears in the same cluster. For example, we have just opened a chain a supermarkets with a wide but uninspiring range of brands and products (see the tiny piece of our product dimension table below)

As you can see, our Product PK has no relationship at all to the type of product being sold. In our Kimball-style data warehouse we typically store the product key on the fact table and join to the product dimension to obtain all of the other product attributes and hierarchy members. This is essentially what we can do with join Attribute Clustering, in our example we can cluster our fact table on PRODUCT_CATEGORY so that all of the Laundry sales are physically close to each other in the Fact table.
CREATE TABLE rm_sales ( product_idNUMBER NOT NULL, store_id NUMBER NOT NULL, sales_date DATE NOT NULL, loyalty_card_id NUMBER , quantity_sold NUMBER(3) NOT NULL, value_sold NUMBER(10,2) NOT NULL ) CLUSTERING rm_sales JOIN products ON (rm_sales.product_id = products.product_pk) BY LINEAR ORDER (sales_date, product_category, store_id);
Notice we are clustering on a join to the product dimension table’s “product_category” column, we are also clustering on sales_date, this is especially important in the case of partitioned fact tables so that the benefits of clustering align to the partitioning strategy. We are also not restricted in our clustering to just one join, if we wanted to we could also cluster our sales by store region e.g. the Colorado laundry product sales are located in the same area of the sales table. To use Join Attribute Clustering we need to define the PK / FK relationships between fact and dimension, however it is always good practice to have that in place as it helps the CBO so much with query plan evaluation
Secondly, notice the BY LINEAR ORDER clause in the table DDL. Of the two ordering options, Linear Order is the most basic form of clustering, it this case we have our data structured so that all the items for a sales day are clustered together and within that cluster we order by product category and those categories are in turn ordered by store_id. The other way we can cluster is BY INTERLEAVED ORDER; here, Oracle maps a combination of dimensional values to a single cluster value using a z-order curve fitting approach. This sounds complex but it ensures that items that are frequently queried together are co-located in the disk blocks in the storage.
Interleaved ordering is probably the best choice for data warehousing at it aligns well with how we access data in our queries. Although we could include all of the dimension keys in our ordering list, it is going to be more benefit to just include a subset of dimensions; typically for retail I’d go with DATE (or something that correlates to the time based partition key of the fact table), the product and the store. Of course we can again join to the dimension tables and cluster at higher hierarchy levels such as product category and store region. The Oracle 12c Data Warehousing guide gives some good advice, but you can’t go far wrong if you think about clustering items together that will be queried together
Clustering data can give us some advantages in performance. Better data compression and improved index range scans spring to mind, but to get most benefits we should also look at another new feature, zone-maps. Unlike Attribute Clustering, Zone Maps are Engineered Systems only, In a way they are similar to storage indexes already found on Exadata, but they have some additional advantages, they are also somewhat different from zone maps encountered in other DB vendors’ products such as Netezza.
In Exadata, a storage index can provide the maximum and minimum values encountered for a column in storage cell. I say “can” as there is no guarantee that range for a given column is held in the storage index. Zone Maps on the other hand will always provide maxima and minima for all of the columns specified at zone map creation. The zone map is orientated in terms of contiguous database blocks and is materialized so that it is physically persisted in the database and thus survives DB startups. Like Materialized views Materialized zone maps can become stale and need to be maintained.
We can define a zone map on one or more table columns and just like Attribute Clustering we may also create zone maps on table joins. As a table can only have one zone map it is important to include all of the columns you wish to track. Zone Maps are designed to work well with attribute clustering, in fact it is just a simple DDL statement to add a zone-map to an Attribute Clustered table so that the zone map tracks the same attributes as the clustering. This is where we get the major performance boost from attribute clustering, Instead of looking at the whole table the zone map tells us which ranges of database blocks contain data that matches our query predicates.
Zone Maps with Attribute Clustering gives us another powerful tool to boost DW performance on Exadata – we can do star queries without resorting to bitmap indexes and we minimise IO when scanning fact tables as we only need look where we know the data to be. Exciting times!
Taking a Look at the Oracle Database 12c In-Memory Option
The In-Memory Option for Oracle Database 12c became available a few weeks ago with the 12.1.0.2 database patchset, adding column-store and in-memory capabilities to the Oracle Database. Unlike pure in-memory databases such as Oracle TimesTen, the in-memory option adds an in-memory column-store feature to the regular row-based storage in the Oracle database, creating in-memory copies of selected row-store tables in a compressed column-based storage format, with the whole process being automatic and and enabled by issuing just a couple of commands – to the point where my feedback at the end of beta testing was that it was “almost boring” – said slightly tongue-in-cheek…

But of course adding in-memory capabilities to the Oracle database is anything but boring – whilst TimesTen on Exalytics has given us the ability to store aggregate tables, and “hot data” tables in a dedicated in-memory database co-located with the BI mid-tier, TimesTen is another set of skills to learn and another product to manage. Moreover, you’ve got to somehow get the data you want to aggregate or otherwise cache out of your data warehouse and into TimesTen, and then you’ve got the even more difficult task of keeping that TimesTen dataset in-sync with your main data warehouse data. Most importantly though, even with the 2TB and 4TB versions of Exalytics many data warehouses won’t fit entirely into memory, so you’re going to end-up with some of your data in TimesTen and some in your data warehouse, and with only the TimesTen dataset benefiting from in-memory speeds.
So what if you could enable the in-memory option on your data warehouse, and then just run it all in-memory there? To see how this worked, I thought it’d be interesting to take the flight delays dataset that comes with the latest OBIEE 11g v406 SampleApp, and copy that across to an Oracle 12.1.0.2.0 database to test it out with the in-memory option. This dataset comes with a set of dashboard pages and analyses and contains around 6m rows of data, and in SampleApp is accelerated by an aggregate schema, also stored in Oracle, that generally reduces query times down to just a few seconds.

So what I thought would be interesting to check would be first, whether enabling the in-memory option sped-up the dashboards, and second, whether having the in-memory option removed the need for the aggregate tables altogether. I was also interested to see whether putting the aggregate tables into memory improved their access time significantly, as anecdotally I’d heard that there wasn’t much clock-time difference between accessing aggregates in a TimesTen database vs. just creating them in the same data warehouse database as the source data. To set this all up then I created the new 12.1.0.2.0 database,. exported the BI_AIRLINES and BI_AIRLINES_AGG schemas out of the 12c database that comes with SampleApp v406, and then imported them into the same schema names in the new 12.1.0.2.0 instance, on the new VM (rather than on the SampleApp VM), and then amended the connection pool details in the SampleApp RPD to point to this new, external Oracle 12.1.0.2.0 database instance. The 12.1.0.2.0 database at this point had the following memory allocation:
Connected to: Oracle Database 12c Enterprise Edition Release 12.1.0.2.0 - 64bit Production With the Partitioning, OLAP, Advanced Analytics and Real Application Testing options SQL> shutdown immediate; Database closed. Database dismounted. ORACLE instance shut down. SQL> startup ORACLE instance started. Total System Global Area 6325010432 bytes Fixed Size 2938448 bytes Variable Size 1207962032 bytes Database Buffers 5100273664 bytes Redo Buffers 13836288 bytes Database mounted. Database opened.
So I don’t end-up comparing the larger database instance on my 12.1.0.2.0 VM with the smaller one the airlines data came from on the VM, I created my baseline response time measurements on this new VM and with none of the in-memory features enabled, and ran some of the dashboard pages and clicked-on some of the prompt values – and the response time wasn’t bad, with just the odd analysis that took an excessive time to return. Mostly though, the results for each dashboard came back straight-away, what you’d expect when summary tables have been deployed to speed-up reporting.

Looking at the SQL being generated by the BI Server, you can quickly see why this is the case; the BI Server is using aggregate navigation and actually querying the BI_AIRLINES_AGG schema to return the aggregated results the dashboard, as you can see from one of the SQL statements retrieved from the NQQuery.log file below:
select sum(T255906.Dep_Delay_00039B26) as c1,
sum(T255906.Arr_Delay_00039B22) as c2,
sum(T255906.Z_of_Fligh00039B28) as c3,
substr(T255216.Carrier00039BA9 , 1, 25) as c4,
T255216.Carrier00039BA9 as c5,
T255216.Carrier_Co00039BAA as c6
from
BI_AIRLINES_AGG.SA_16_Dest00039D06 T255357,
BI_AIRLINES_AGG.SA_Time_Mo00039CFB T255737,
BI_AIRLINES_AGG.SA_31_Carr00039CEB T255216,
BI_AIRLINES_AGG.FACT_AGG_OR_06M T255906
where ( T255216.Carrier_Co00039BAA = T255906.Carrier_Co00039BAA and T255357.Dest_Airpo00039C2A = T255906.Dest_Airpo00039C2A and T255737.Dep_Month00039C07 = T255906.Dep_Month00039C07 and substr(T255216.Carrier00039BA9 , 1, 25) = 'SunFlower Airlines' and (T255357.Dest_Regio00039C31 in ('Midwest Region', 'Northeast Region', 'South Region', 'West Region')) and T255737.Month_of_Y00039C0F between 3 and 12 )
group by T255216.Carrier00039BA9, T255216.Carrier_Co00039BAA
order by c5, c6, c4
OBIEE will always use these aggregate tables if they’re available in the repository, so to enable me to test the reports with these aggregates disabled I borrowed the technique Robin introduced in his blog on testing aggregate navigation, and added a request variable prompt to the dashboard page that allows me to pass an INACTIVE_SCHEMAS value to the logical SQL queries issued for the dashboard analyses, and therefore tell the BI Server to ignore the aggregate schema and just use the detail-level BI_AIRLINES schema instead.

I therefore test the dashboard again, this time with the BI_AIRLINES_AGG schema disabled; this time, every dashboard took a while to display properly, with every analysis showing the “spinning clock” for twenty, thirty seconds a time. Comparing the response times to the ones a moment ago when aggregates were enabled, and you can see the difference.

So let’s set-up the in-memory option and see how it affects these two scenarios. The in-memory option for Oracle Database 12c 12.1.0.2.0 is installed by default as part of the core database, but doesn’t start working until you set a value for the INMEMORY_SIZE initialisation parameter – as you can see from the SQL*Plus output below, it’s currently set to zero, effectively disabling the feature:
SQL> conn / as sysdba Connected. SQL> show parameter INMEMORY NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ inmemory_clause_default string inmemory_force string DEFAULT inmemory_max_populate_servers integer 0 inmemory_query string ENABLE inmemory_size big integer 0 inmemory_trickle_repopulate_servers_ integer 1 percent optimizer_inmemory_aware boolean TRUE
The memory Oracle allocates to the in-memory option, via this initialisation parameter, comes out of the SGA and therefore before I set the INMEMORY_SIZE parameter, it’d be a good idea to increase the SGA_TARGET value to accommodate the 1G I’m then going to assign to INMEMORY_SIZE. I do both from the SQL*Plus command-prompt and then bounce the database to bring the new values into use:
SQL> alter system set inmemory_size = 1G scope=spfile; System altered. SQL> show parameter sga_target NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ sga_target big integer 6032M SQL> alter system set sga_target = 7032M scope=spfile; System altered. SQL> shutdown immediate; Database closed. Database dismounted. ORACLE instance shut down. SQL> startup ORACLE instance started. Total System Global Area 7381975040 bytes Fixed Size 2941480 bytes Variable Size 1207963096 bytes Database Buffers 5083496448 bytes Redo Buffers 13832192 bytes In-Memory Area 1073741824 bytes Database mounted. Database opened.
Now we’re at the point where we can enable the tables for in-memory access. Tables to be copied into memory can either be created like that at the start, or you can ALTER TABLE them afterwards and specify that they go into memory (or you can configure the in-memory settings at the tablespace level, or even specify particular columns or partitions to go into memory). The underlying data still gets stored row-wise on disk, but enabling a table for in-memory access tells the Oracle database to create column-store in-memory representations of the table and direct suitable queries to those copies, all the time in the background keeping the copy in-sync with the row-store base data.
I’ll start by enabling all of the BI_AIRLINES schema for in-memory access, as the biggest pay-off would be if then meant we didn’t need to maintain the aggregate tables. After running a SELECT table_name FROM user_tables to list out the table names, I then run a script to enable all the tables for in-memory access, with the in-memory copies being populated immediately:
alter table AIRCRAFT_GROUP inmemory priority high; alter table AIRCRAFT_TYPE inmemory priority high; alter table AIRLINES_USER_DATA inmemory priority high; alter table AIRLINE_ID inmemory priority high; alter table CANCELLATION inmemory priority high; alter table CARRIER_GROUP_NEW inmemory priority high; alter table CARRIER_REGION inmemory priority high; alter table DEPARBLK inmemory priority high; alter table DISTANCE_GROUP_250 inmemory priority high; alter table DOMESTIC_SEGMENT inmemory priority high; alter table OBIEE_COUNTY_HIER inmemory priority high; alter table OBIEE_GEO_AIRPORT_BRIDGE inmemory priority high; alter table OBIEE_GEO_ORIG inmemory priority high; alter table OBIEE_ROUTE inmemory priority high; alter table OBIEE_TIME_DAY_D inmemory priority high; alter table OBIEE_TIME_MTH_D inmemory priority high; alter table ONTIME_DELAY_GROUPS inmemory priority high; alter table PERFORMANCE inmemory priority high; alter table PERFORMANCE_ENDECA_MV inmemory priority high; alter table ROUTES_FOR_LINKS inmemory priority high; alter table SCHEDULES inmemory priority high; alter table SERVICE_CLASS inmemory priority high; alter table UNIQUE_CARRIERS inmemory priority high;
Looking at USER_TABLES from this schema, I can see all of the tables I selected now marked for in-memory access, for immediate loading:
SQL> @display_table_inmem_details.sql SQL> select table_name 2 , inmemory 3 , inmemory_priority 4 from user_tables 5 / TABLE_NAME INMEMORY INMEMORY -------------------- -------- -------- AIRCRAFT_GROUP ENABLED HIGH UNIQUE_CARRIERS ENABLED HIGH SERVICE_CLASS ENABLED HIGH SCHEDULES ENABLED HIGH ROUTES_FOR_LINKS ENABLED HIGH PERFORMANCE ENABLED HIGH ONTIME_DELAY_GROUPS ENABLED HIGH OBIEE_TIME_MTH_D ENABLED HIGH OBIEE_TIME_DAY_D ENABLED HIGH OBIEE_ROUTE ENABLED HIGH OBIEE_GEO_ORIG ENABLED HIGH TABLE_NAME INMEMORY INMEMORY -------------------- -------- -------- OBIEE_GEO_AIRPORT_BR ENABLED HIGH IDGE OBIEE_COUNTY_HIER ENABLED HIGH DOMESTIC_SEGMENT ENABLED HIGH DISTANCE_GROUP_250 ENABLED HIGH DEPARBLK ENABLED HIGH CARRIER_REGION ENABLED HIGH CARRIER_GROUP_NEW ENABLED HIGH CANCELLATION ENABLED HIGH AIRLINE_ID ENABLED HIGH TABLE_NAME INMEMORY INMEMORY -------------------- -------- -------- AIRLINES_USER_DATA ENABLED HIGH AIRLINES_PBLOB$ DISABLED AIRLINES_PART$ DISABLED AIRLINES_NODE_TZ$ DISABLED AIRLINES_NODE$ DISABLED AIRLINES_LINK_TZ$ DISABLED AIRLINES_LINK_SCH$ DISABLED AIRLINES_LINK$ DISABLED AIRLINES_AIRPORT_TZ$ DISABLED AIRCRAFT_TYPE ENABLED HIGH 30 rows selected.
And I can track the progress of the tables being copied into memory using the V$IM_SEGMENTS v$ view, like this:
SQL> @display_im_segments.sql
SQL> set echo on
SQL> set pages 200
SQL> col owner for a20
SQL> col name for a20
SQL> col status for a10
SQL> select v.owner
2 , v.segment_name name
3 , v.populate_status status
4 from v$im_segments v;
OWNER NAME STATUS
-------------------- -------------------- ----------
BI_AIRLINES OBIEE_COUNTY_HIER COMPLETED
BI_AIRLINES PERFORMANCE STARTED
BI_AIRLINES UNIQUE_CARRIERS COMPLETED
BI_AIRLINES AIRLINES_LINK_TZ$ COMPLETED
BI_AIRLINES OBIEE_TIME_MTH_D COMPLETED
BI_AIRLINES AIRLINES_LINK_SCH$ COMPLETED
BI_AIRLINES OBIEE_ROUTE COMPLETED
BI_AIRLINES DOMESTIC_SEGMENT COMPLETED
BI_AIRLINES AIRLINES_LINK$ COMPLETED
BI_AIRLINES AIRLINE_ID COMPLETED
BI_AIRLINES OBIEE_GEO_ORIG COMPLETED
BI_AIRLINES AIRLINES_NODE$ COMPLETED
BI_AIRLINES OBIEE_GEO_AIRPORT_BR COMPLETED
IDGE
BI_AIRLINES AIRLINES_NODE_TZ$ COMPLETED
BI_AIRLINES OBIEE_TIME_DAY_D COMPLETED
Note that most of the tables went into memory immediately, but one (PERFORMANCE) is taking a while because it’s so big. Also note that not all tables are listed in the v$ view yet, as the database hasn’t got around to adding them into memory yet, or it might choose not to populate them if it feels the memory could be used better elsewhere. You can alter the priority of these in-memory copy processes if you want, and decide whether the copying happens immediately, or when the table is first scanned (accessed).
Running the dashboards again, with the request variable prompt set to disallow the aggregate schema, gave me the response times below – the in-memory queries were much faster than the row-based non in-memory ones, but they weren’t down to the response time of the dashboards right at the start, where all data is stored row-wise but we’ve got aggregate tables to speed up the queries (note I’ve reordered the bars so the non in-memory queries with no aggregate tables are on the left of each series, as the slowest of all approaches)

Taking a look at one of the physical SQL queries for a cross-tab (hierarchical columns) analysis, you can see that in-memory table access is happening:
WITH
SAWITH0 AS (select sum(T233937.ACTUALELAPSEDTIME) as c1,
sum(T233937.ARRDELAYMINUTES) as c2,
concat(concat(T233484.AIRPORT, ' - '), substr(T233484.TR_AIRPORT_NAME , instr(T233484.TR_AIRPORT_NAME , ': ') + 2 , 50)) as c3,
T233820.D_NAME as c4,
T233820.R_NAME as c5
from
BI_AIRLINES.OBIEE_GEO_AIRPORT_BRIDGE T233484 /* 10 GEO_AIRPORT_ORIGIN */ ,
BI_AIRLINES.OBIEE_COUNTY_HIER T233820 /* 11 COUNTY_HIER_ORIGIN */ ,
BI_AIRLINES.OBIEE_TIME_MTH_D T233732 /* 41 TIME MONTH */ ,
BI_AIRLINES.PERFORMANCE T233937 /* 00 PERFORMANCE FULL */
where ( T233484.AIRPORT = T233937.ORIGIN and T233484.STCTY_FIPS = T233820.SC_CODE and T233732.Cal_Month = T233937.MONTH and T233732.Cal_Qtr = T233937.QUARTER and T233732.Cal_Year = T233937.YEAR and T233732.Cal_Month between 6 and 12 and T233937.MONTH between 6 and 12 )
group by T233820.D_NAME, T233820.R_NAME, concat(concat(T233484.AIRPORT, ' - '), substr(T233484.TR_AIRPORT_NAME , instr(T233484.TR_AIRPORT_NAME , ': ') + 2 , 50))),
SAWITH1 AS (select sum(T233609.PASSENGERS) as c1,
T233820.R_NAME as c2,
T233820.D_NAME as c3,
concat(concat(T233484.AIRPORT, ' - '), substr(T233484.TR_AIRPORT_NAME , instr(T233484.TR_AIRPORT_NAME , ': ') + 2 , 50)) as c4,
sum(T233609.PASSENGERS_MILES) as c5
from
BI_AIRLINES.OBIEE_GEO_AIRPORT_BRIDGE T233484 /* 10 GEO_AIRPORT_ORIGIN */ ,
BI_AIRLINES.OBIEE_COUNTY_HIER T233820 /* 11 COUNTY_HIER_ORIGIN */ ,
BI_AIRLINES.OBIEE_TIME_MTH_D T233732 /* 41 TIME MONTH */ ,
BI_AIRLINES.DOMESTIC_SEGMENT T233609 /* 01 DOMESTIC Segment */
where ( T233484.AIRPORT = T233609.ORIGIN and T233484.STCTY_FIPS = T233820.SC_CODE and T233609.MONTH = T233732.Cal_Month and T233609.QUARTER = T233732.Cal_Qtr and T233609.YEAR = T233732.Cal_Year and T233609.MONTH between 6 and 12 and T233732.Cal_Month between 6 and 12 )
group by T233820.D_NAME, T233820.R_NAME, concat(concat(T233484.AIRPORT, ' - '), substr(T233484.TR_AIRPORT_NAME , instr(T233484.TR_AIRPORT_NAME , ': ') + 2 , 50)))
select 2 as c1,
case when D1.c3 is not null then D1.c3 when D2.c4 is not null then D2.c4 end as c2,
case when D1.c4 is not null then D1.c4 when D2.c3 is not null then D2.c3 end as c3,
case when D1.c5 is not null then D1.c5 when D2.c2 is not null then D2.c2 end as c4,
'All Orig Airports' as c5,
1 as c6,
case when D1.c4 is not null then D1.c4 when D2.c3 is not null then D2.c3 end as c7,
case when D1.c5 is not null then D1.c5 when D2.c2 is not null then D2.c2 end as c8,
cast(D1.c2 as DOUBLE PRECISION ) / nullif( D1.c1, 0) * 100 as c9,
D2.c5 as c10,
D2.c1 as c14
from
SAWITH0 D1 full outer join SAWITH1 D2 On D1.c3 = D2.c4 and SYS_OP_MAP_NONNULL(D1.c4) = SYS_OP_MAP_NONNULL(D2.c3)
order by c4, c3, c2
SQL> @complex_query_explain.sql
Explained.
SQL> set lines 200
SQL> set pages 0
SQL> select * from table(dbms_xplan.display);
Plan hash value: 3097908901
----------------------------------------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes |TempSpc| Cost (%CPU)| Time | TQ |IN-OUT| PQ Distrib |
----------------------------------------------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 2673K| 1392M| | 112K (1)| 00:00:05 | | | |
| 1 | PX COORDINATOR | | | | | | | | | |
| 2 | PX SEND QC (ORDER) | :TQ10006 | 2673K| 1392M| | 112K (1)| 00:00:05 | Q1,06 | P->S | QC (ORDER) |
| 3 | SORT ORDER BY | | 2673K| 1392M| 1492M| 112K (1)| 00:00:05 | Q1,06 | PCWP | |
| 4 | PX RECEIVE | | 2673K| 1392M| | 26819 (1)| 00:00:02 | Q1,06 | PCWP | |
| 5 | PX SEND RANGE | :TQ10005 | 2673K| 1392M| | 26819 (1)| 00:00:02 | Q1,05 | P->P | RANGE |
| 6 | VIEW | VW_FOJ_0 | 2673K| 1392M| | 26819 (1)| 00:00:02 | Q1,05 | PCWP | |
|* 7 | HASH JOIN FULL OUTER BUFFERED | | 2673K| 1392M| | 26819 (1)| 00:00:02 | Q1,05 | PCWP | |
| 8 | PX RECEIVE | | 136 | 37128 | | 144 (7)| 00:00:01 | Q1,05 | PCWP | |
| 9 | PX SEND HASH | :TQ10003 | 136 | 37128 | | 144 (7)| 00:00:01 | Q1,03 | S->P | HASH |
| 10 | PX SELECTOR | | | | | | | Q1,03 | SCWC | |
| 11 | VIEW | | 136 | 37128 | | 144 (7)| 00:00:01 | Q1,03 | SCWC | |
| 12 | HASH GROUP BY | | 136 | 17408 | | 144 (7)| 00:00:01 | Q1,03 | SCWC | |
|* 13 | HASH JOIN | | 136 | 17408 | | 143 (6)| 00:00:01 | Q1,03 | SCWC | |
| 14 | JOIN FILTER CREATE | :BF0000 | 136 | 11288 | | 142 (6)| 00:00:01 | Q1,03 | PCWP | |
|* 15 | HASH JOIN | | 136 | 11288 | | 142 (6)| 00:00:01 | Q1,03 | SCWC | |
| 16 | JOIN FILTER CREATE | :BF0001 | 136 | 4896 | | 142 (6)| 00:00:01 | Q1,03 | PCWP | |
|* 17 | HASH JOIN | | 136 | 4896 | | 142 (6)| 00:00:01 | Q1,03 | SCWC | |
|* 18 | TABLE ACCESS INMEMORY FULL | OBIEE_TIME_MTH_D | 161 | 1610 | | 1 (0)| 00:00:01 | Q1,03 | SCWP | |
|* 19 | TABLE ACCESS INMEMORY FULL | DOMESTIC_SEGMENT | 771 | 20046 | | 141 (6)| 00:00:01 | Q1,03 | SCWP | |
| 20 | JOIN FILTER USE | :BF0001 | 1787 | 83989 | | 1 (0)| 00:00:01 | Q1,03 | PCWP | |
|* 21 | TABLE ACCESS INMEMORY FULL | OBIEE_GEO_AIRPORT_BRIDGE | 1787 | 83989 | | 1 (0)| 00:00:01 | Q1,03 | SCWP | |
| 22 | JOIN FILTER USE | :BF0000 | 3221 | 141K| | 1 (0)| 00:00:01 | Q1,03 | PCWP | |
|* 23 | TABLE ACCESS INMEMORY FULL | OBIEE_COUNTY_HIER | 3221 | 141K| | 1 (0)| 00:00:01 | Q1,03 | SCWP | |
| 24 | PX RECEIVE | | 2255K| 587M| | 26673 (1)| 00:00:02 | Q1,05 | PCWP | |
| 25 | PX SEND HASH | :TQ10004 | 2255K| 587M| | 26673 (1)| 00:00:02 | Q1,04 | P->P | HASH |
| 26 | VIEW | | 2255K| 587M| | 26673 (1)| 00:00:02 | Q1,04 | PCWP | |
| 27 | HASH GROUP BY | | 2255K| 264M| 489M| 26673 (1)| 00:00:02 | Q1,04 | PCWP | |
| 28 | PX RECEIVE | | 2255K| 264M| | 26673 (1)| 00:00:02 | Q1,04 | PCWP | |
| 29 | PX SEND HASH | :TQ10002 | 2255K| 264M| | 26673 (1)| 00:00:02 | Q1,02 | P->P | HASH |
| 30 | HASH GROUP BY | | 2255K| 264M| 489M| 26673 (1)| 00:00:02 | Q1,02 | PCWP | |
|* 31 | HASH JOIN | | 3761K| 441M| | 841 (9)| 00:00:01 | Q1,02 | PCWP | |
| 32 | PX RECEIVE | | 161 | 1610 | | 1 (0)| 00:00:01 | Q1,02 | PCWP | |
| 33 | PX SEND BROADCAST | :TQ10000 | 161 | 1610 | | 1 (0)| 00:00:01 | Q1,00 | S->P | BROADCAST |
| 34 | PX SELECTOR | | | | | | | Q1,00 | SCWC | |
|* 35 | TABLE ACCESS INMEMORY FULL | OBIEE_TIME_MTH_D | 161 | 1610 | | 1 (0)| 00:00:01 | Q1,00 | SCWP | |
|* 36 | HASH JOIN | | 3773K| 406M| | 838 (9)| 00:00:01 | Q1,02 | PCWP | |
| 37 | PX RECEIVE | | 1787 | 160K| | 2 (0)| 00:00:01 | Q1,02 | PCWP | |
| 38 | PX SEND BROADCAST | :TQ10001 | 1787 | 160K| | 2 (0)| 00:00:01 | Q1,01 | S->P | BROADCAST |
| 39 | PX SELECTOR | | | | | | | Q1,01 | SCWC | |
|* 40 | HASH JOIN | | 1787 | 160K| | 2 (0)| 00:00:01 | Q1,01 | SCWC | |
| 41 | TABLE ACCESS INMEMORY FULL| OBIEE_GEO_AIRPORT_BRIDGE | 1787 | 83989 | | 1 (0)| 00:00:01 | Q1,01 | SCWP | |
| 42 | TABLE ACCESS INMEMORY FULL| OBIEE_COUNTY_HIER | 3221 | 141K| | 1 (0)| 00:00:01 | Q1,01 | SCWP | |
| 43 | PX BLOCK ITERATOR | | 3773K| 75M| | 834 (9)| 00:00:01 | Q1,02 | PCWC | |
|* 44 | TABLE ACCESS INMEMORY FULL | PERFORMANCE | 3773K| 75M| | 834 (9)| 00:00:01 | Q1,02 | PCWP | |
----------------------------------------------------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
7 - access("D1"."C3"="D2"."C4" AND SYS_OP_MAP_NONNULL("D1"."C4")=SYS_OP_MAP_NONNULL("D2"."C3"))
13 - access("T233484"."STCTY_FIPS"="T233820"."SC_CODE")
15 - access("T233484"."AIRPORT"="T233609"."ORIGIN")
17 - access("T233732"."CAL_MONTH"=TO_NUMBER("T233609"."MONTH") AND "T233732"."CAL_QTR"=TO_NUMBER("T233609"."QUARTER") AND
"T233732"."CAL_YEAR"=TO_NUMBER("T233609"."YEAR"))
18 - inmemory("T233732"."CAL_MONTH">=6 AND "T233732"."CAL_MONTH"<=12)
filter("T233732"."CAL_MONTH">=6 AND "T233732"."CAL_MONTH"<=12)
19 - inmemory(TO_NUMBER("T233609"."MONTH")>=6 AND TO_NUMBER("T233609"."MONTH")<=12)
filter(TO_NUMBER("T233609"."MONTH")>=6 AND TO_NUMBER("T233609"."MONTH")<=12)
21 - inmemory(SYS_OP_BLOOM_FILTER(:BF0001,"T233484"."AIRPORT"))
filter(SYS_OP_BLOOM_FILTER(:BF0001,"T233484"."AIRPORT"))
23 - inmemory(SYS_OP_BLOOM_FILTER(:BF0000,"T233820"."SC_CODE"))
filter(SYS_OP_BLOOM_FILTER(:BF0000,"T233820"."SC_CODE"))
31 - access("T233732"."CAL_MONTH"="T233937"."MONTH" AND "T233732"."CAL_QTR"="T233937"."QUARTER" AND "T233732"."CAL_YEAR"="T233937"."YEAR")
35 - inmemory("T233732"."CAL_MONTH">=6 AND "T233732"."CAL_MONTH"<=12)
filter("T233732"."CAL_MONTH">=6 AND "T233732"."CAL_MONTH"<=12)
36 - access("T233484"."AIRPORT"="T233937"."ORIGIN")
40 - access("T233484"."STCTY_FIPS"="T233820"."SC_CODE")
44 - inmemory("T233937"."MONTH">=6 AND "T233937"."MONTH"<=12)
filter("T233937"."MONTH">=6 AND "T233937"."MONTH"<=12)
Note
-----
- dynamic statistics used: dynamic sampling (level=AUTO)
- Degree of Parallelism is 2 because of table property
80 rows selected.
Indeed, looking at the queries the BI Server is sending to the database it’s not too surprising the in-memory difference in this case wasn’t too dramatic. According to the docs (emphasis mine):
“Storing a database object in the IM column store can improve performance significantly for the following types of operations performed on the database object
- A query that scans a large number of rows and applies filters that use operators such as the following: =, <, >, and IN
- A query that selects a small number of columns from a table or materialized view with a large number of columns, such as a query that selects five columns from a table with 100 columns
- A query that joins a small table to a large table
- A query that aggregates data
The IM column store does not improve performance for the following types of operations:
- Queries with complex predicates
- Queries that select a large number of columns
- Queries that return a large number of rows
- Queries with multiple large table joins”
and our query certainly has complex predicates, returns a fair few rows, has large and lots of joins etc. Taking a more simple query that you’d likely write yourself if querying a data warehouse, you can see the in-memory table access being used again but a much simpler, an cheaper explain plan:
SQL> @inmem_explain.sql
SQL> set echo on
SQL> explain plan for
2 select /*+ INMEMORY */ sum(T233937.ACTUALELAPSEDTIME) as c1,
3 sum(T233937.WEATHERDELAY) as c2,
4 sum(T233937.SECURITYDELAY) as c3,
5 sum(T233937.NASDELAY) as c4,
6 sum(T233937.LATEAIRCRAFTDELAY) as c5,
7 sum(T233937.ARRDELAYMINUTES) as c6,
8 sum(T233937.CARRIERDELAY) as c7,
9 sum(nvl(casewhen T233937.CANCELLED < 1 then T233937.FLIGHTS end , 0)) as c8,
10 T233820.D_NAME as c9
11 from
12 BI_AIRLINES.OBIEE_GEO_AIRPORT_BRIDGE T233484 /* 10 GEO_AIRPORT_ORIGIN */ ,
13 BI_AIRLINES.OBIEE_COUNTY_HIER T233820 /* 11 COUNTY_HIER_ORIGIN */ ,
14 BI_AIRLINES.OBIEE_GEO_AIRPORT_BRIDGE T233497 /* 12 GEO_AIPORT_DEST */ ,
15 BI_AIRLINES.OBIEE_COUNTY_HIER T233831 /* 13 COUNTY_HIER_DEST */ ,
16 BI_AIRLINES.OBIEE_TIME_MTH_D T233732 /* 41 TIME MONTH */ ,
17 BI_AIRLINES.DISTANCE_GROUP_250 T233594 /* 19 DISTANCE_GROUP_250 */ ,
18 BI_AIRLINES.PERFORMANCE T233937 /* 00 PERFORMANCE FULL */
19 where ( T233484.AIRPORT = T233937.ORIGIN and T233484.STCTY_FIPS = T233820.SC_CODE and T233497.AIRPORT = T233937.DEST and T233497.STCTY_FIPS = T233831.SC_CODE and T233594.DESCRIPTION = '1000-1249 Miles' and T233594.CODE = T233937.DISTANCEGROUP and T233732.Cal_Month = T233937.MONTH and T233732.Cal_Qtr = T233937.QUARTER and T233732.Cal_Year = T233937.YEAR and T233831.R_NAME = 'Northeast Region' and T233732.Cal_Month between 6 and 12 and T233937.MONTH between 6 and 12 )
20 group by T233820.D_NAME
21 order by c9
22 /
Explained.
SQL> set lines 300
SQL> set pages 0
SQL> select * from table(dbms_xplan.display);
Plan hash value: 3055743864
-----------------------------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | TQ |IN-OUT| PQ Distrib |
-----------------------------------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 9 | 1314 | 883 (13)| 00:00:01 | | | |
| 1 | PX COORDINATOR | | | | | | | | |
| 2 | PX SEND QC (ORDER) | :TQ10006 | 9 | 1314 | 883 (13)| 00:00:01 | Q1,06 | P->S | QC (ORDER) |
| 3 | SORT GROUP BY | | 9 | 1314 | 883 (13)| 00:00:01 | Q1,06 | PCWP | |
| 4 | PX RECEIVE | | 9 | 1314 | 883 (13)| 00:00:01 | Q1,06 | PCWP | |
| 5 | PX SEND RANGE | :TQ10005 | 9 | 1314 | 883 (13)| 00:00:01 | Q1,05 | P->P | RANGE |
| 6 | HASH GROUP BY | | 9 | 1314 | 883 (13)| 00:00:01 | Q1,05 | PCWP | |
|* 7 | HASH JOIN | | 60775 | 8665K| 882 (13)| 00:00:01 | Q1,05 | PCWP | |
| 8 | PX RECEIVE | | 3221 | 99851 | 1 (0)| 00:00:01 | Q1,05 | PCWP | |
| 9 | PX SEND BROADCAST | :TQ10000 | 3221 | 99851 | 1 (0)| 00:00:01 | Q1,00 | S->P | BROADCAST |
| 10 | PX SELECTOR | | | | | | Q1,00 | SCWC | |
| 11 | TABLE ACCESS INMEMORY FULL | OBIEE_COUNTY_HIER | 3221 | 99851 | 1 (0)| 00:00:01 | Q1,00 | SCWP | |
|* 12 | HASH JOIN | | 60775 | 6825K| 881 (13)| 00:00:01 | Q1,05 | PCWP | |
| 13 | PX RECEIVE | | 1787 | 17870 | 1 (0)| 00:00:01 | Q1,05 | PCWP | |
| 14 | PX SEND BROADCAST | :TQ10001 | 1787 | 17870 | 1 (0)| 00:00:01 | Q1,01 | S->P | BROADCAST |
| 15 | PX SELECTOR | | | | | | Q1,01 | SCWC | |
| 16 | TABLE ACCESS INMEMORY FULL | OBIEE_GEO_AIRPORT_BRIDGE | 1787 | 17870 | 1 (0)| 00:00:01 | Q1,01 | SCWP | |
|* 17 | HASH JOIN | | 60775 | 6231K| 880 (13)| 00:00:01 | Q1,05 | PCWP | |
| 18 | PX RECEIVE | | 161 | 1610 | 1 (0)| 00:00:01 | Q1,05 | PCWP | |
| 19 | PX SEND BROADCAST | :TQ10002 | 161 | 1610 | 1 (0)| 00:00:01 | Q1,02 | S->P | BROADCAST |
| 20 | PX SELECTOR | | | | | | Q1,02 | SCWC | |
|* 21 | TABLE ACCESS INMEMORY FULL | OBIEE_TIME_MTH_D | 161 | 1610 | 1 (0)| 00:00:01 | Q1,02 | SCWP | |
|* 22 | HASH JOIN | | 60964 | 5655K| 879 (13)| 00:00:01 | Q1,05 | PCWP | |
| 23 | JOIN FILTER CREATE | :BF0000 | 1 | 19 | 1 (0)| 00:00:01 | Q1,05 | PCWP | |
| 24 | PX RECEIVE | | 1 | 19 | 1 (0)| 00:00:01 | Q1,05 | PCWP | |
| 25 | PX SEND BROADCAST | :TQ10003 | 1 | 19 | 1 (0)| 00:00:01 | Q1,03 | S->P | BROADCAST |
| 26 | PX SELECTOR | | | | | | Q1,03 | SCWC | |
|* 27 | TABLE ACCESS INMEMORY FULL | DISTANCE_GROUP_250 | 1 | 19 | 1 (0)| 00:00:01 | Q1,03 | SCWP | |
|* 28 | HASH JOIN | | 670K| 48M| 878 (13)| 00:00:01 | Q1,05 | PCWP | |
| 29 | JOIN FILTER CREATE | :BF0001 | 318 | 9540 | 2 (0)| 00:00:01 | Q1,05 | PCWP | |
| 30 | PX RECEIVE | | 318 | 9540 | 2 (0)| 00:00:01 | Q1,05 | PCWP | |
| 31 | PX SEND BROADCAST | :TQ10004 | 318 | 9540 | 2 (0)| 00:00:01 | Q1,04 | S->P | BROADCAST |
| 32 | PX SELECTOR | | | | | | Q1,04 | SCWC | |
|* 33 | HASH JOIN | | 318 | 9540 | 2 (0)| 00:00:01 | Q1,04 | SCWC | |
| 34 | JOIN FILTER CREATE | :BF0002 | 217 | 4340 | 1 (0)| 00:00:01 | Q1,04 | PCWP | |
|* 35 | TABLE ACCESS INMEMORY FULL| OBIEE_COUNTY_HIER | 217 | 4340 | 1 (0)| 00:00:01 | Q1,04 | SCWP | |
| 36 | JOIN FILTER USE | :BF0002 | 1787 | 17870 | 1 (0)| 00:00:01 | Q1,04 | PCWP | |
|* 37 | TABLE ACCESS INMEMORY FULL| OBIEE_GEO_AIRPORT_BRIDGE | 1787 | 17870 | 1 (0)| 00:00:01 | Q1,04 | SCWP | |
| 38 | JOIN FILTER USE | :BF0000 | 3773K| 165M| 874 (13)| 00:00:01 | Q1,05 | PCWP | |
| 39 | JOIN FILTER USE | :BF0001 | 3773K| 165M| 874 (13)| 00:00:01 | Q1,05 | PCWP | |
| 40 | PX BLOCK ITERATOR | | 3773K| 165M| 874 (13)| 00:00:01 | Q1,05 | PCWC | |
|* 41 | TABLE ACCESS INMEMORY FULL | PERFORMANCE | 3773K| 165M| 874 (13)| 00:00:01 | Q1,05 | PCWP | |
-----------------------------------------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
7 - access("T233484"."STCTY_FIPS"="T233820"."SC_CODE")
12 - access("T233484"."AIRPORT"="T233937"."ORIGIN")
17 - access("T233732"."CAL_MONTH"="T233937"."MONTH" AND "T233732"."CAL_QTR"="T233937"."QUARTER" AND "T233732"."CAL_YEAR"="T233937"."YEAR")
21 - inmemory("T233732"."CAL_MONTH">=6 AND "T233732"."CAL_MONTH"<=12)
filter("T233732"."CAL_MONTH">=6 AND "T233732"."CAL_MONTH"<=12)
22 - access("T233594"."CODE"="T233937"."DISTANCEGROUP")
27 - inmemory("T233594"."DESCRIPTION"='1000-1249 Miles')
filter("T233594"."DESCRIPTION"='1000-1249 Miles')
28 - access("T233497"."AIRPORT"="T233937"."DEST")
33 - access("T233497"."STCTY_FIPS"="T233831"."SC_CODE")
35 - inmemory("T233831"."R_NAME"='Northeast Region')
filter("T233831"."R_NAME"='Northeast Region')
37 - inmemory(SYS_OP_BLOOM_FILTER(:BF0002,"T233497"."STCTY_FIPS"))
filter(SYS_OP_BLOOM_FILTER(:BF0002,"T233497"."STCTY_FIPS"))
41 - inmemory("T233937"."MONTH">=6 AND "T233937"."MONTH"<=12 AND SYS_OP_BLOOM_FILTER_LIST(SYS_OP_BLOOM_FILTER(:BF0001,"T233937"."DEST"),SYS
_OP_BLOOM_FILTER(:BF0000,"T233937"."DISTANCEGROUP")))
filter("T233937"."MONTH">=6 AND "T233937"."MONTH"<=12 AND SYS_OP_BLOOM_FILTER_LIST(SYS_OP_BLOOM_FILTER(:BF0001,"T233937"."DEST"),SYS_O
P_BLOOM_FILTER(:BF0000,"T233937"."DISTANCEGROUP")))
Note
-----
- dynamic statistics used: dynamic sampling (level=AUTO)
- Degree of Parallelism is 2 because of table property
75 rows selected.
If I then turn-off the in-memory feature and regenerate the execution plan, you can see without in-memory the plan is around 5x as expensive:
SQL> alter system set INMEMORY_SIZE = 0 scope = spfile;
System altered.
SQL> shutdown immediate;
ORA-01097: cannot shutdown while in a transaction - commit or rollback first
SQL> rollback;
Rollback complete.
SQL> shutdown immediate;
Database closed.
Database dismounted.
ORACLE instance shut down.
SQL> startup
ORACLE instance started.
Total System Global Area 7398752256 bytes
Fixed Size 2941528 bytes
Variable Size 1056968104 bytes
Database Buffers 6325010432 bytes
Redo Buffers 13832192 bytes
Database mounted.
Database opened.
SQL> @noinmem_explain.sql
Explained.
SQL> set lines 300
SQL> set pages 0
SQL> select * from table(dbms_xplan.display);
Plan hash value: 2990499928
--------------------------------------------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | TQ |IN-OUT| PQ Distrib |
--------------------------------------------------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 9 | 1341 | 4086 (1)| 00:00:01 | | | |
| 1 | TEMP TABLE TRANSFORMATION | | | | | | | | |
| 2 | LOAD AS SELECT | SYS_TEMP_0FD9D6605_275335 | | | | | | | |
|* 3 | HASH JOIN | | 318 | 9540 | 22 (0)| 00:00:01 | | | |
|* 4 | TABLE ACCESS FULL | OBIEE_COUNTY_HIER | 217 | 4340 | 13 (0)| 00:00:01 | | | |
| 5 | TABLE ACCESS FULL | OBIEE_GEO_AIRPORT_BRIDGE | 1787 | 17870 | 9 (0)| 00:00:01 | | | |
| 6 | PX COORDINATOR | | | | | | | | |
| 7 | PX SEND QC (ORDER) | :TQ10008 | 9 | 1341 | 4086 (1)| 00:00:01 | Q1,08 | P->S | QC (ORDER) |
| 8 | SORT GROUP BY | | 9 | 1341 | 4086 (1)| 00:00:01 | Q1,08 | PCWP | |
| 9 | PX RECEIVE | | 9 | 1341 | 4086 (1)| 00:00:01 | Q1,08 | PCWP | |
| 10 | PX SEND RANGE | :TQ10007 | 9 | 1341 | 4086 (1)| 00:00:01 | Q1,07 | P->P | RANGE |
| 11 | HASH GROUP BY | | 9 | 1341 | 4086 (1)| 00:00:01 | Q1,07 | PCWP | |
|* 12 | HASH JOIN | | 281 | 41869 | 4085 (1)| 00:00:01 | Q1,07 | PCWP | |
| 13 | PX RECEIVE | | 281 | 33158 | 4072 (1)| 00:00:01 | Q1,07 | PCWP | |
| 14 | PX SEND HYBRID HASH | :TQ10005 | 281 | 33158 | 4072 (1)| 00:00:01 | Q1,05 | P->P | HYBRID HASH|
| 15 | STATISTICS COLLECTOR | | | | | | Q1,05 | PCWC | |
|* 16 | HASH JOIN BUFFERED | | 281 | 33158 | 4072 (1)| 00:00:01 | Q1,05 | PCWP | |
| 17 | VIEW | VW_GBC_29 | 281 | 30348 | 4063 (1)| 00:00:01 | Q1,05 | PCWP | |
| 18 | HASH GROUP BY | | 281 | 79523 | 4041 (1)| 00:00:01 | Q1,05 | PCWP | |
| 19 | PX RECEIVE | | 281 | 79523 | 4041 (1)| 00:00:01 | Q1,05 | PCWP | |
| 20 | PX SEND HASH | :TQ10003 | 281 | 79523 | 4041 (1)| 00:00:01 | Q1,03 | P->P | HASH |
| 21 | HASH GROUP BY | | 281 | 79523 | 4041 (1)| 00:00:01 | Q1,03 | PCWP | |
|* 22 | HASH JOIN | | 60853 | 16M| 4039 (1)| 00:00:01 | Q1,03 | PCWP | |
| 23 | BUFFER SORT | | | | | | Q1,03 | PCWC | |
| 24 | PX RECEIVE | | 318 | 1272 | 2 (0)| 00:00:01 | Q1,03 | PCWP | |
| 25 | PX SEND BROADCAST | :TQ10000 | 318 | 1272 | 2 (0)| 00:00:01 | | S->P | BROADCAST |
| 26 | TABLE ACCESS FULL | SYS_TEMP_0FD9D6605_275335 | 318 | 1272 | 2 (0)| 00:00:01 | | | |
|* 27 | HASH JOIN | | 60853 | 16M| 4037 (1)| 00:00:01 | Q1,03 | PCWP | |
| 28 | PX RECEIVE | | 160 | 4640 | 4 (0)| 00:00:01 | Q1,03 | PCWP | |
| 29 | PX SEND BROADCAST | :TQ10002 | 160 | 4640 | 4 (0)| 00:00:01 | Q1,02 | S->P | BROADCAST |
| 30 | PX SELECTOR | | | | | | Q1,02 | SCWC | |
| 31 | MERGE JOIN CARTESIAN | | 160 | 4640 | 4 (0)| 00:00:01 | Q1,02 | SCWC | |
|* 32 | VIEW | index$_join$_006 | 1 | 19 | 2 (0)| 00:00:01 | Q1,02 | SCWC | |
|* 33 | HASH JOIN | | | | | | Q1,02 | SCWC | |
| 34 | BITMAP CONVERSION TO ROWIDS | | 1 | 19 | 1 (0)| 00:00:01 | Q1,02 | SCWC | |
|* 35 | BITMAP INDEX SINGLE VALUE | M_INDEX32 | | | | | Q1,02 | SCWP | |
| 36 | BITMAP CONVERSION TO ROWIDS | | 1 | 19 | 1 (0)| 00:00:01 | Q1,02 | SCWC | |
| 37 | BITMAP INDEX FULL SCAN | INDEX4 | | | | | Q1,02 | SCWP | |
| 38 | BUFFER SORT | | 161 | 1610 | 2 (0)| 00:00:01 | Q1,02 | SCWC | |
| 39 | BITMAP CONVERSION TO ROWIDS | | 161 | 1610 | 2 (0)| 00:00:01 | Q1,02 | SCWC | |
|* 40 | BITMAP INDEX FAST FULL SCAN | M_INDEX28 | | | | | Q1,02 | SCWP | |
|* 41 | VIEW | VW_ST_167D3604 | 61043 | 14M| 4033 (1)| 00:00:01 | Q1,03 | PCWP | |
| 42 | NESTED LOOPS | | 61043 | 4768K| 4029 (1)| 00:00:01 | Q1,03 | PCWP | |
| 43 | BUFFER SORT | | | | | | Q1,03 | PCWC | |
| 44 | PX RECEIVE | | | | | | Q1,03 | PCWP | |
| 45 | PX SEND HASH (BLOCK ADDRESS) | :TQ10001 | | | | | | S->P | HASH (BLOCK|
| 46 | BITMAP CONVERSION TO ROWIDS | | 61042 | 1311K| 365 (1)| 00:00:01 | | | |
| 47 | BITMAP AND | | | | | | | | |
| 48 | BITMAP MERGE | | | | | | | | |
| 49 | BITMAP KEY ITERATION | | | | | | | | |
|* 50 | VIEW | index$_join$_255 | 1 | 19 | 2 (0)| 00:00:01 | | | |
|* 51 | HASH JOIN | | | | | | | | |
| 52 | BITMAP CONVERSION TO ROWIDS| | 1 | 19 | 1 (0)| 00:00:01 | | | |
|* 53 | BITMAP INDEX SINGLE VALUE | M_INDEX32 | | | | | | | |
| 54 | BITMAP CONVERSION TO ROWIDS| | 1 | 19 | 1 (0)| 00:00:01 | | | |
| 55 | BITMAP INDEX FULL SCAN | INDEX4 | | | | | | | |
|* 56 | BITMAP INDEX RANGE SCAN | PERF_DISTANCEGRP | | | | | | | |
| 57 | BITMAP MERGE | | | | | | | | |
| 58 | BITMAP KEY ITERATION | | | | | | | | |
| 59 | TABLE ACCESS FULL | SYS_TEMP_0FD9D6605_275335 | 318 | 1272 | 2 (0)| 00:00:01 | | | |
|* 60 | BITMAP INDEX RANGE SCAN | PERF_DEST | | | | | | | |
| 61 | BITMAP MERGE | | | | | | | | |
|* 62 | BITMAP INDEX RANGE SCAN | PERF_MONTH | | | | | | | |
| 63 | TABLE ACCESS BY USER ROWID | PERFORMANCE | 1 | 58 | 3669 (1)| 00:00:01 | Q1,03 | PCWP | |
| 64 | PX RECEIVE | | 1787 | 17870 | 9 (0)| 00:00:01 | Q1,05 | PCWP | |
| 65 | PX SEND BROADCAST | :TQ10004 | 1787 | 17870 | 9 (0)| 00:00:01 | Q1,04 | S->P | BROADCAST |
| 66 | PX SELECTOR | | | | | | Q1,04 | SCWC | |
| 67 | TABLE ACCESS FULL | OBIEE_GEO_AIRPORT_BRIDGE | 1787 | 17870 | 9 (0)| 00:00:01 | Q1,04 | SCWP | |
| 68 | PX RECEIVE | | 3221 | 99851 | 13 (0)| 00:00:01 | Q1,07 | PCWP | |
| 69 | PX SEND HYBRID HASH | :TQ10006 | 3221 | 99851 | 13 (0)| 00:00:01 | Q1,06 | S->P | HYBRID HASH|
| 70 | PX SELECTOR | | | | | | Q1,06 | SCWC | |
| 71 | TABLE ACCESS FULL | OBIEE_COUNTY_HIER | 3221 | 99851 | 13 (0)| 00:00:01 | Q1,06 | SCWP | |
--------------------------------------------------------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("T233497"."STCTY_FIPS"="T233831"."SC_CODE")
4 - filter("T233831"."R_NAME"='Northeast Region')
12 - access("T233484"."STCTY_FIPS"="T233820"."SC_CODE")
16 - access("T233484"."AIRPORT"="ITEM_1")
22 - access("C0"="ITEM_1")
27 - access("T233732"."CAL_YEAR"="ITEM_5" AND "T233732"."CAL_QTR"="ITEM_4" AND "T233732"."CAL_MONTH"="ITEM_3" AND "T233594"."CODE"="ITEM_2")
32 - filter("T233594"."DESCRIPTION"='1000-1249 Miles')
33 - access(ROWID=ROWID)
35 - access("T233594"."DESCRIPTION"='1000-1249 Miles')
40 - filter("T233732"."CAL_MONTH">=6 AND "T233732"."CAL_MONTH"<=12)
41 - filter("ITEM_3"<=12 AND "ITEM_3">=6)
50 - filter("T233594"."DESCRIPTION"='1000-1249 Miles')
51 - access(ROWID=ROWID)
53 - access("T233594"."DESCRIPTION"='1000-1249 Miles')
56 - access("T233937"."DISTANCEGROUP"="T233594"."CODE")
60 - access("T233937"."DEST"="C0")
62 - access("T233937"."MONTH">=6 AND "T233937"."MONTH"<=12)
Note
-----
- dynamic statistics used: dynamic sampling (level=AUTO)
- Degree of Parallelism is 2 because of table property
- star transformation used for this statement
105 rows selected.
Running the actual queries in this case gives me a wall-time of around 4 seconds for the in-memory version, and 14 seconds when in-memory query is disabled … but the response time isn’t anywhere near the initial run where we had data stored row-wise but with aggregate tables, so let’s finish-off the testing by putting the aggregate table in-memory too, and see if that makes a difference.
And of course, it absolutely flew:

So to conclude from my look at the Oracle Database 12c In-Memory option with OBIEE11g v406 SampleApp, I’d say the following based on my initial tests:
- For BI-type reporting where you’re typically summarising lots of data, the in-memory option doesn’t remove the need for aggregate tables – you’ll still benefit significantly from having them, in my observation
- Where the in-memory option does benefit you is when you’re querying the detail-level data – it helps with aggregation but it’s main strength is fast filtering against subsets of columns
- Some of the more complex SQL queries issued by OBIEE’s BI Server, for example when creating lots of subtotals and totals against a dataset, reduce the effectiveness of the in-memory option – you’ll get the biggest speed improvement, at least at the moment, with queries with simpler predicates and not so complex joins
There might be more to the aggregation story in the end, though. Looking at the Oracle Database 12c In-Memory Option Technical White Paper, the in-memory option should in-fact help with aggregation through a new optimiser transformation called “vector group by”, a transformation that’s likened to a star transformation that uses CPU-efficient algorithms and a multi-dimensional array created on-the-fly in the PGA called an “in-memory accumulator”.

In fact, what we’ve heard is that many of the old Oracle OLAP team have moved over to the in-memory option team and were responsible for this feature, so I’ll be taking a closer look at in-memory aggregation in this new feature over the next few months. In my examples though, I didn’t see any examples of vector group by in the query execution plans, so I’m assuming either conditions weren’t right for it, or like star transformations there’s some combination of setting and query factors that need to be in place before it’ll appear in the execution plan (and queries presumably run that much faster).
For now though – that’s my first run-through of the 12c In-Memory Option in the context of a typical BI workload. Check back later in the year for more in-memory option postings, including hopefully something more on the in-memory aggregation feature.
Rittman Mead Featured in Oracle In-Memory Option Launch
Today saw the official launch of the Oracle Database In-Memory Option, with Larry Ellison going through the product features and then reading out some quotes and testimonials from beta testers. Rittman Mead were part of the beta testing program, with several of our team testing out various scenarios where we ETL’d into it, used it with OBIEE and worked out what would be involved in “in-memory-enabling” some of our customer’s BI systems.
In fact, as we said in our quote for the launch, enabling Oracle Database for in-memory analysis was almost “boringly simple” – just enable the option, choose your tables, drop any OLTP indexes and you’re ready to go.

Of course, in practice you’ll need to think about which tables you’ll put into memory if RAM is limited, in some scenarios TimesTen might be a better option, and you’ll need to test your particular system and carefully consider whether you’ll keep particular indexes or materialised views, but we’re really excited about the In-Memory Option for Oracle Database as it’s got the potential to significantly improve query response times for users – and from what we’ve seen so far, it “just works”.
We’re still in the NDA period whilst beta testing goes on, but you can read more on the In-Memory Option on the Oracle website, and on the blog post I wrote when the feature was announced last Openworld. Once it goes GA look out for some in-depth articles on the blog around how it works, and details on how we’ll be able to help customers take advantage of this significant new Oracle Database feature.

