Tag Archives: Oracle Database
4 Methods for Migrating Oracle Databases to Microsoft Azure
When you migrate an Oracle database to Microsoft Azure’s cloud services, you need to choose the most suitable method for the task. The right option for your database migration project varies based on your available technical resources, the complexity of your infrastructure, and your intended use cases.
Cross-Cloud Connectivity
You have a relatively easy migration ahead of you if you already use Oracle Cloud Infrastructure. Microsoft Azure provides cross-cloud connectivity, so your Oracle databases connect directly to the Azure service. This method is not a true migration, as the data remains on Oracle Cloud Infrastructure. If you’re trying to move away from Oracle’s cloud services or don’t want a multi-cloud deployment, then this would not be an ideal choice.
Lift and Shift
A lift and shift migration uses an approach that minimizes downtime potential for your organization. While Microsoft Azure lacks a dedicated Oracle database service in its cloud, you can configure Azure VM to accommodate your databases. You use Azure’s built-in migration tools to migrate your on-premises Oracle databases to the VM seamlessly.
You avoid a significant amount of downtime by configuring the Azure VM and shifting the data over to it before the cutover occurs. While you do have to temporarily pay for running two sets of databases, this approach gives you sufficient time to go through testing and work out any issues.
Database Refactoring
Legacy on-premises Oracle databases may have configurations that are poorly suited to cloud features. While you could lift and shift them as-is to Azure VM, you would end up with a wide range of issues that could result in data loss and unplanned downtime.
In this Oracle migration scenario, refactoring the code before you go through the migration may be the best option. You do have to commit significant time and resources to this project, but you end up with a modernized Oracle database that can take full advantage of the scale, performance, and agility offered by a cloud-based environment.
Database Rearchitecting
Sometimes your Oracle database technology may not be serving your current needs and use cases. Instead of migrating the databases, you can completely rearchitect your database environment. Since database needs can change significantly over the course of an organization’s lifespan, evaluating whether Oracle is the right option to take you into the cloud is important.
Learn more about what your organization needs to do before the migration with our white paper, “Getting Your Organization Ready for Your Oracle Database to Microsoft Azure Migration.”
The post 4 Methods for Migrating Oracle Databases to Microsoft Azure appeared first on Datavail.
Oracle to Amazon RDS Migration Best Practices
An Oracle to Amazon RDS migration is an extensive process that requires significant resources. Thoroughly planning each step ahead of time and gathering the right information to answer critical migration questions sets your organization up for success.
Evaluate Your On-Premises Oracle Database Performance
Many organizations opt to migrate databases to the cloud to improve overall performance, but you need a way to evaluate how much of a boost it brings. You need to gather a variety of data on your current Oracle performance under different conditions to make a fair comparison to Amazon RDS. Keep an eye on your high and low usage numbers, performance bottlenecks, storage requirements, and other metrics.
This information is also important for choosing the right scale of services for your Oracle databases. You don’t want to be significantly under- or over-provisioned following your migration. While scaling your resources is not difficult in the cloud, it adds extra work on top of an already complex process.
Visit Your Disaster Recovery Strategy
Disaster recovery processes for on-premises Oracle databases may use drastically different solutions than the cloud. Explore the potential changes that may need to occur in your disaster recovery technology, procedures, and policies to account for the post-migration environment.
Study Your Workload Security Requirements
How are you currently protecting your Oracle databases on-premises? How much of your data is categorized as sensitive information or otherwise subject to data regulations? What are the biggest threats facing your database workloads currently?
Answering these questions gives you greater clarity into the security measures that would benefit your databases the most in Amazon RDS. AWS offers a robust set of security features that often exceed what organizations have available on-premises, especially for smaller businesses.
Identify Current Database Points of Failure
What scenarios could result in database downtime or loss with your on-premises Oracle databases? You may be able to completely eliminate these points of failure following an Amazon RDS migration. For example, if you have all of your servers in the same data center, a local outage could cause unplanned downtime for all your systems. A cloud-based infrastructure gives you greater flexibility for distributing your databases in different locations.
Understand the Oracle to Amazon RDS Migration Risks Ahead of Time
Data migrations may fail, especially for organizations that lack technical specialists with experience in this area. Cover potential failure scenarios to see whether you can plan around these issues, or minimize the impact so the project can continue.
Get more details about the Oracle to Amazon RDS migration process. Download our white paper “Why You Should Consider an Oracle to Amazon RDS Migration.”
The post Oracle to Amazon RDS Migration Best Practices appeared first on Datavail.
Things to Consider for an On-Premises Oracle to Amazon RDS Migration
Are you considering moving your on-premises Oracle databases to Amazon RDS? Before you undertake this transformative change, you’ll want to make sure that it’s the right decision for your organization. Here are the most important factors to keep in mind.
Oracle Database Version and Licenses
Check the list of supported Oracle database versions of Amazon RDS to ensure that the service supports your on-premises deployments. If your Oracle version is older, you may need to upgrade your databases before you can move ahead with the Amazon RDS migration. You also need to look at the Oracle licensing options to see whether you need to change licenses, bring your own license to AWS, or use a solution that includes it.
Control of the Underlying Infrastructure
Moving to Amazon RDS means that your organization is giving up control of the underlying database hardware and much of the software. You may not want to cede that much control to an external partner, especially when you’re used to running Oracle on-premises.
Data Regulations
What data regulations are you subject to? If you have restrictive requirements to work around, you’ll need to ensure that Amazon RDS is compliant with the requested measures. Your sensitive data may have special security requirements or need to stay within a particular region.
AWS Regions
The latency between your systems, your users, and the AWS data centers is another important Oracle to Amazon RDS migration consideration. With on-premises Oracle deployments, your internal systems use your own network to deliver low-latency access to your data. When you move your databases to the cloud, you switch to using internet connectivity, which may change the performance.
Full or Partial Cloud Migration
Do you want, or need, to take a 100% cloud approach for your on-premises Oracle databases? A hybrid model offers greater flexibility and allows you to separate out data that is sensitive or under regulatory requirements.
Pricing Model
Amazon RDS has two pricing models: pay-as-you-go, and reserved instances. The right option for your IT budget depends on how predictable your Oracle database workloads are and how much flexibility you want. Pay-as-you-go is a no-contract option that charges based on your resource usage. Reserved instances offer a year or longer contract that allocates a specific amount of Amazon RDS resources. This option is less expensive than pay-as-you-go, but it’s not always a feasible choice if you have highly variable workloads.
Want to learn more about the pros and cons of migrating to Amazon RDS? Download our white paper: Why You Should Consider an Oracle to Amazon RDS Migration.
The post Things to Consider for an On-Premises Oracle to Amazon RDS Migration appeared first on Datavail.
Kerberos Authentication with Oracle Databases
In an effort to simplify Oracle database authentication, Kerberos will be installed and configured to authenticate user’s password against Microsoft AD. This will allow users to maintain only one password for AD and Oracle databases.
There are several parts to the configuration; MS AD, Unix and Oracle Database. This document will consolidate all the parts into one document for a consistent installation across all the database servers.
Microsoft AD
Create a user with the samaccountname that matches the short name. The cn, displayname, givenname and name attributes must match FQDN.
The following was run from PDC emulator (Should be able to use any DC). The password was a generated, complex password.
$Pass=”…….”
ktpass.exe -princ <userPrincipalName> -mapuser <cn> -crypto all -pass $pass -out C:\temp\krb5.keypass
The pertinent user attributes are below. The red color represents admin entered. The black bold represent populated by the ktpass command when it creates the keytab file.
cn <servername>.<company.com>
displayName <servername>.<company.com>
distinguishedName CN=<servername>.<company.com>,OU=AIX,DC=corp,DC=<company>,DC=com
givenName <servername>.<company.com>
name <servername>.<company.com>
sAMAccountName <servername>
servicePrincipalName oracle/<servername>.<company.com>
oracle/<servername>.corp.<company.com>
userAccountControl [512] User
userPrincipalName oracle/<servername>.<company.com>@CORP.<COMPANY.COM>
The resultant file was transferred to the *nix admin for installation and config.
Unix
Make krb components available:
revise AD server exports to make /export/71 available to target server(s);
mount AD Server:/export/71 /mnt
cd /mnt/lppsource_71TL3SP6_full/installp/ppc
smitty install from current directory
Check/Install these Kerberos components:
krb5.client.rte 1.5.0.3 Network Authentication Servi…
krb5.client.samples 1.5.0.3 Network Authentication Servi…
krb5.doc.en_US.html 1.5.0.3 Network Auth Service HTML Do…
krb5.doc.en_US.pdf 1.5.0.3 Network Auth Service PDF Doc…
krb5.lic 1.5.0.3 Network Authentication Servi…
Revise kerberos entries in /etc/services:
kerberos 88/tcp kerberos5 krb5 # Kerberos v5
kerberos 88/udp kerberos5 krb5 # Kerberos v5
Oracle Database Servers
Create or add the following to the sqlnet.ora file ($ORACLE_HOME/network/admin)
SQLNET.KERBEROS5_KEYTAB=/etc/krb5/krb5.keytab
SQLNET.AUTHENTICATION_SERVICES = (BEQ,KERBEROS5PRE,KERBEROS5)
SQLNET.AUTHENTICATION_REQUIRED=TRUE
SQLNET.KERBEROS5_CONF_MIT=TRUE
SQLNET.KERBEROS5_CONF=$ORACLE_HOME/network/admin/krb5.conf
SQLNET.AUTHENTICATION_KERBEROS5_SERVICE=oracle
SQLNET.INBOUND_CONNECT_TIMEOUT=180
Update each user with the following:
alter user <username> identified externally as ‘<username>@CORP.<COMPANY.COM>’;
I hope this blog helps provide you with a one stop shop to simplify your Oracle database authentication. If you’re looking for support your Oracle databases, please reach out.
The post Kerberos Authentication with Oracle Databases appeared first on Datavail.
Machine Learning and Spatial for FREE in the Oracle Database
Last week at UKOUG Techfest19 I spoke a lot about Machine Learning both with Oracle Analytics Cloud and more in depth in the Database with Oracle Machine Learning together with Charlie Berger, Oracle Senior Director of Product Management.
As mentioned several times in my previous blog posts, Oracle Analytics Cloud provides a set of tools helping Data Analysts start their path to Data Science. If, on the other hand, we're dealing with experienced Data Scientists and huge datasets, Oracle's proposal is to move Machine Learning where the data resides with Oracle Machine Learning. OML is an ecosystem of various options to perform ML with dedicated integration with Oracle Databases or Big Data appliances.

One of the most known branches is OML4SQL which provides the ability of doing proper data science directly in the database with PL/SQL calls! During the UKOUG TechFest19 talk Charlie Berger demoed it using a collaborative Notebook on top of an Autonomous Data Warehouse Cloud.

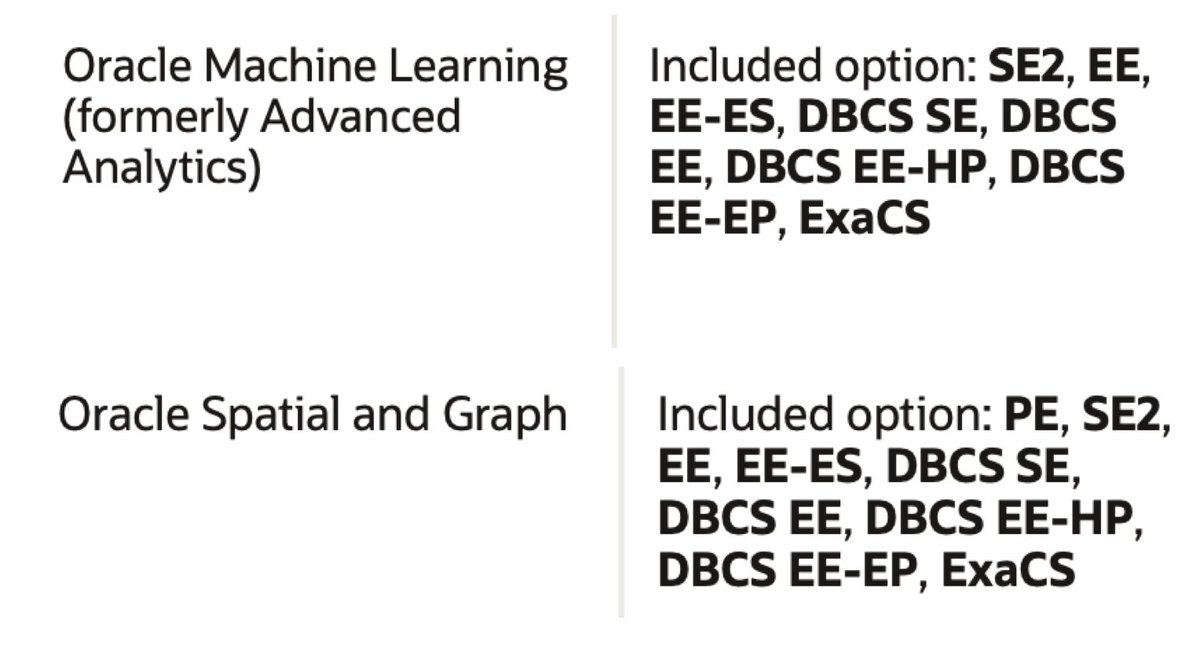
Both Oracle ADW and ATP include OML by default at no extra cost. This wasn't true for all the other database offerings in cloud or on-premises which required an additional option to be purchased (the Advanced Analytics one for on-premises deals). The separate license requirement was obviously something that limited the spread of this functionality, but, I'm happy to say that it's going away!
Oracle's blog post yesterday announced that:
As of December 5, 2019, the Machine Learning (formerly known as Advanced Analytics), Spatial and Graph features of Oracle Database may be used for development and deployment purposes with all on-prem editions and Oracle Cloud Database Services. See the Oracle Database Licensing Information Manual (pdf) for more details.
What this means is that both features are included for FREE within the Oracle Database License! Great news for both Machine Learning as well as Graph Databases fans! The following tweet from Dominic Giles (Master Product Manager for the Oracle DB) provides a nice summary of the licenses including the two options for the Oracle DB 19c.
The #Oracle Database now has some previously charged options added to the core functionality of both Enterprise Edition and Standard Edition 2. Details in the 19c licensing guide with more information to follow. pic.twitter.com/dqkRRQvWq2
— dominic_giles (@dominic_giles) December 5, 2019
But hey, this license change effects also older versions starting from the 12.2, the older one still in general support! So, no more excuses, perform Machine Learning where your data is: in the database with Oracle Machine Learning!

