Tag Archives: Oracle Data Integrator
OBIEE, Big Data Discovery, and ODI security updates – October 2016
Oracle release their "Critical Patch Update" (CPU) notices every quarter, bundling together details of vulnerabilities and associated patches across their entire product line. October's was released yesterday, with a few entries of note in the analytics & DI space.
Each vulnerability is given a unique identifier (CVE-xxxx-xxxx) and a score out of ten. The scoring uses a common industry-standard scale on the basis of how easy it is to exploit, and what is compromised (availability, data, etc). Ten is the worst, and I would crudely paraphrase it as generally meaning that someone can wander in, steal your data, change your data, and take your system offline. Lower than that and it might be that it requires extensive skills to exploit, or the impact be much lower.
A final point to note is that the security patches that are released are not available for old versions of the software. For example, if you're on OBIEE 11.1.1.6 or earlier, and it is affected by the vulnerability listed below (which I would assume it is), there is no security patch. So even if you don't want to update your version for the latest functionality, staying within support is an important thing to do and plan for. You can see the dates for OBIEE versions and when they go out of "Error Correction Support" here.
If you want more information on how Rittman Mead can help you plan, test, and carry out patching or upgrades, please do get in touch!
The vulnerabilities listed below are not a comprehensive view of an Oracle-based analytics/DI estate - things like the database itself, along with Web Logic Server, should also be checked. See the CPU itself for full details.
Big Data Discovery (BDD)
- CVE-2015-3253
- Affected versions: 1.1.1, 1.1.3, 1.2.0
- Base score: 9.8
- Action: upgrade to the latest version, 1.3.2. Note that the upgrade packages are on Oracle Software Delivery Cloud (née eDelivery)
OBIEE
- CVE-2016-2107
- Affected versions: 11.1.1.7.0, 11.1.1.9.0, 12.1.1.0.0, 12.2.1.1.0
- Base score: 5.9
- Action: apply bundle patch 161018 for your particular version (see MoS doc 2171485.1 for details)
BI Publisher
- CVE-2016-3473
- Affected versions: 11.1.1.7.0, 11.1.1.9.0, 12.2.1.0.0
- Base score 7.7
- Action: apply patch per MoS doc 2171485.1
ODI
-
- Affected versions: 11.1.1.7.0, 11.1.1.9.0, 12.1.3.0.0, 12.2.1.0.0, 12.2.1.1.0
- Base score: 5.7
- The
getInfo()ODI API could be used to expose passwords for data server connections. - More details in MoS doc 2188855.1
-
- Affected versions: 11.1.1.7.0, 11.1.1.9.0, 12.1.2.0.0, 12.1.3.0.0, 12.2.1.0.0, 12.2.1.1.0
- Base score: 3.1
- This vulnerability documents the potential that a developer could take the master repository schema credentials and use them to grant themselves SUPERVISOR access. Even using the secure wallet, the credentials are deobfuscated on the local machine and therefore a malicious developer could still access the credentials in theory.
- More details in MoS doc 2188871.1
Oracle Data Integrator 12c: Getting Started – Components and Architecture
I’ve decided that it’s time for a refresher on Oracle Data Integrator 12c. I’m writing a Getting Started series to help folks get interested in the product and maybe even teach a few old dogs (including myself) some new tricks. In my last post, I shared the history of ODI and a bit about what sets it apart from other ETL tools on the market. In this article, I’ll walk through different components of Oracle Data Integrator and some of the architecture choices you’ll need to make in order to get started with ODI 12c.
Components
Before diving into the architecture, we need to understand the different components that are part of the Oracle Data Integrator installation.
Repositories
ODI is driven by metadata. This metadata is stored away in two different repositories: the Master repository and the Work repository. The Master repository contains information about security (users, profiles, etc), topology (data connections, contexts, physical/logical schemas), and ODI versioning. Each Master repository can be linked to one or more Work repositories. Work repositories can be of 2 different types: development or execution. In a Development Work repository you’ll find all of the design objects (mappings, packages, procedures, etc) and datastore metadata. The Execution Work repository only stores the execution objects, Scenarios and Load Plans, and there is no development capability. More on all of these objects in a later post.
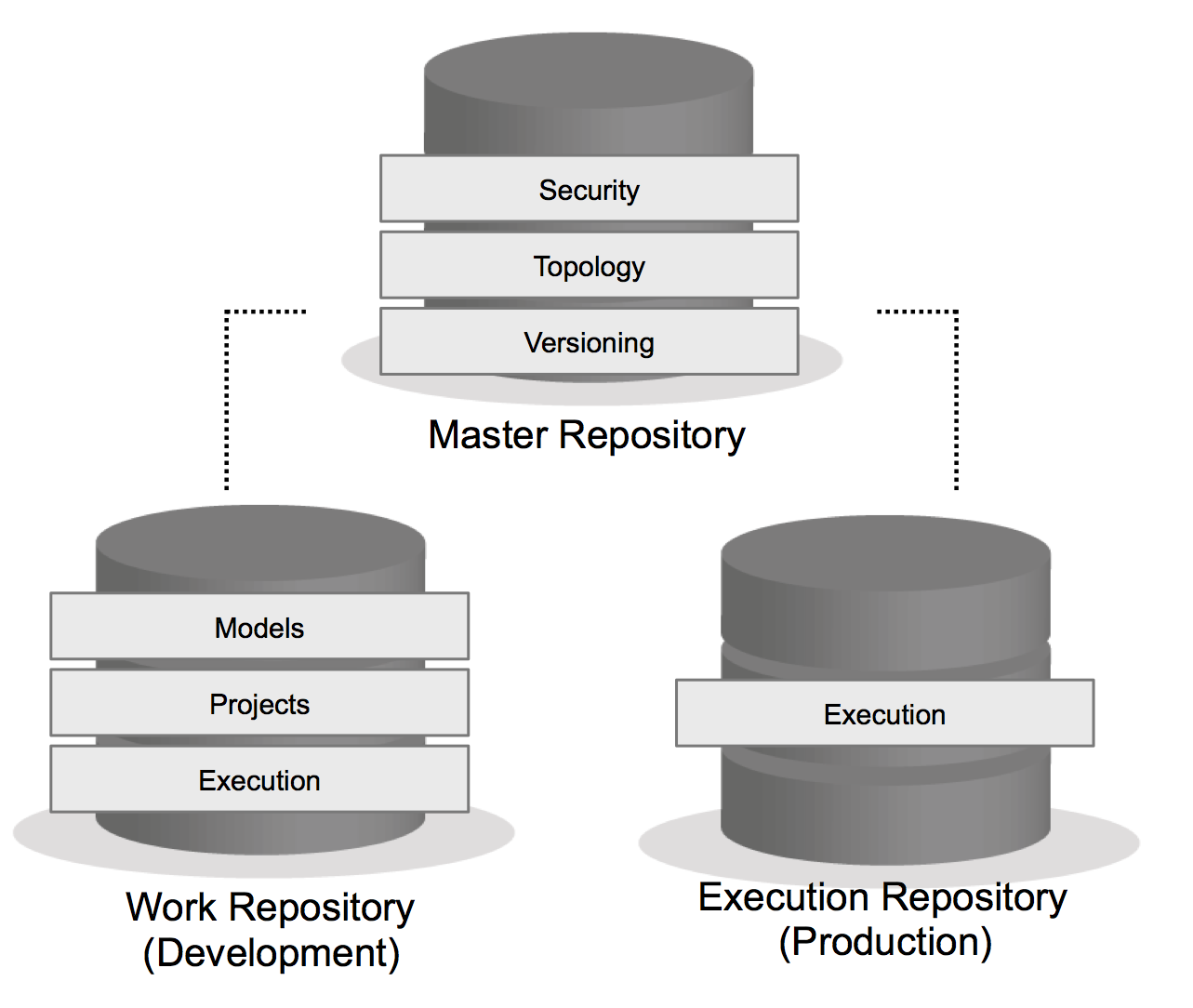
The Master and Work repositories can reside in the same database schema or as their own schemas in the same database instance. The latter practice was more common in the past, before the Repository Creation Utility (RCU) was really the main mechanism for creating the repositories. The RCU doesn’t provide an option for separating the repositories into two different schemas, therefore the standard is to use one single schema. But that’s not the only reason, it also stems from the best practice of separating your environments in entirety; development, test, production, so each can be maintained, upgraded, and patch separately. We’ll jump into the environment setup further down.
Agents
The Oracle Data Integrator Agent is what orchestrates the execution of processes created in ODI. At runtime, agents will be used to run Load Plans and Scenarios via an ODI schedule, command line call, web service call, or a third-party scheduler. Agents are accessed via http/https requests, regardless of how they are called into action.
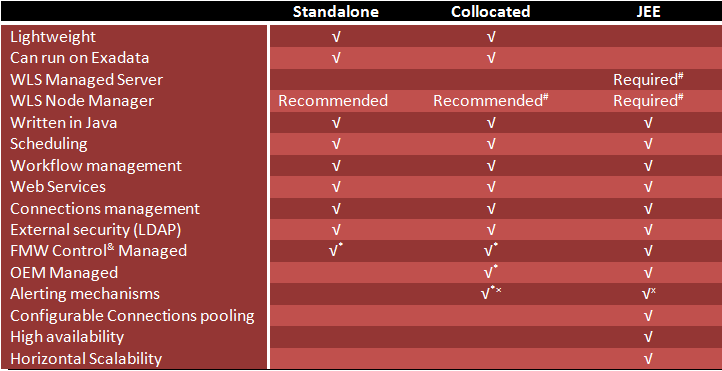
There are 3 types ODI 12c of agents:
- JEE Agent
Implemented as a deployment in Weblogic Server 12c, the JEE Agent allows you to use the features of WLS, such as clustering for high availability and JDBC connection pooling. - Standalone Agent
The Standalone Agent is a lightweight Java application that is typically installed to run closest to where most of the transformations will occur. In most data warehouse setups, this is on the data warehouse server. - Colocated Agent
This type of agent is essentially a Standalone Agent that is managed via Weblogic Server. If you want to manage all of your agents via WLS, this is the way to go.
A great article from the ODI A-Team, ODI Agents: Standalone, JEE and Colocated, describes the agent types in further detail, including the comparison of agent features chart, found below.
Studio
ODI Studio is a Java based development environment based on the JDeveloper framework. Studio is installed on client machines and used to connect to the master and work repositories to access the ODI metadata and perform object development. Essentially, this is where the magic happens!
Architecture - It Depends.
With any good question comes the answer, “it depends”. Before we can choose an architecture for ODI, the system requirements must be determined, allowing us to work through the “it depends” answer more clearly. Let’s dive right in with some potential requirements that may be necessary for a proper data integration setup.
High Availability
A key decision that drives which components of Oracle Data Integrator will be installed and configured stems from the need for a highly available ETL process. If there is a critical process or reporting that relies on ODI, then HA will be a requirement. Not only that, but you’ll want to look at using something like Oracle RAC for the repository database in order to keep it up and running. Finally, high availability won’t save you from an entire data center going offline, so ensure you have a disaster recovery process in place as well.
Environments Required
How many environments do you need? Let’s start with the minimum, Development, Test/QA, and Production. Ok, well if you’re a small shop you might be able to get away without Test/QA, but not recommended. I would also add a 4th environment, Hotfix, which will store the production development objects, allowing your team to fix a production issue quickly without having to restore code from source control. The purpose of understanding the number of environments upfront is to determine how many application servers and database servers will be required for the entire Oracle Data Integrator setup. There’s yet another great article from the Oracle A-Team that describes the use of the ODI Master Repository across these many environments.
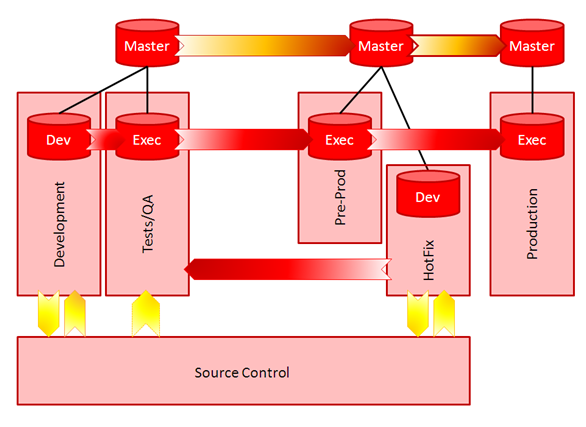
Lifecycle Management and Deployment Process
As you can see in the environments image above, there are also different arrows showing the deployment process and use of source control. The deployment process is usually the easy part to determine: Migrate ODI execution objects from Dev—>Test—>Prod. But the mechanism for doing so might be a bit different, especially if (or more likely, when) source control is introduced.
Oracle Data Integrator 12c can integrate with Subversion, and soon Git, for full lifecycle management capabilities. ODI also has its own object versioning, but it really is only to be used as a last resort. Often, teams have developed their own process around exporting objects to XML, loading into a source control system, and migrating to the next environment. Whichever process you determine is best for your organization, or if you plan to piggy-back on what’s currently in play for developers at your company, you’ll want to ensure the correct components are introduced into the architecture.
Sources and Targets
This is about the types and location of the data sources that ODI will need to connect to. If you have a set of flat files on a server that is unreachable from the machine where the ODI agent is installed, you’ll need a new Standalone agent placed somewhere that can pull from the file server. Drawing up the entire “planned” data flow will help to sort out these decisions early on, especially if you introduce big data into the mix.
Security
Finally, everyone’s favorite topic: security. There are many aspects to security within ODI, including how developers access ODI Studio and how to secure your ETL processes and the application itself. As mentioned earlier, the ODI Agents are called via a web request. The addition of SSL can further secure transmission of these requests, but may also introduce additional setup. If you have a large team of ETL developers, or maybe just a company policy on how applications are to be accessed, ODI can be integrated with your organization’s LDAP via the external authentication setup. With these and other considerations for ODI security, be sure to sort this out during the requirements and architecture phase.
There are many other questions that will need to be answered in order to properly choose your architecture, but hopefully this will get you started. As always, you can join one of the Rittman Mead ODI bootcamps to learn more from one of our experts on the product. Up next in the Getting Started series, we’ll look at Oracle Data Integrator installation and configuration.
OTN Appreciation Day: Oracle Data Integrator 12c – Flexibility
As you may already know by now, it’s OTN Appreciation Day! The idea was thought up by Oracle ACE Director Tim Hall to give thanks to the Oracle Technical Network that we all love and use on a daily basis (see #ThanksOTN on Twitter).
The focus for these blog posts is not only to give thanks to OTN, but also to generate some interesting conversation around different features of various Oracle products. One of my favorite features of Oracle Data Integrator 12c is its flexibility. This isn’t necessarily a single feature of the product, but more of an overall assessment of ODI as a whole. Let me breakdown a few of the features that make ODI flexible and easy to adapt. Note: I actually mentioned a couple of these in my previous blog post, “Oracle Data Integrator 12c: Getting Started - What is ODI?”, but why not point them out again?
Knowledge Modules
The typical main goal of Oracle Data Integrator is to develop mappings that use on or more source datastores to load one or more target datastores. These mappings can have many different components that join, filter, aggregate or transform the data before it reaches its final destination. Logically, this is completed in ODI by dragging lines between boxes and configuring properties for each component.
The physical implementation of a mapping is set to use one or more Knowledge Modules to generate the code or objects required for specific loading and integration types. These KMs are code templates that use the ODI Substitution API to fill in the mapping metadata based on the logical implementation. The great part is that these KMs can be easily customized and modified to fit your data integration needs! Your environment doesn’t have to conform to the tool, you get to make the tool conform to your environment.
"But wait!", says the current ODI developers. “We can’t modify Component Knowledge Modules.” Yes, that’s a true statement. The current ODI 12c version has two types of KMs: Template and Component. The former have been in the product since inception and are easily customizable while the latter are more of a black box. But, as announced at Oracle OpenWorld last month, a brand new, highly extensible Knowledge Module framework, and the ability to edit all KMs, is coming soon!
Procedures
If Knowledge Module customization doesn’t give you the flexibility necessary to perform specific actions in your data integration project, we also have ODI Procedures. These objects are used to execute a specific set of code for any sort of task. With so many different technologies accessible via ODI, you can write nearly any bit of code to execute. Procedures are often used for exception handling, file processing, and all types of scripting via Jython or Groovy. These objects just add to the ultimate flexibility of Oracle Data Integrator.
Java API
Last, but definitely not least, we have the ODI SDK Java API. Using the SDK, we can perform nearly every action that can be completed via ODI Studio. That’s a huge amount of flexibility! Now if there is a batch creation of objects or change necessary, I can write a few lines of Groovy code, execute the script, and it’s all completed in seconds rather than days of manual work. Take a look at a couple of examples I’ve posted in the past, adding columns to a set of ODI Datastores and creating Interfaces (in ODI 11g) based on a SQL query. Any chance I get I try to use the ODI SDK to make my development life just that much easier.
There you have it, my favorite feature of Oracle Data Integrator 12c - flexibility. I hope you all have a great OTN Appreciation Day and thanks for reading! And of course, #ThanksOTN!
Oracle Data Integrator 12c: Getting Started – What is ODI?
There is something about sharing stories with others about the technology you love that gets the blood flowing. I have written blog posts and articles, presented sessions at conferences, and recorded podcasts and tech tips about Oracle Data Integrator over the years. And it’s been a blast! But one thing I find is that I’m always drawn to sharing the difficult or overly technical aspects of ODI, often writing about integration with GoldenGate or strange quirks in the product that I’ve had to overcome for my clients. In a sense, that’s why you’re reading, right? The Rittman Mead blog has always been about solving the difficult problems with Oracle technologies and sharing that knowledge in a simple and easy to understand format. But what about a true “getting started” type of article?
I think it’s time for a refresher on Oracle Data Integrator. What is ODI? How has it evolved over the years and where is it going? And, of course, how do you get started with Oracle Data Integrator? I plan to share what I love about ODI and hope to get some folks interested in this great product as well. If you want to learn even more, I’d love to have you join me or one of my colleagues at one of our ODI 12c bootcamps. We’ll dig deep into the details and answer all of your questions about data integration. But until then, let’s get started with a little about where Oracle Data Integrator came from.
History of ODI
Oracle Data Integrator was the product of an acquisition that Oracle made in late 2006. Back then, Oracle already had a data integration tool for developing ETL (Extract, Transform, and Load) mappings, Oracle Warehouse Builder (OWB). At the time, OWB was delivered with the Oracle Database license, which made it the go-to data warehouse development tool for Oracle developers. In October of 2006, Oracle announced that they had acquired a French data integration company called Sunopsis who focused their product on E-LT (Extract, Load, Transform) rather than the traditional ETL.
What did that mean for OWB? The “standard” (and free with the Oracle DB) ETL development platform for Oracle was now in competition with a new product, Oracle Data Integrator. ODI was a separate license cost and resided in the Fusion Middleware stack, outside of the database. As you might imagine, OWB’s days were numbered. With the possibility to sell additional software licenses and the uprising of Fusion Middleware and Fusion Applications (of which ODI was a big part of), eventually Warehouse Builder was to be merged with Data Integrator.
The data integration product from Sunopsis became Oracle Data Integrator 10g after the acquisition. In August 2010, Oracle made their first updates to ODI with the release of Oracle Data Integrator 11g. This version moved ODI into the framework utilized by other products such as Oracle SQL Developer and JDeveloper, and introduced new features such as the JEE Agent and the ODI Console. While the 11g version was a step up from ODI 10g, it was still not widely regarded as a typical ETL development tool. The concept of Interfaces being a single unit of work for ETL versus the usual flow-based mapping approach found in most ETL tools, including OWB, led to a slower adoption rate. It took several years, but finally Oracle Data Integrator went flow-based with the release of ODI 12c, integrating some of the best features from Oracle Warehouse Builder into the current ODI product. In late 2013, the initial version of ODI 12c was made available to the public. Besides the switch to flow-based mappings, ODI 12c has also included integration with big data sources and targets, lifecycle management capabilities, many performance enhancements, and a migration utility for those moving from OWB.
Now that we’re caught up with that brief history lesson, let’s look at how ODI is able to differentiate itself from competitors.
What Makes ODI Different?
E-LT
I alluded to Oracle Data Integrator’s use of ELT (Extract, Load, and Transform) earlier, but what does that mean - and why are the letters in the acronym ETL out of order? The main difference is in the architecture.
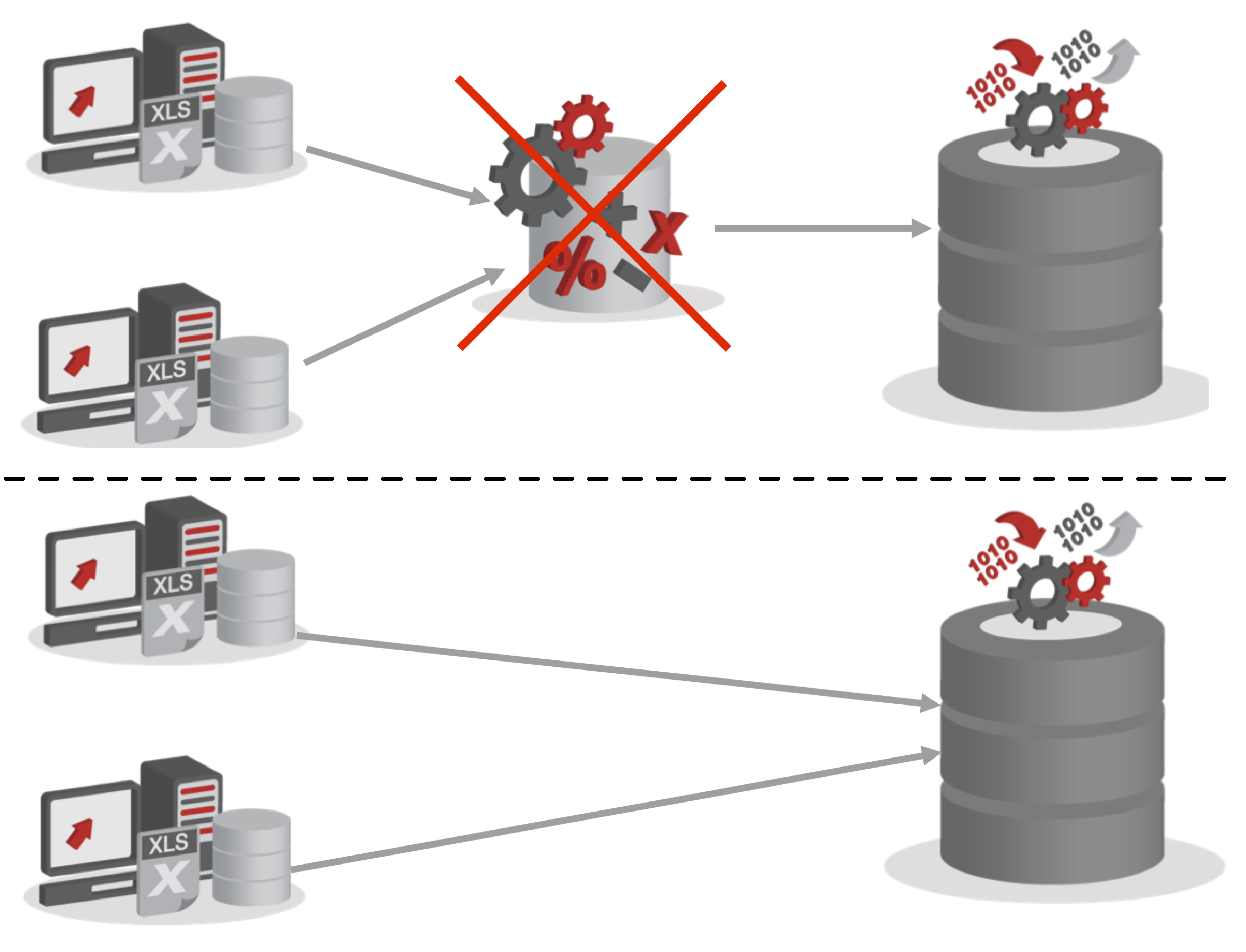
Oracle Data Integrator is built to pushdown the transformation work to the source or target datasource. This means there is no need for a middle tier ETL engine to perform transformations, as many of the traditional ETL tools employ. In fact, in most implementations the ODI agent, which performs orchestration of the ETL processes, simply sends the code to the target server to be executed. This architecture allows ODI to use the power of the target datasource to execute the transformations. Why waste the processing power of your Oracle Database when it’s built for this type of SQL execution?
Knowledge Modules
The concept behind Knowledge Modules (KMs) is quite simple. In a nutshell, KMs are generic code templates that are applied to an ODI mapping and use a substitution language to input metadata from within the mapping to produce executable code at runtime. If you want to change the physical implementation of your mapping, say switching from an insert-only “append” integration method to an incremental update approach, you can simply switch the Knowledge Module applied to that particular mapping. KMs can even be customized or created from scratch to suit your specific data integration needs, adding to the overall flexibility of the tool.
Customization and Flexibility
The Knowledge Modules are just one aspect of Oracle Data Integrator that can be customized. With KMs, you can change how your mappings are physically implemented allowing for the ultimate flexibility. But it’s not just mappings, an object called a Procedure in ODI will allow any bit of code or command line call to be made using nearly any type of technology: Groovy, Jython, OS commands, Oracle SQL, MySQL, SQL Server…the list goes on and on. The great part about customizing Oracle Data Integrator is that you can make it adapt to your data warehouse - and not the other way around. Too often companies must adopt a “standard” because it is built into the software they use rather than a good business practice. Thankfully, that’s not the case with ODI.
Beyond customization within the Oracle Data Integrator objects, you can also access the application backend via the ODI SDK Java API. With this level of access, you can perform almost every task that can be completed within ODI Studio. Imagine, you need to create 400 source to staging mappings, all one-for-one column mappings. With the ODI SDK, and less than 50 lines of code, you can create them all in about 5 seconds! The power of the SDK is generally found when there is a need for a batch creation or modification of objects. But it’s not only those cases where the SDK shines, you can also perform actions such as automation of code deployment or even create a development quickstart for your standard mappings, all with custom code building ODI objects.
As you might have noticed, I’m a big fan of Oracle Data Integrator 12c. This is just the first of many in the “Oracle Data Integrator 12c: Getting Started” series. Up next, we’ll really look at how to go about getting started with ODI 12c. As always, please feel free to send me an email or message on twitter - or comment below - if you have any questions. And if I missed your favorite feature of Oracle Data Integrator, please share in the comments!
Becky’s BI Apps Corner: OBIA Back-to-Beginnings – Naming Conventions and Jargon
It's easy to talk about a technology using only jargon. It's much harder to talk about a technology without using jargon. I have seen many meetings between business and IT break down because of this communication barrier. I find it more discouraging when I see this communication breakdown happen between advanced IT staff and new IT staff. For those of us in any technological field, it's easy to forget how long it took to learn all of the ins and outs, the terminology and jargon.
During a recent project, I had another consultant shadowing me to get experience with OBIA. (Hi, Julia!) I was 'lettering' a lot so I decided it was time to diagram my jargon. My scribbles on a whiteboard gave me the idea that it might be helpful to do a bit of connecting the dots between OBIA and data warehousing jargon and naming conventions used in OBIA.
BI Applications Load Plan phases:
SDE - Source Dependent Extract
SDE is the first phase in the ETL process that loads source data into the staging area. SDE tasks are source database specific. SDE mappings that run in the load plan will load staging tables. These tables end with _DS and _FS among others.
SIL - Source Independent Load
SIL is the second phase in the ETL process that takes the staged data from the staging tables and loads or transforms them into the target tables. SILOS mappings that run in the load plan will load dimension and fact tables. These tables end with _D and _F among others.
PLP - Post Load Process
This third and final phase in the ETL process occurs after the target tables have been loaded and is commonly used for loading aggregate fact tables. PLP mappings that run in the load plan will load aggregate tables ending with _A. Aggregate tables are often fact table data that has been summed up by a common dimension. For example, a common report might look at finance data by the month. Using the aggregate tables by fiscal period would help improve reporting response time.
For further information about any of the other table types, be sure to read Table Types for Oracle Business Analytics Warehouse. Additionally, this page has probably the best explanation for staging tables and incremental loads.
Source System Acronyms
Since the SDE tasks are source database specific, the SDE mappings' names also include an acronym for the source system in the mapping name. Below are the supported source database systems and the acronyms used in the names and an example for each.
Oracle E-Business Suite - ORA
SDE_ORA_DomainGeneral_Currency
Oracle Siebel - SBL
SDE_SBL_DOMAINGENERAL_CURRENCY
JD Edwards Enterprise One - JDEE
SDE_JDE_DomainGeneral_Currency
PeopleSoft - PSFT
SDE_PSFT_DomainGeneral_Currency_FINSCM
Oracle Fusion Applications - FUSION
SDE_FUSION_DomainGeneral_Currency
Taleo - TLO
SDE_TLO_DomainGeneral_Country
Oracle Service Cloud - RNCX
SDE_RNCX_DomainGeneral
Universal - Universal
SDE_Universal_DomainGeneral
This wraps up our quick "Back-to-Beginnings" refresher on naming conventions and the jargon used in relation to ETL and mappings. Let me know in the comments below if there are other topics you would like me to cover in my "Back-to-Beginnings" series. As always, be sure to check out our available training, which now includes remote training options, and our On Demand Training Beta Program. For my next post I'll be covering two new features in OBIA 11.1.1.10.2, Health Check and ETL Diagnostics, which are the missing pieces you didn't know you've been waiting for.

